 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuArch: A Question-Answering Dataset for AI Agents in Computer Architecture
Jan 06, 2025



We introduce QuArch, a dataset of 1500 human-validated question-answer pairs designed to evaluate and enhance language models' understanding of computer architecture. The dataset covers areas including processor design, memory systems, and performance optimization. Our analysis highlights a significant performance gap: the best closed-source model achieves 84% accuracy, while the top small open-source model reaches 72%. We observe notable struggles in memory systems, interconnection networks, and benchmarking. Fine-tuning with QuArch improves small model accuracy by up to 8%, establishing a foundation for advancing AI-driven computer architecture research. The dataset and leaderboard are at https://harvard-edge.github.io/QuArch/.
GRiD: GPU-Accelerated Rigid Body Dynamics with Analytical Gradients
Sep 14, 2021
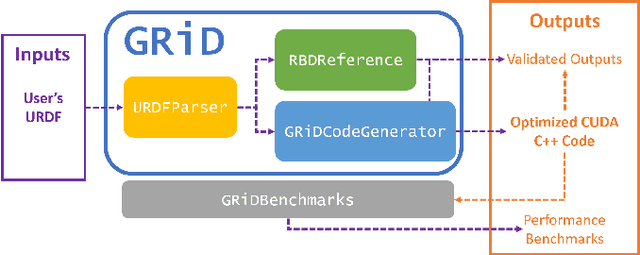
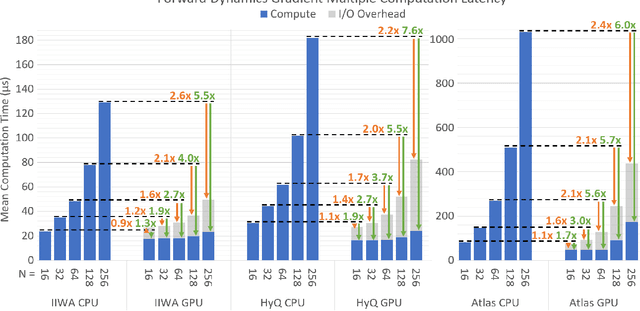
We introduce GRiD: a GPU-accelerated library for computing rigid body dynamics with analytical gradients. GRiD was designed to accelerate the nonlinear trajectory optimization subproblem used in state-of-the-art robotic planning, control, and machine learning. Each iteration of nonlinear trajectory optimization requires tens to hundreds of naturally parallel computations of rigid body dynamics and their gradients. GRiD leverages URDF parsing and code generation to deliver optimized dynamics kernels that not only expose GPU-friendly computational patterns, but also take advantage of both fine-grained parallelism within each computation and coarse-grained parallelism between computations. Through this approach, when performing multiple computations of rigid body dynamics algorithms, GRiD provides as much as a 7.6x speedup over a state-of-the-art, multi-threaded CPU implementation, and maintains as much as a 2.6x speedup when accounting for I/O overhead. We release GRiD as an open-source library, so that it can be leveraged by the robotics community to easily and efficiently accelerate rigid body dynamics on the GPU.
RoboRun: A Robot Runtime to Exploit Spatial Heterogeneity
Aug 30, 2021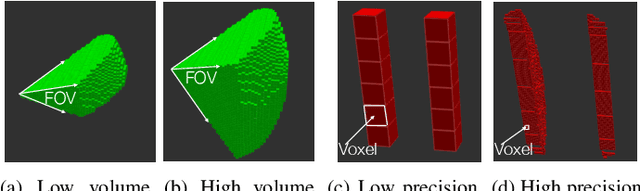
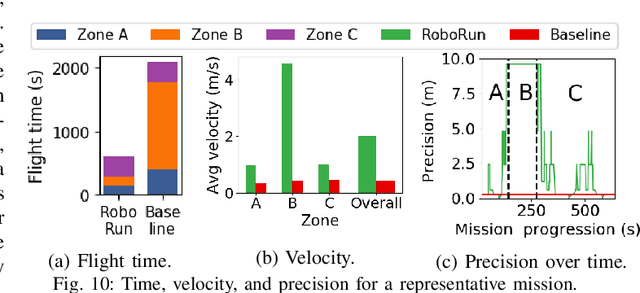
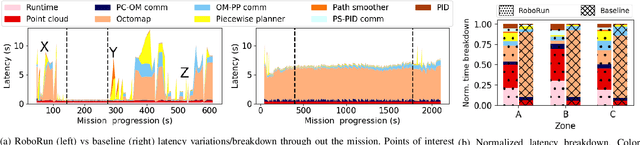
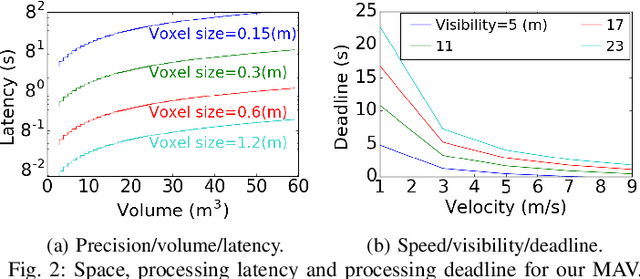
The limited onboard energy of autonomous mobile robots poses a tremendous challenge for practical deployment. Hence, efficient computing solutions are imperative. A crucial shortcoming of state-of-the-art computing solutions is that they ignore the robot's operating environment heterogeneity and make static, worst-case assumptions. As this heterogeneity impacts the system's computing payload, an optimal system must dynamically capture these changes in the environment and adjust its computational resources accordingly. This paper introduces RoboRun, a mobile-robot runtime that dynamically exploits the compute-environment synergy to improve performance and energy. We implement RoboRun in the Robot Operating System (ROS) and evaluate it on autonomous drones. We compare RoboRun against a state-of-the-art static design and show 4.5X and 4X improvements in mission time and energy, respectively, as well as a 36% reduction in CPU utilization.
Widening Access to Applied Machine Learning with TinyML
Jun 09, 2021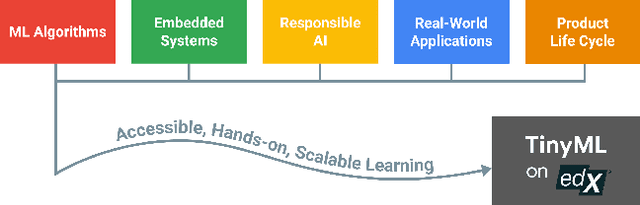
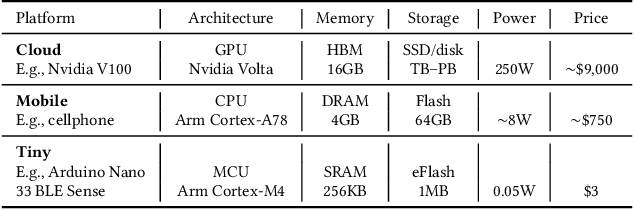

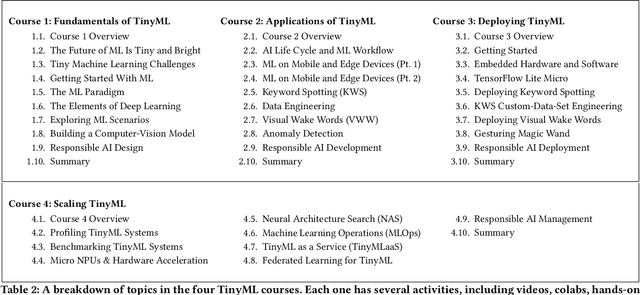
Broadening access to both computational and educational resources is critical to diffusing machine-learning (ML) innovation. However, today, most ML resources and experts are siloed in a few countries and organizations. In this paper, we describe our pedagogical approach to increasing access to applied ML through a massive open online course (MOOC) on Tiny Machine Learning (TinyML). We suggest that TinyML, ML on resource-constrained embedded devices, is an attractive means to widen access because TinyML both leverages low-cost and globally accessible hardware, and encourages the development of complete, self-contained applications, from data collection to deployment. To this end, a collaboration between academia (Harvard University) and industry (Google) produced a four-part MOOC that provides application-oriented instruction on how to develop solutions using TinyML. The series is openly available on the edX MOOC platform, has no prerequisites beyond basic programming, and is designed for learners from a global variety of backgrounds. It introduces pupils to real-world applications, ML algorithms, data-set engineering, and the ethical considerations of these technologies via hands-on programming and deployment of TinyML applications in both the cloud and their own microcontrollers. To facilitate continued learning, community building, and collaboration beyond the courses, we launched a standalone website, a forum, a chat, and an optional course-project competition. We also released the course materials publicly, hoping they will inspire the next generation of ML practitioners and educators and further broaden access to cutting-edge ML technologies.
MAVFI: An End-to-End Fault Analysis Framework with Anomaly Detection and Recovery for Micro Aerial Vehicles
May 27, 2021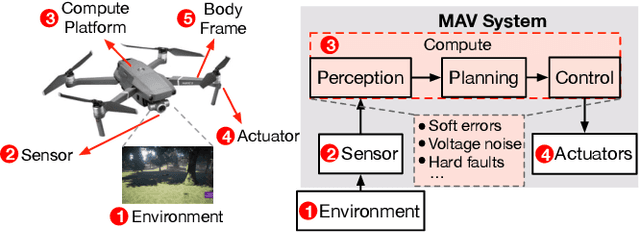

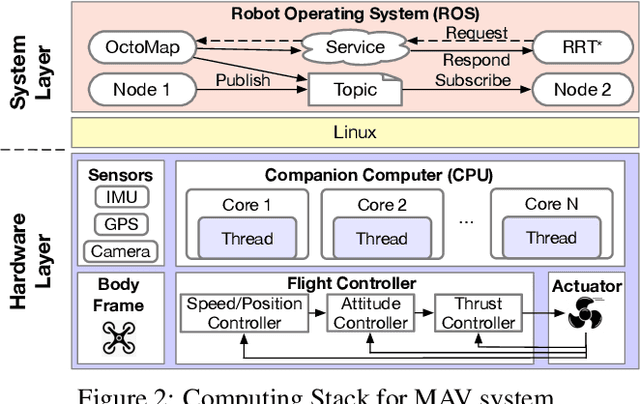
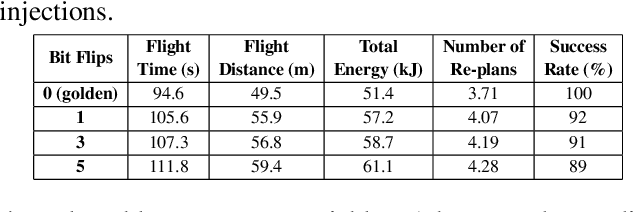
Reliability and safety are critical in autonomous machine services, such as autonomous vehicles and aerial drones. In this paper, we first present an open-source Micro Aerial Vehicles (MAVs) reliability analysis framework, MAVFI, to characterize transient fault's impacts on the end-to-end flight metrics, e.g., flight time, success rate. Based on our framework, it is observed that the end-to-end fault tolerance analysis is essential for characterizing system reliability. We demonstrate the planning and control stages are more vulnerable to transient faults than the visual perception stage in the common "Perception-Planning-Control (PPC)" compute pipeline. Furthermore, to improve the reliability of the MAV system, we propose two low overhead anomaly-based transient fault detection and recovery schemes based on Gaussian statistical models and autoencoder neural networks. We validate our anomaly fault protection schemes with a variety of simulated photo-realistic environments on both Intel i9 CPU and ARM Cortex-A57 on Nvidia TX2 platform. It is demonstrated that the autoencoder-based scheme can improve the system reliability by 100% recovering failure cases with less than 0.0062% computational overhead in best-case scenarios. In addition, MAVFI framework can be used for other ROS-based cyber-physical applications and is open-sourced at https://github.com/harvard-edge/MAVBench/tree/mavfi