 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs TinyML Sustainable? Assessing the Environmental Impacts of Machine Learning on Microcontrollers
Jan 27, 2023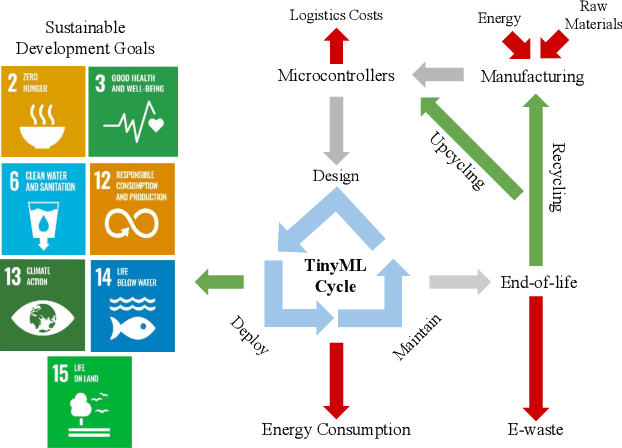
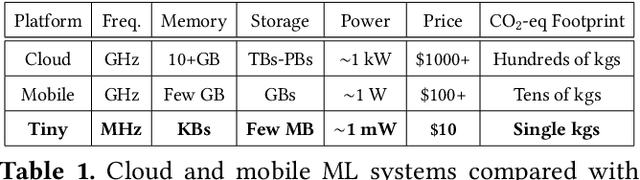
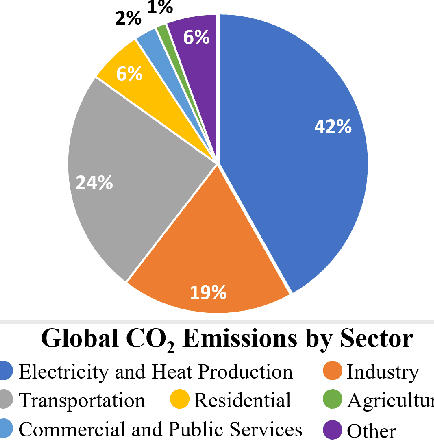
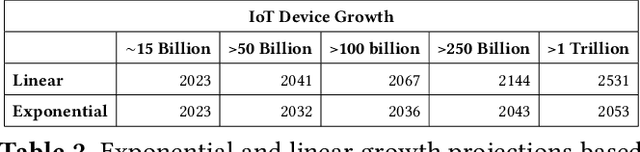
The sustained growth of carbon emissions and global waste elicits significant sustainability concerns for our environment's future. The growing Internet of Things (IoT) has the potential to exacerbate this issue. However, an emerging area known as Tiny Machine Learning (TinyML) has the opportunity to help address these environmental challenges through sustainable computing practices. TinyML, the deployment of machine learning (ML) algorithms onto low-cost, low-power microcontroller systems, enables on-device sensor analytics that unlocks numerous always-on ML applications. This article discusses the potential of these TinyML applications to address critical sustainability challenges. Moreover, the footprint of this emerging technology is assessed through a complete life cycle analysis of TinyML systems. From this analysis, TinyML presents opportunities to offset its carbon emissions by enabling applications that reduce the emissions of other sectors. Nevertheless, when globally scaled, the carbon footprint of TinyML systems is not negligible, necessitating that designers factor in environmental impact when formulating new devices. Finally, research directions for enabling further opportunities for TinyML to contribute to a sustainable future are outlined.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022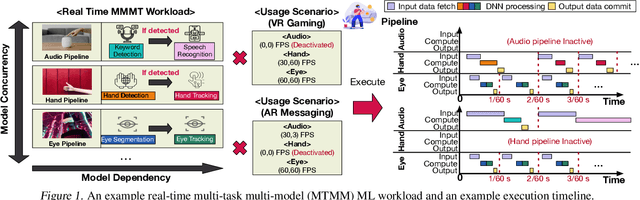
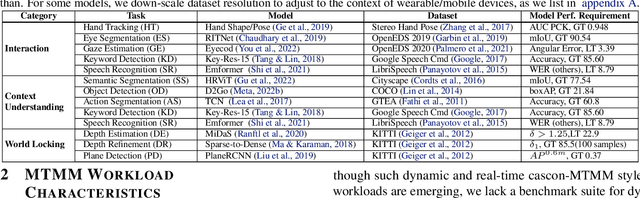

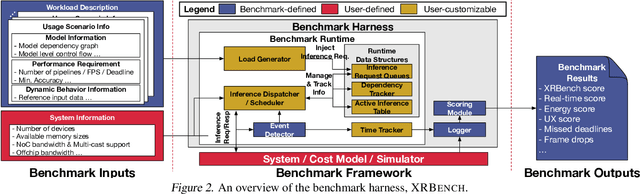
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022
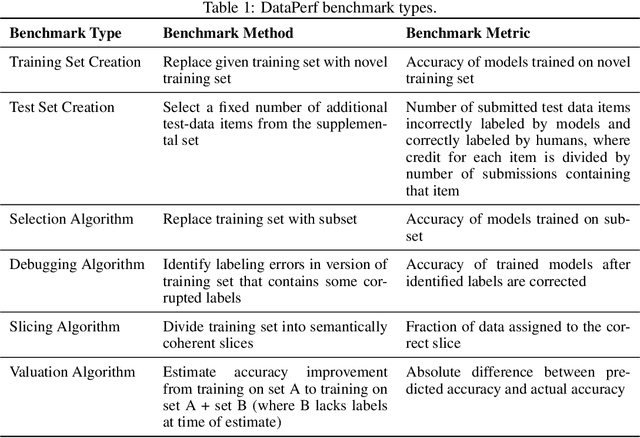
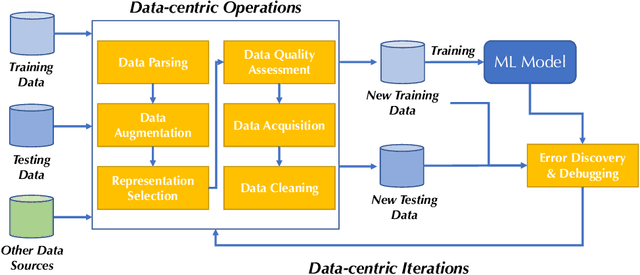
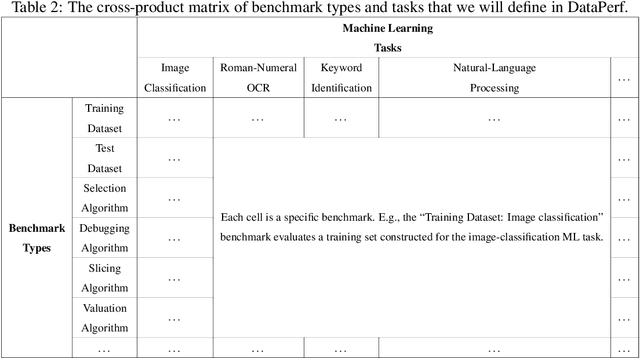
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Tiny Robot Learning: Challenges and Directions for Machine Learning in Resource-Constrained Robots
May 11, 2022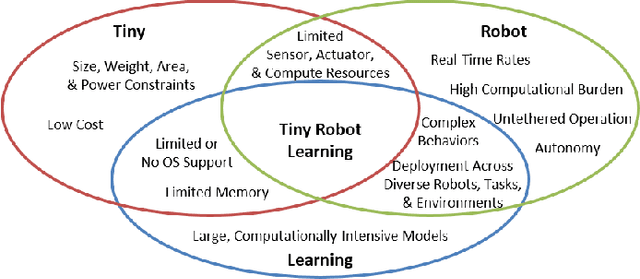
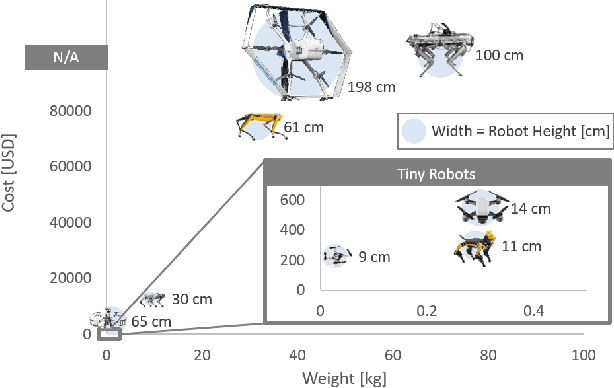
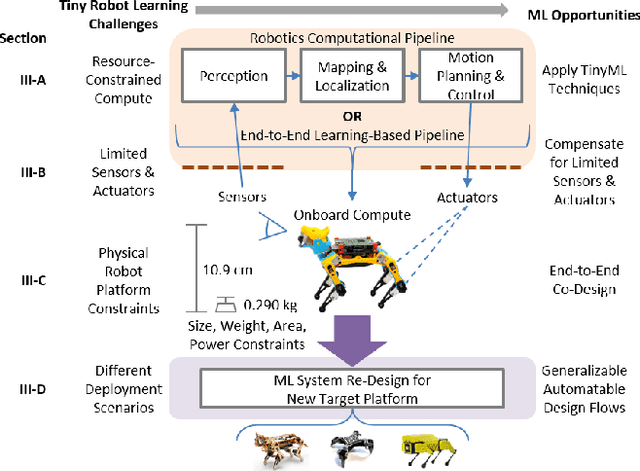
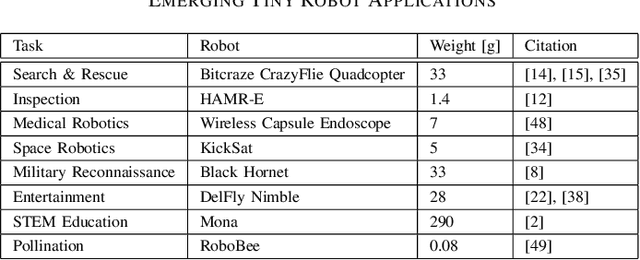
Machine learning (ML) has become a pervasive tool across computing systems. An emerging application that stress-tests the challenges of ML system design is tiny robot learning, the deployment of ML on resource-constrained low-cost autonomous robots. Tiny robot learning lies at the intersection of embedded systems, robotics, and ML, compounding the challenges of these domains. Tiny robot learning is subject to challenges from size, weight, area, and power (SWAP) constraints; sensor, actuator, and compute hardware limitations; end-to-end system tradeoffs; and a large diversity of possible deployment scenarios. Tiny robot learning requires ML models to be designed with these challenges in mind, providing a crucible that reveals the necessity of holistic ML system design and automated end-to-end design tools for agile development. This paper gives a brief survey of the tiny robot learning space, elaborates on key challenges, and proposes promising opportunities for future work in ML system design.
The People's Speech: A Large-Scale Diverse English Speech Recognition Dataset for Commercial Usage
Nov 17, 2021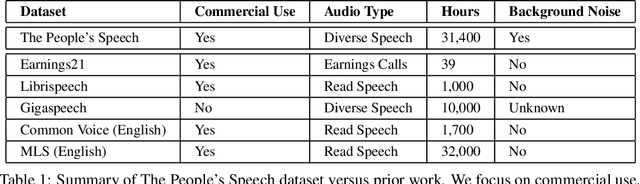
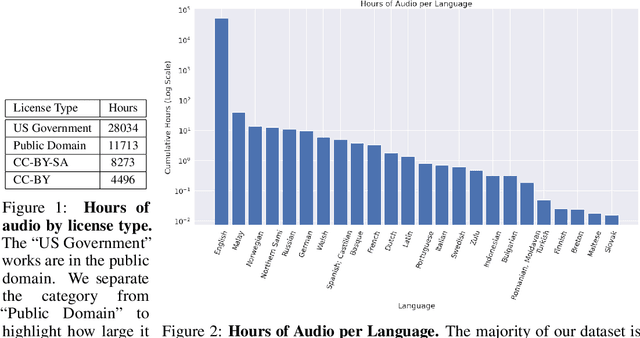

The People's Speech is a free-to-download 30,000-hour and growing supervised conversational English speech recognition dataset licensed for academic and commercial usage under CC-BY-SA (with a CC-BY subset). The data is collected via searching the Internet for appropriately licensed audio data with existing transcriptions. We describe our data collection methodology and release our data collection system under the Apache 2.0 license. We show that a model trained on this dataset achieves a 9.98% word error rate on Librispeech's test-clean test set.Finally, we discuss the legal and ethical issues surrounding the creation of a sizable machine learning corpora and plans for continued maintenance of the project under MLCommons's sponsorship.
Widening Access to Applied Machine Learning with TinyML
Jun 09, 2021

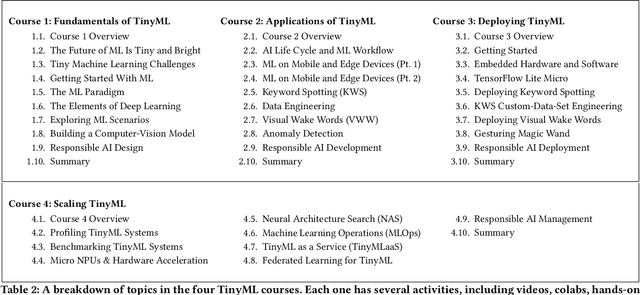
Broadening access to both computational and educational resources is critical to diffusing machine-learning (ML) innovation. However, today, most ML resources and experts are siloed in a few countries and organizations. In this paper, we describe our pedagogical approach to increasing access to applied ML through a massive open online course (MOOC) on Tiny Machine Learning (TinyML). We suggest that TinyML, ML on resource-constrained embedded devices, is an attractive means to widen access because TinyML both leverages low-cost and globally accessible hardware, and encourages the development of complete, self-contained applications, from data collection to deployment. To this end, a collaboration between academia (Harvard University) and industry (Google) produced a four-part MOOC that provides application-oriented instruction on how to develop solutions using TinyML. The series is openly available on the edX MOOC platform, has no prerequisites beyond basic programming, and is designed for learners from a global variety of backgrounds. It introduces pupils to real-world applications, ML algorithms, data-set engineering, and the ethical considerations of these technologies via hands-on programming and deployment of TinyML applications in both the cloud and their own microcontrollers. To facilitate continued learning, community building, and collaboration beyond the courses, we launched a standalone website, a forum, a chat, and an optional course-project competition. We also released the course materials publicly, hoping they will inspire the next generation of ML practitioners and educators and further broaden access to cutting-edge ML technologies.
Few-Shot Keyword Spotting in Any Language
Apr 22, 2021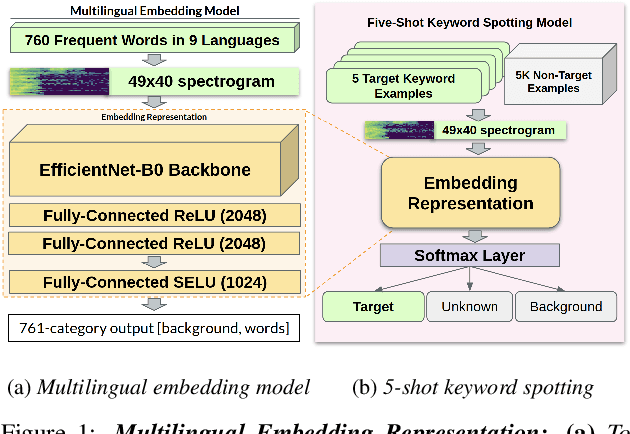

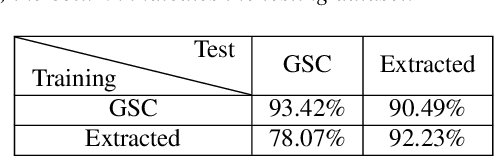
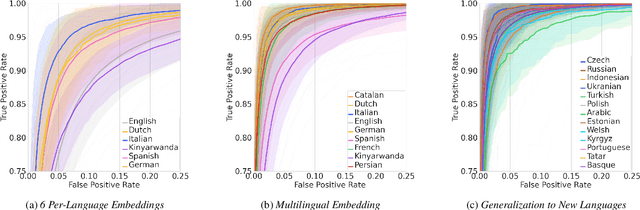
We introduce a few-shot transfer learning method for keyword spotting in any language. Leveraging open speech corpora in nine languages, we automate the extraction of a large multilingual keyword bank and use it to train an embedding model. With just five training examples, we fine-tune the embedding model for keyword spotting and achieve an average F1 score of 0.75 on keyword classification for 180 new keywords unseen by the embedding model in these nine languages. This embedding model also generalizes to new languages. We achieve an average F1 score of 0.65 on 5-shot models for 260 keywords sampled across 13 new languages unseen by the embedding model. We investigate streaming accuracy for our 5-shot models in two contexts: keyword spotting and keyword search. Across 440 keywords in 22 languages, we achieve an average streaming keyword spotting accuracy of 85.2% with a false acceptance rate of 1.2%, and observe promising initial results on keyword search.
Active Rendezvous for Multi-Robot Pose Graph Optimization using Sensing over Wi-Fi
Jul 12, 2019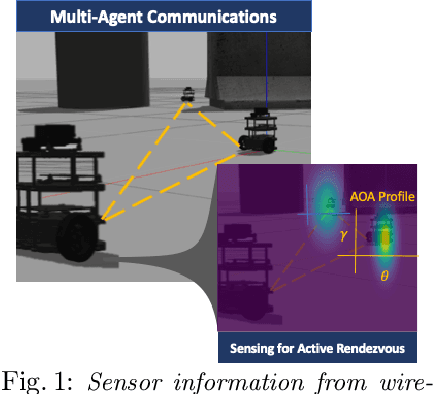
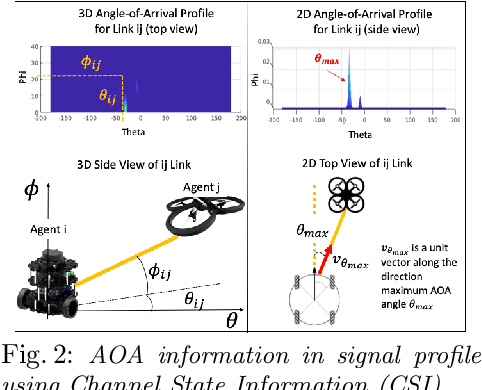
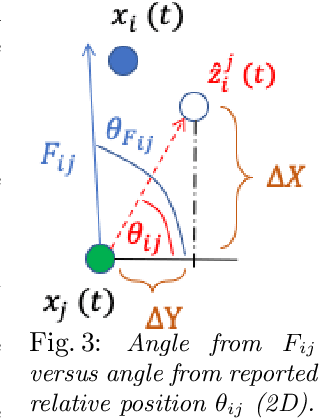
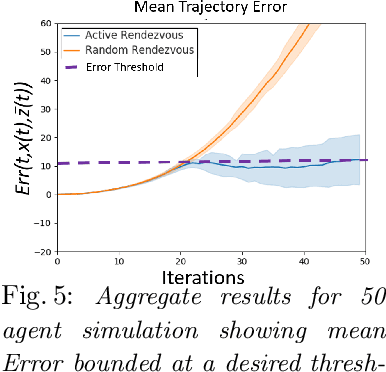
We present a novel framework for collaboration amongst a team of robots performing Pose Graph Optimization (PGO) that addresses two important challenges for multi-robot SLAM: that of enabling information exchange "on-demand" via active rendezvous, and that of rejecting outlier measurements with high probability. Our key insight is to exploit relative position data present in the communication channel between agents, as an independent measurement in PGO. We show that our algorithmic and experimental framework for integrating Channel State Information (CSI) over the communication channels, with multi-agent PGO, addresses the two open challenges of enabling information exchange and rejecting outliers. Our presented framework is distributed and applicable in low-lighting or featureless environments where traditional sensors often fail. We present extensive experimental results on actual robots showing both the use of active rendezvous resulting in error reduction by 6X as compared to randomly occurring rendezvous and the use of CSI observations providing a reduction in ground truth pose estimation errors of 32%. These results demonstrate the promise of using a combination of multi-robot coordination and CSI to address challenges in multi-agent localization and mapping -- providing an important step towards integrating communication as a novel sensor for SLAM tasks.