 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Magnificent Seven Challenges and Opportunities in Domain-Specific Accelerator Design for Autonomous Systems
Jul 24, 2024
The end of Moore's Law and Dennard Scaling has combined with advances in agile hardware design to foster a golden age of domain-specific acceleration. However, this new frontier of computing opportunities is not without pitfalls. As computer architects approach unfamiliar domains, we have seen common themes emerge in the challenges that can hinder progress in the development of useful acceleration. In this work, we present the Magnificent Seven Challenges in domain-specific accelerator design that can guide adventurous architects to contribute meaningfully to novel application domains. Although these challenges appear across domains ranging from ML to genomics, we examine them through the lens of autonomous systems as a motivating example in this work. To that end, we identify opportunities for the path forward in a successful domain-specific accelerator design from these challenges.
RobotPerf: An Open-Source, Vendor-Agnostic, Benchmarking Suite for Evaluating Robotics Computing System Performance
Sep 17, 2023
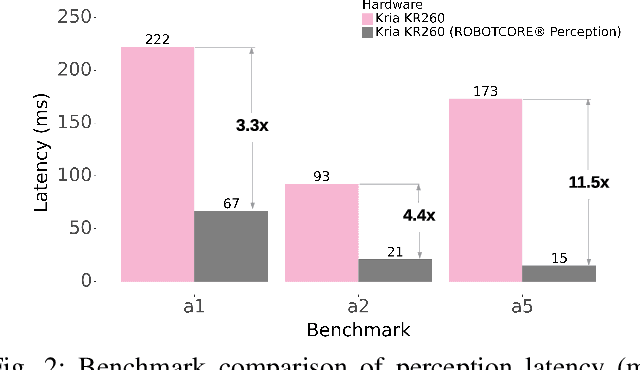

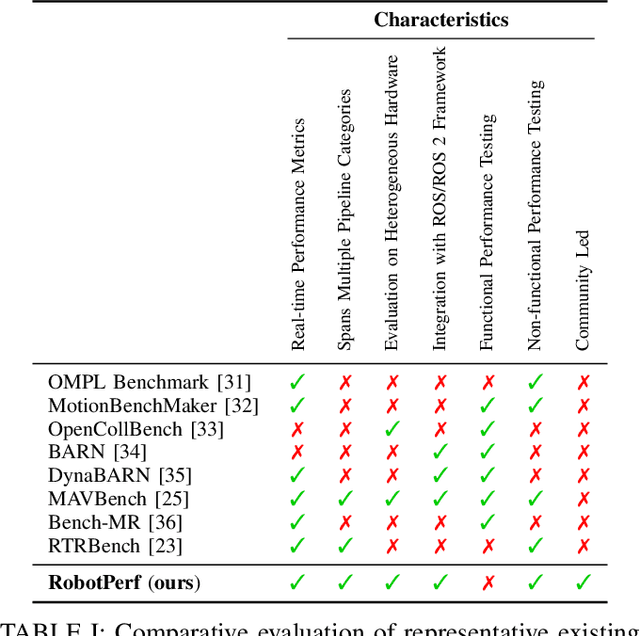
We introduce RobotPerf, a vendor-agnostic benchmarking suite designed to evaluate robotics computing performance across a diverse range of hardware platforms using ROS 2 as its common baseline. The suite encompasses ROS 2 packages covering the full robotics pipeline and integrates two distinct benchmarking approaches: black-box testing, which measures performance by eliminating upper layers and replacing them with a test application, and grey-box testing, an application-specific measure that observes internal system states with minimal interference. Our benchmarking framework provides ready-to-use tools and is easily adaptable for the assessment of custom ROS 2 computational graphs. Drawing from the knowledge of leading robot architects and system architecture experts, RobotPerf establishes a standardized approach to robotics benchmarking. As an open-source initiative, RobotPerf remains committed to evolving with community input to advance the future of hardware-accelerated robotics.
Tiny Robot Learning: Challenges and Directions for Machine Learning in Resource-Constrained Robots
May 11, 2022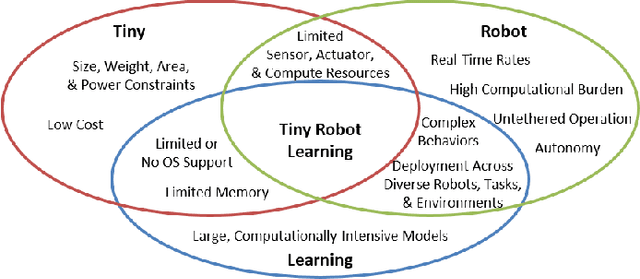
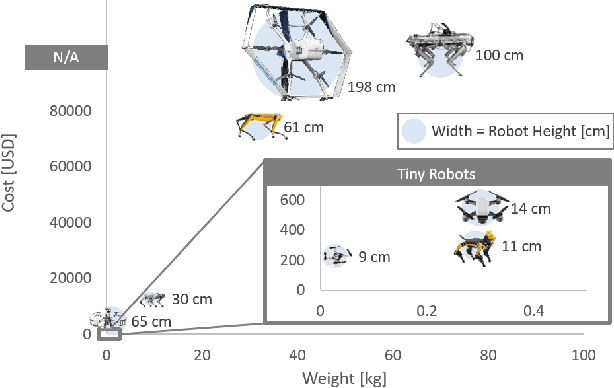
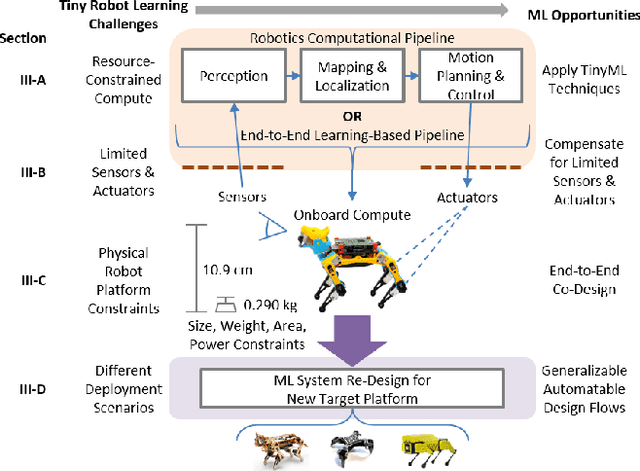
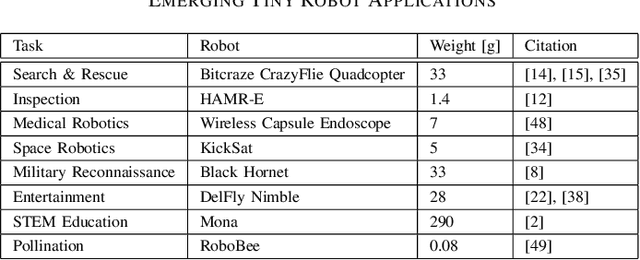
Machine learning (ML) has become a pervasive tool across computing systems. An emerging application that stress-tests the challenges of ML system design is tiny robot learning, the deployment of ML on resource-constrained low-cost autonomous robots. Tiny robot learning lies at the intersection of embedded systems, robotics, and ML, compounding the challenges of these domains. Tiny robot learning is subject to challenges from size, weight, area, and power (SWAP) constraints; sensor, actuator, and compute hardware limitations; end-to-end system tradeoffs; and a large diversity of possible deployment scenarios. Tiny robot learning requires ML models to be designed with these challenges in mind, providing a crucible that reveals the necessity of holistic ML system design and automated end-to-end design tools for agile development. This paper gives a brief survey of the tiny robot learning space, elaborates on key challenges, and proposes promising opportunities for future work in ML system design.
RobotCore: An Open Architecture for Hardware Acceleration in ROS 2
May 08, 2022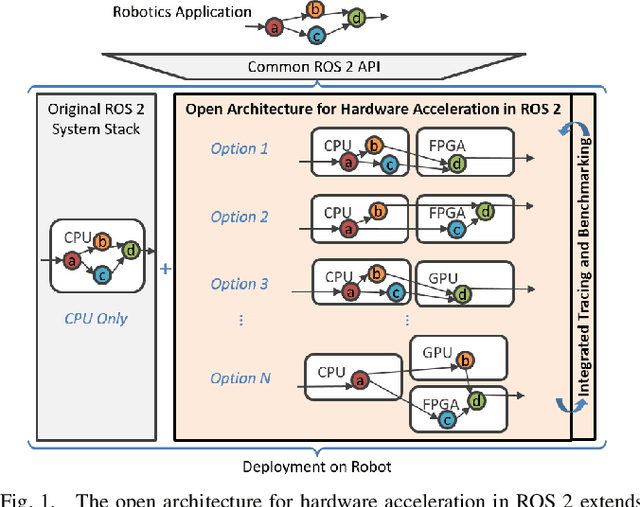
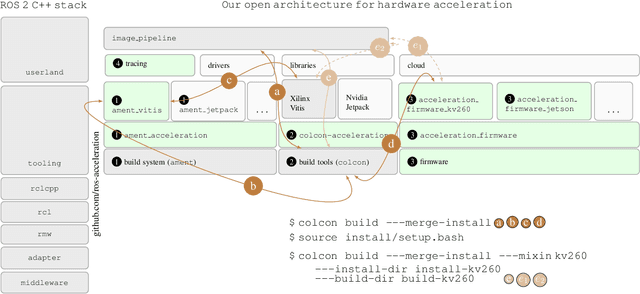
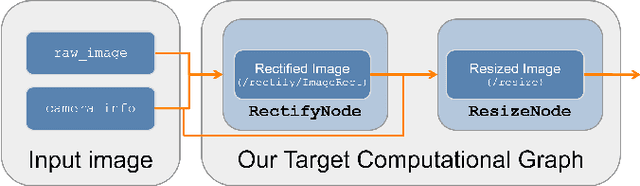
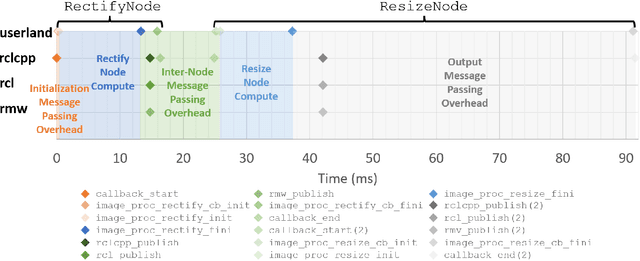
Hardware acceleration can revolutionize robotics, enabling new applications by speeding up robot response times while remaining power-efficient. However, the diversity of acceleration options makes it difficult for roboticists to easily deploy accelerated systems without expertise in each specific hardware platform. In this work, we address this challenge with RobotCore, an architecture to integrate hardware acceleration in the widely-used ROS 2 robotics software framework. This architecture is target-agnostic (supports edge, workstation, data center, or cloud targets) and accelerator-agnostic (supports both FPGAs and GPUs). It builds on top of the common ROS 2 build system and tools and is easily portable across different research and commercial solutions through a new firmware layer. We also leverage the Linux Tracing Toolkit next generation (LTTng) for low-overhead real-time tracing and benchmarking. To demonstrate the acceleration enabled by this architecture, we use it to deploy a ROS 2 perception computational graph on a CPU and FPGA. We employ our integrated tracing and benchmarking to analyze bottlenecks, uncovering insights that guide us to improve FPGA communication efficiency. In particular, we design an intra-FPGA ROS 2 node communication queue to enable faster data flows, and use it in conjunction with FPGA-accelerated nodes to achieve a 24.42% speedup over a CPU.
GRiD: GPU-Accelerated Rigid Body Dynamics with Analytical Gradients
Sep 14, 2021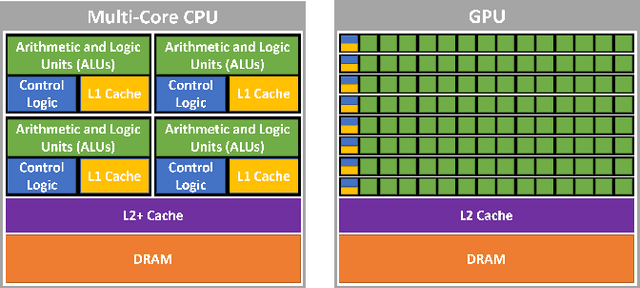
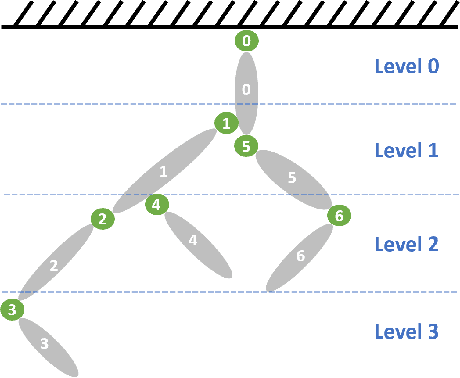
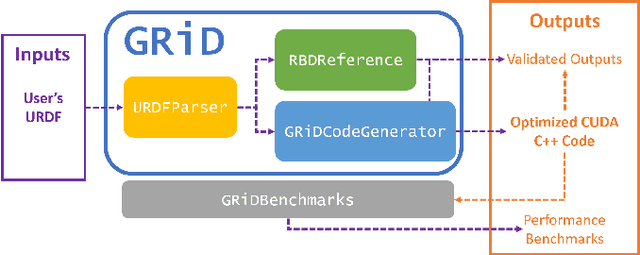
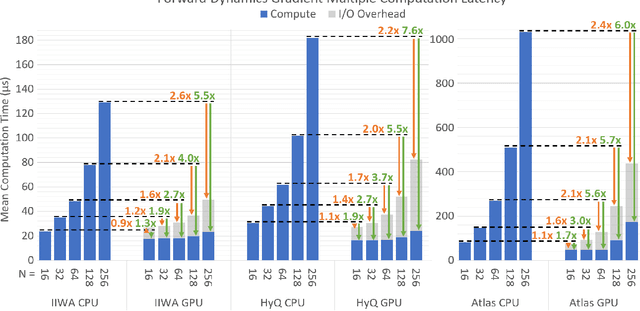
We introduce GRiD: a GPU-accelerated library for computing rigid body dynamics with analytical gradients. GRiD was designed to accelerate the nonlinear trajectory optimization subproblem used in state-of-the-art robotic planning, control, and machine learning. Each iteration of nonlinear trajectory optimization requires tens to hundreds of naturally parallel computations of rigid body dynamics and their gradients. GRiD leverages URDF parsing and code generation to deliver optimized dynamics kernels that not only expose GPU-friendly computational patterns, but also take advantage of both fine-grained parallelism within each computation and coarse-grained parallelism between computations. Through this approach, when performing multiple computations of rigid body dynamics algorithms, GRiD provides as much as a 7.6x speedup over a state-of-the-art, multi-threaded CPU implementation, and maintains as much as a 2.6x speedup when accounting for I/O overhead. We release GRiD as an open-source library, so that it can be leveraged by the robotics community to easily and efficiently accelerate rigid body dynamics on the GPU.