 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifetime-Aware Design of Item-Level Intelligence
Sep 09, 2025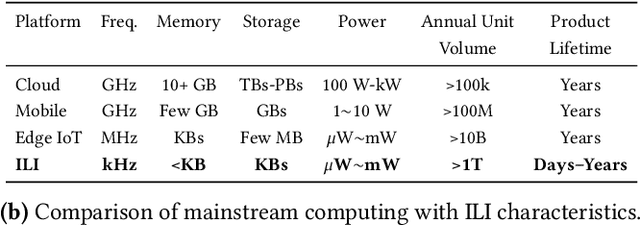


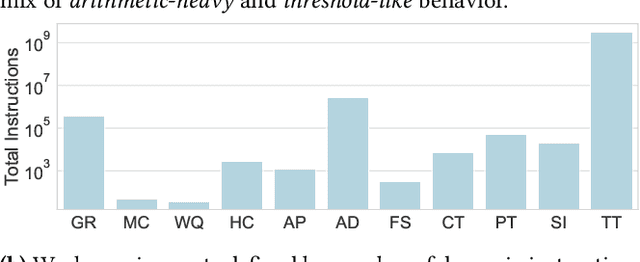
We present FlexiFlow, a lifetime-aware design framework for item-level intelligence (ILI) where computation is integrated directly into disposable products like food packaging and medical patches. Our framework leverages natively flexible electronics which offer significantly lower costs than silicon but are limited to kHz speeds and several thousands of gates. Our insight is that unlike traditional computing with more uniform deployment patterns, ILI applications exhibit 1000X variation in operational lifetime, fundamentally changing optimal architectural design decisions when considering trillion-item deployment scales. To enable holistic design and optimization, we model the trade-offs between embodied carbon footprint and operational carbon footprint based on application-specific lifetimes. The framework includes: (1) FlexiBench, a workload suite targeting sustainability applications from spoilage detection to health monitoring; (2) FlexiBits, area-optimized RISC-V cores with 1/4/8-bit datapaths achieving 2.65X to 3.50X better energy efficiency per workload execution; and (3) a carbon-aware model that selects optimal architectures based on deployment characteristics. We show that lifetime-aware microarchitectural design can reduce carbon footprint by 1.62X, while algorithmic decisions can reduce carbon footprint by 14.5X. We validate our approach through the first tape-out using a PDK for flexible electronics with fully open-source tools, achieving 30.9kHz operation. FlexiFlow enables exploration of computing at the Extreme Edge where conventional design methodologies must be reevaluated to account for new constraints and considerations.
QuArch: A Question-Answering Dataset for AI Agents in Computer Architecture
Jan 06, 2025



We introduce QuArch, a dataset of 1500 human-validated question-answer pairs designed to evaluate and enhance language models' understanding of computer architecture. The dataset covers areas including processor design, memory systems, and performance optimization. Our analysis highlights a significant performance gap: the best closed-source model achieves 84% accuracy, while the top small open-source model reaches 72%. We observe notable struggles in memory systems, interconnection networks, and benchmarking. Fine-tuning with QuArch improves small model accuracy by up to 8%, establishing a foundation for advancing AI-driven computer architecture research. The dataset and leaderboard are at https://harvard-edge.github.io/QuArch/.
ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design
Jun 15, 2023Machine learning is a prevalent approach to tame the complexity of design space exploration for domain-specific architectures. Using ML for design space exploration poses challenges. First, it's not straightforward to identify the suitable algorithm from an increasing pool of ML methods. Second, assessing the trade-offs between performance and sample efficiency across these methods is inconclusive. Finally, lack of a holistic framework for fair, reproducible, and objective comparison across these methods hinders progress of adopting ML-aided architecture design space exploration and impedes creating repeatable artifacts. To mitigate these challenges, we introduce ArchGym, an open-source gym and easy-to-extend framework that connects diverse search algorithms to architecture simulators. To demonstrate utility, we evaluate ArchGym across multiple vanilla and domain-specific search algorithms in designing custom memory controller, deep neural network accelerators, and custom SoC for AR/VR workloads, encompassing over 21K experiments. Results suggest that with unlimited samples, ML algorithms are equally favorable to meet user-defined target specification if hyperparameters are tuned; no solution is necessarily better than another (e.g., reinforcement learning vs. Bayesian methods). We coin the term hyperparameter lottery to describe the chance for a search algorithm to find an optimal design provided meticulously selected hyperparameters. The ease of data collection and aggregation in ArchGym facilitates research in ML-aided architecture design space exploration. As a case study, we show this advantage by developing a proxy cost model with an RMSE of 0.61% that offers a 2,000-fold reduction in simulation time. Code and data for ArchGym is available at https://bit.ly/ArchGym.
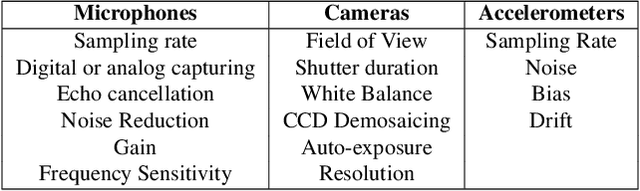
Datasheets for Machine Learning Sensors
Jun 15, 2023Machine learning (ML) sensors offer a new paradigm for sensing that enables intelligence at the edge while empowering end-users with greater control of their data. As these ML sensors play a crucial role in the development of intelligent devices, clear documentation of their specifications, functionalities, and limitations is pivotal. This paper introduces a standard datasheet template for ML sensors and discusses its essential components including: the system's hardware, ML model and dataset attributes, end-to-end performance metrics, and environmental impact. We provide an example datasheet for our own ML sensor and discuss each section in detail. We highlight how these datasheets can facilitate better understanding and utilization of sensor data in ML applications, and we provide objective measures upon which system performance can be evaluated and compared. Together, ML sensors and their datasheets provide greater privacy, security, transparency, explainability, auditability, and user-friendliness for ML-enabled embedded systems. We conclude by emphasizing the need for standardization of datasheets across the broader ML community to ensure the responsible and effective use of sensor data.
Is TinyML Sustainable? Assessing the Environmental Impacts of Machine Learning on Microcontrollers
Jan 27, 2023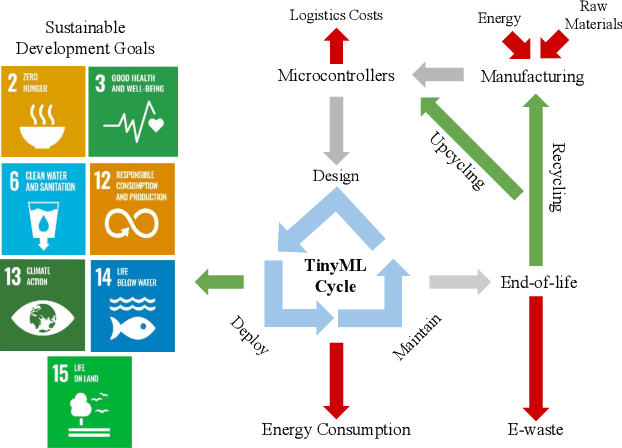
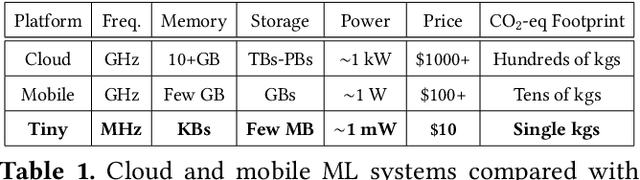
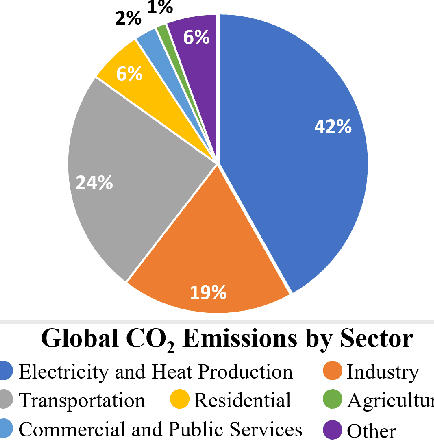
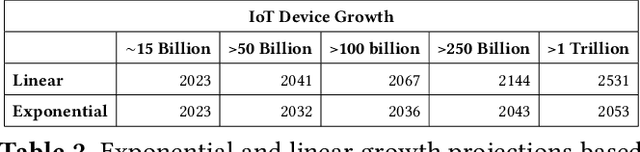
The sustained growth of carbon emissions and global waste elicits significant sustainability concerns for our environment's future. The growing Internet of Things (IoT) has the potential to exacerbate this issue. However, an emerging area known as Tiny Machine Learning (TinyML) has the opportunity to help address these environmental challenges through sustainable computing practices. TinyML, the deployment of machine learning (ML) algorithms onto low-cost, low-power microcontroller systems, enables on-device sensor analytics that unlocks numerous always-on ML applications. This article discusses the potential of these TinyML applications to address critical sustainability challenges. Moreover, the footprint of this emerging technology is assessed through a complete life cycle analysis of TinyML systems. From this analysis, TinyML presents opportunities to offset its carbon emissions by enabling applications that reduce the emissions of other sectors. Nevertheless, when globally scaled, the carbon footprint of TinyML systems is not negligible, necessitating that designers factor in environmental impact when formulating new devices. Finally, research directions for enabling further opportunities for TinyML to contribute to a sustainable future are outlined.
FastML Science Benchmarks: Accelerating Real-Time Scientific Edge Machine Learning
Jul 16, 2022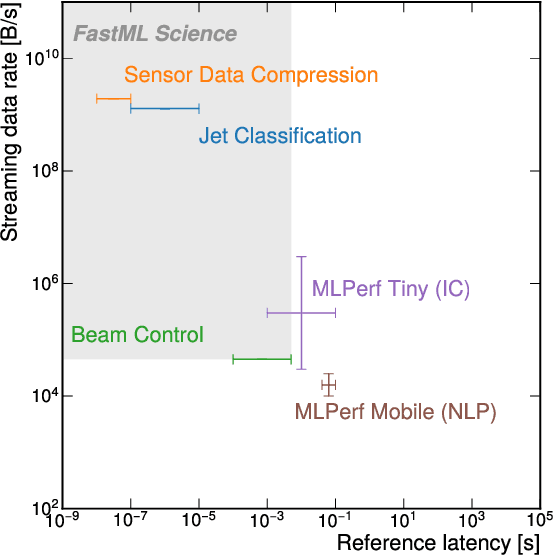
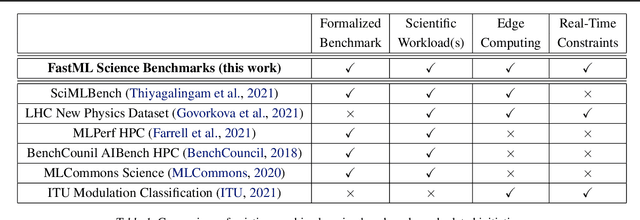
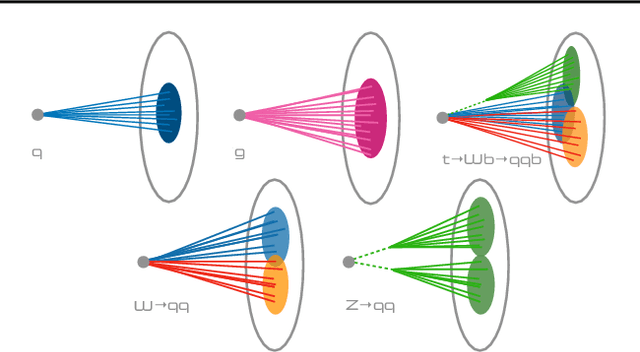

Applications of machine learning (ML) are growing by the day for many unique and challenging scientific applications. However, a crucial challenge facing these applications is their need for ultra low-latency and on-detector ML capabilities. Given the slowdown in Moore's law and Dennard scaling, coupled with the rapid advances in scientific instrumentation that is resulting in growing data rates, there is a need for ultra-fast ML at the extreme edge. Fast ML at the edge is essential for reducing and filtering scientific data in real-time to accelerate science experimentation and enable more profound insights. To accelerate real-time scientific edge ML hardware and software solutions, we need well-constrained benchmark tasks with enough specifications to be generically applicable and accessible. These benchmarks can guide the design of future edge ML hardware for scientific applications capable of meeting the nanosecond and microsecond level latency requirements. To this end, we present an initial set of scientific ML benchmarks, covering a variety of ML and embedded system techniques.
Machine Learning Sensors
Jun 07, 2022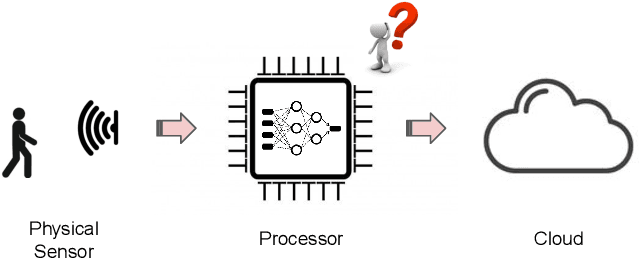
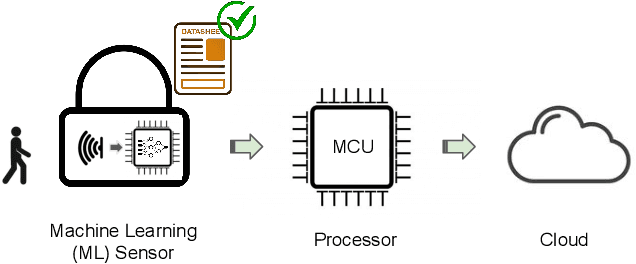
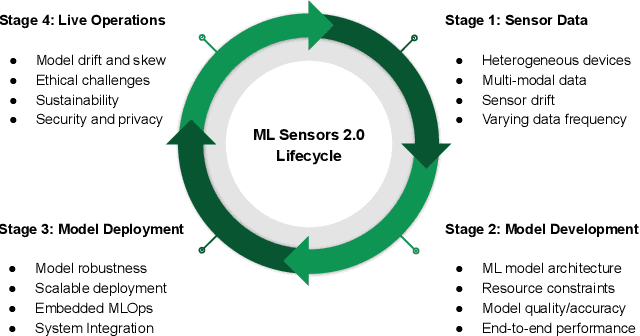
Machine learning sensors represent a paradigm shift for the future of embedded machine learning applications. Current instantiations of embedded machine learning (ML) suffer from complex integration, lack of modularity, and privacy and security concerns from data movement. This article proposes a more data-centric paradigm for embedding sensor intelligence on edge devices to combat these challenges. Our vision for "sensor 2.0" entails segregating sensor input data and ML processing from the wider system at the hardware level and providing a thin interface that mimics traditional sensors in functionality. This separation leads to a modular and easy-to-use ML sensor device. We discuss challenges presented by the standard approach of building ML processing into the software stack of the controlling microprocessor on an embedded system and how the modularity of ML sensors alleviates these problems. ML sensors increase privacy and accuracy while making it easier for system builders to integrate ML into their products as a simple component. We provide examples of prospective ML sensors and an illustrative datasheet as a demonstration and hope that this will build a dialogue to progress us towards sensor 2.0.
Tiny Robot Learning: Challenges and Directions for Machine Learning in Resource-Constrained Robots
May 11, 2022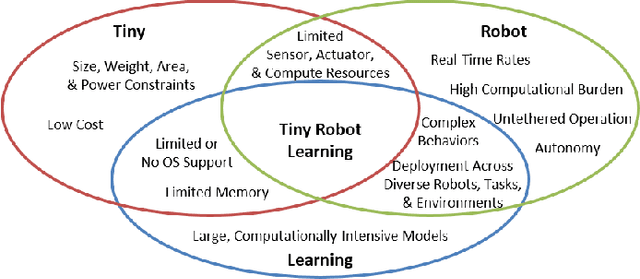
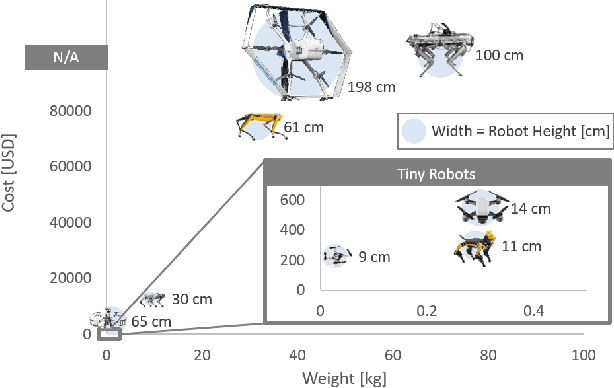
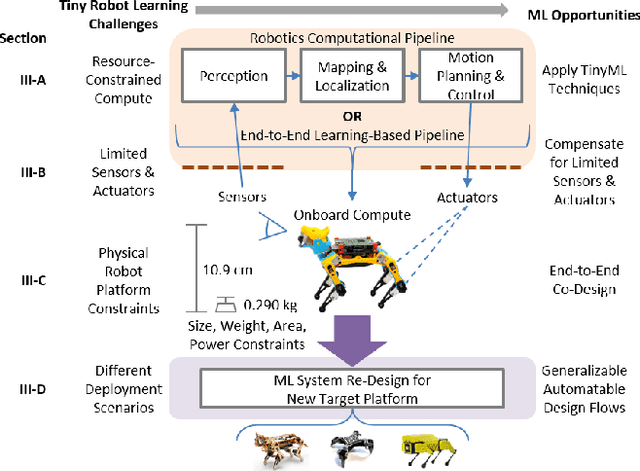
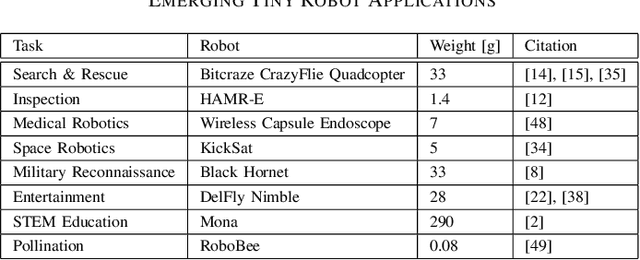
Machine learning (ML) has become a pervasive tool across computing systems. An emerging application that stress-tests the challenges of ML system design is tiny robot learning, the deployment of ML on resource-constrained low-cost autonomous robots. Tiny robot learning lies at the intersection of embedded systems, robotics, and ML, compounding the challenges of these domains. Tiny robot learning is subject to challenges from size, weight, area, and power (SWAP) constraints; sensor, actuator, and compute hardware limitations; end-to-end system tradeoffs; and a large diversity of possible deployment scenarios. Tiny robot learning requires ML models to be designed with these challenges in mind, providing a crucible that reveals the necessity of holistic ML system design and automated end-to-end design tools for agile development. This paper gives a brief survey of the tiny robot learning space, elaborates on key challenges, and proposes promising opportunities for future work in ML system design.
CFU Playground: Full-Stack Open-Source Framework for Tiny Machine Learning (tinyML) Acceleration on FPGAs
Jan 05, 2022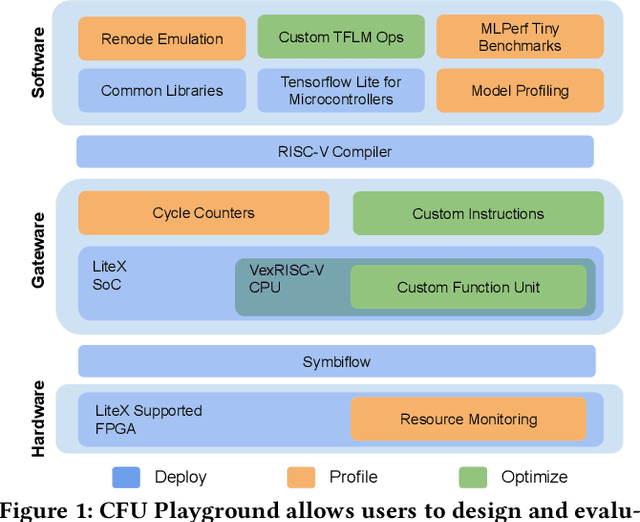
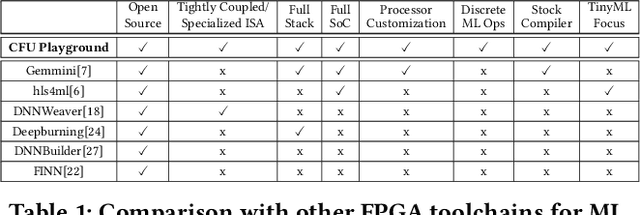
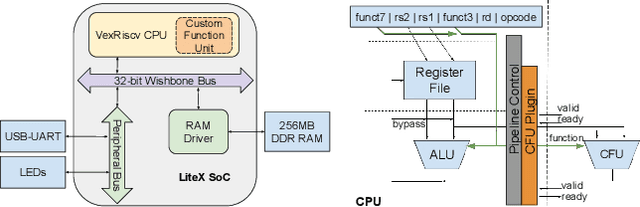
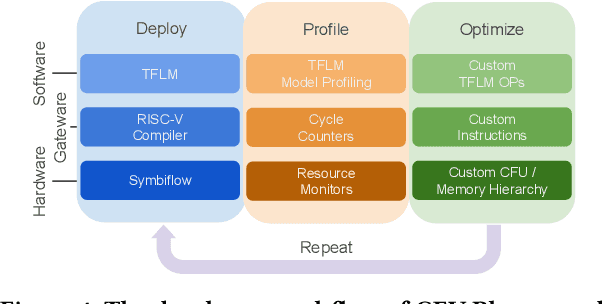
We present CFU Playground, a full-stack open-source framework that enables rapid and iterative design of machine learning (ML) accelerators for embedded ML systems. Our toolchain tightly integrates open-source software, RTL generators, and FPGA tools for synthesis, place, and route. This full-stack development framework gives engineers access to explore bespoke architectures that are customized and co-optimized for embedded ML. The rapid, deploy-profile-optimization feedback loop lets ML hardware and software developers achieve significant returns out of a relatively small investment in customization. Using CFU Playground's design loop, we show substantial speedups (55x-75x) and design space exploration between the CPU and accelerator.