 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRCHITECT v2: Learning the Hardware Accelerator Design Space through Unified Representations
Jan 17, 2025Design space exploration (DSE) plays a crucial role in enabling custom hardware architectures, particularly for emerging applications like AI, where optimized and specialized designs are essential. With the growing complexity of deep neural networks (DNNs) and the introduction of advanced foundational models (FMs), the design space for DNN accelerators is expanding at an exponential rate. Additionally, this space is highly non-uniform and non-convex, making it increasingly difficult to navigate and optimize. Traditional DSE techniques rely on search-based methods, which involve iterative sampling of the design space to find the optimal solution. However, this process is both time-consuming and often fails to converge to the global optima for such design spaces. Recently, AIrchitect v1, the first attempt to address the limitations of search-based techniques, transformed DSE into a constant-time classification problem using recommendation networks. In this work, we propose AIrchitect v2, a more accurate and generalizable learning-based DSE technique applicable to large-scale design spaces that overcomes the shortcomings of earlier approaches. Specifically, we devise an encoder-decoder transformer model that (a) encodes the complex design space into a uniform intermediate representation using contrastive learning and (b) leverages a novel unified representation blending the advantages of classification and regression to effectively explore the large DSE space without sacrificing accuracy. Experimental results evaluated on 10^5 real DNN workloads demonstrate that, on average, AIrchitect v2 outperforms existing techniques by 15% in identifying optimal design points. Furthermore, to demonstrate the generalizability of our method, we evaluate performance on unseen model workloads (LLMs) and attain a 1.7x improvement in inference latency on the identified hardware architecture.
Real-time Digital RF Emulation -- II: A Near Memory Custom Accelerator
Jun 13, 2024



A near memory hardware accelerator, based on a novel direct path computational model, for real-time emulation of radio frequency systems is demonstrated. Our evaluation of hardware performance uses both application-specific integrated circuits (ASIC) and field programmable gate arrays (FPGA) methodologies: 1). The ASIC testchip implementation, using TSMC 28nm CMOS, leverages distributed autonomous control to extract concurrency in compute as well as low latency. It achieves a $518$ MHz per channel bandwidth in a prototype $4$-node system. The maximum emulation range supported in this paradigm is $9.5$ km with $0.24$ $\mu$s of per-sample emulation latency. 2). The FPGA-based implementation, evaluated on a Xilinx ZCU104 board, demonstrates a $9$-node test case (two Transmitters, one Receiver, and $6$ passive reflectors) with an emulation range of $1.13$ km to $27.3$ km at $215$ MHz bandwidth.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022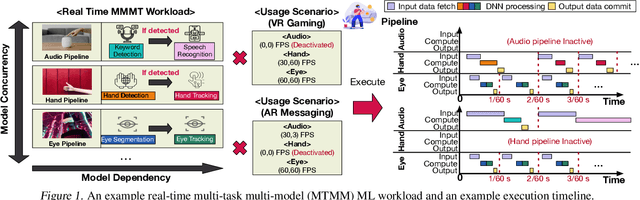
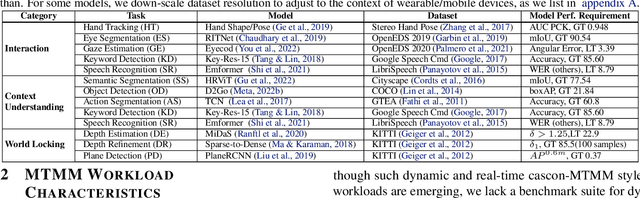

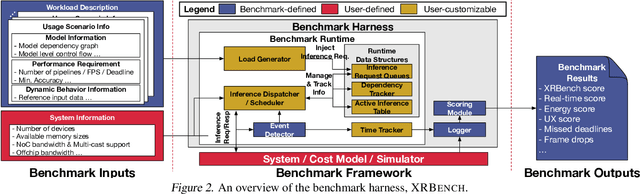
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.