 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Encoded Observation Spaces for Perceptive Reinforcement Learning
Paper and Code



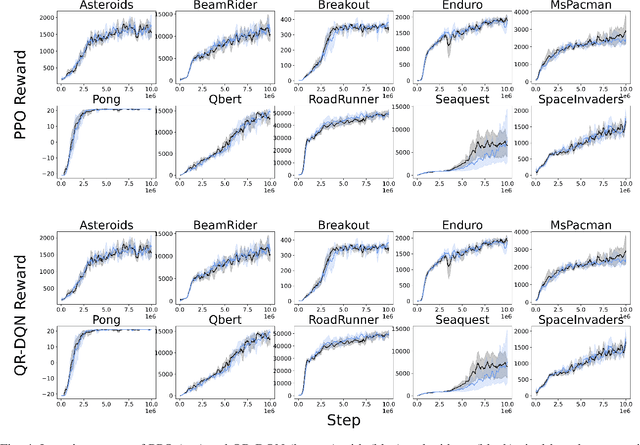
Perceptive deep reinforcement learning (DRL) has lead to many recent breakthroughs for complex AI systems leveraging image-based input data. Applications of these results range from super-human level video game agents to dexterous, physically intelligent robots. However, training these perceptive DRL-enabled systems remains incredibly compute and memory intensive, often requiring huge training datasets and large experience replay buffers. This poses a challenge for the next generation of field robots that will need to be able to learn on the edge in order to adapt to their environments. In this paper, we begin to address this issue through differentially encoded observation spaces. By reinterpreting stored image-based observations as a video, we leverage lossless differential video encoding schemes to compress the replay buffer without impacting training performance. We evaluate our approach with three state-of-the-art DRL algorithms and find that differential image encoding reduces the memory footprint by as much as 14.2x and 16.7x across tasks from the Atari 2600 benchmark and the DeepMind Control Suite (DMC) respectively. These savings also enable large-scale perceptive DRL that previously required paging between flash and RAM to be run entirely in RAM, improving the latency of DMC tasks by as much as 32%.