 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRCHITECT v2: Learning the Hardware Accelerator Design Space through Unified Representations
Jan 17, 2025Design space exploration (DSE) plays a crucial role in enabling custom hardware architectures, particularly for emerging applications like AI, where optimized and specialized designs are essential. With the growing complexity of deep neural networks (DNNs) and the introduction of advanced foundational models (FMs), the design space for DNN accelerators is expanding at an exponential rate. Additionally, this space is highly non-uniform and non-convex, making it increasingly difficult to navigate and optimize. Traditional DSE techniques rely on search-based methods, which involve iterative sampling of the design space to find the optimal solution. However, this process is both time-consuming and often fails to converge to the global optima for such design spaces. Recently, AIrchitect v1, the first attempt to address the limitations of search-based techniques, transformed DSE into a constant-time classification problem using recommendation networks. In this work, we propose AIrchitect v2, a more accurate and generalizable learning-based DSE technique applicable to large-scale design spaces that overcomes the shortcomings of earlier approaches. Specifically, we devise an encoder-decoder transformer model that (a) encodes the complex design space into a uniform intermediate representation using contrastive learning and (b) leverages a novel unified representation blending the advantages of classification and regression to effectively explore the large DSE space without sacrificing accuracy. Experimental results evaluated on 10^5 real DNN workloads demonstrate that, on average, AIrchitect v2 outperforms existing techniques by 15% in identifying optimal design points. Furthermore, to demonstrate the generalizability of our method, we evaluate performance on unseen model workloads (LLMs) and attain a 1.7x improvement in inference latency on the identified hardware architecture.
Leveraging ASIC AI Chips for Homomorphic Encryption
Jan 13, 2025
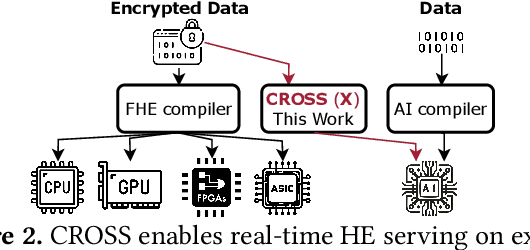
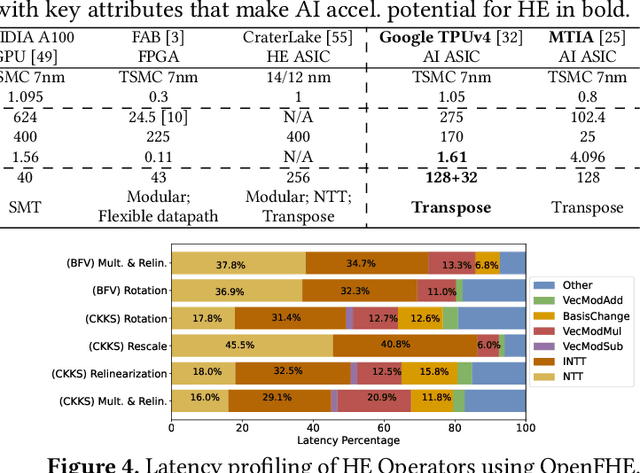
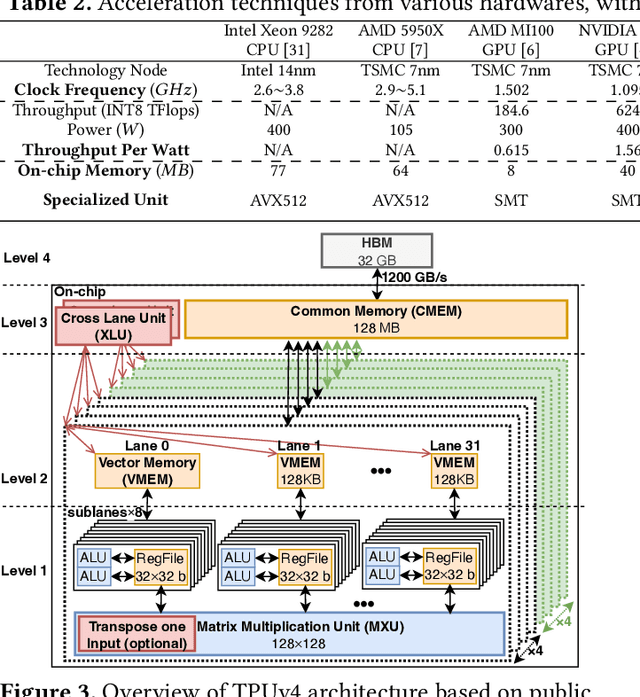
Cloud-based services are making the outsourcing of sensitive client data increasingly common. Although homomorphic encryption (HE) offers strong privacy guarantee, it requires substantially more resources than computing on plaintext, often leading to unacceptably large latencies in getting the results. HE accelerators have emerged to mitigate this latency issue, but with the high cost of ASICs. In this paper we show that HE primitives can be converted to AI operators and accelerated on existing ASIC AI accelerators, like TPUs, which are already widely deployed in the cloud. Adapting such accelerators for HE requires (1) supporting modular multiplication, (2) high-precision arithmetic in software, and (3) efficient mapping on matrix engines. We introduce the CROSS compiler (1) to adopt Barrett reduction to provide modular reduction support using multiplier and adder, (2) Basis Aligned Transformation (BAT) to convert high-precision multiplication as low-precision matrix-vector multiplication, (3) Matrix Aligned Transformation (MAT) to covert vectorized modular operation with reduction into matrix multiplication that can be efficiently processed on 2D spatial matrix engine. Our evaluation of CROSS on a Google TPUv4 demonstrates significant performance improvements, with up to 161x and 5x speedup compared to the previous work on many-core CPUs and V100. The kernel-level codes are open-sourced at https://github.com/google/jaxite.git.
Medicine Strip Identification using 2-D Cepstral Feature Extraction and Multiclass Classification Methods
Feb 03, 2020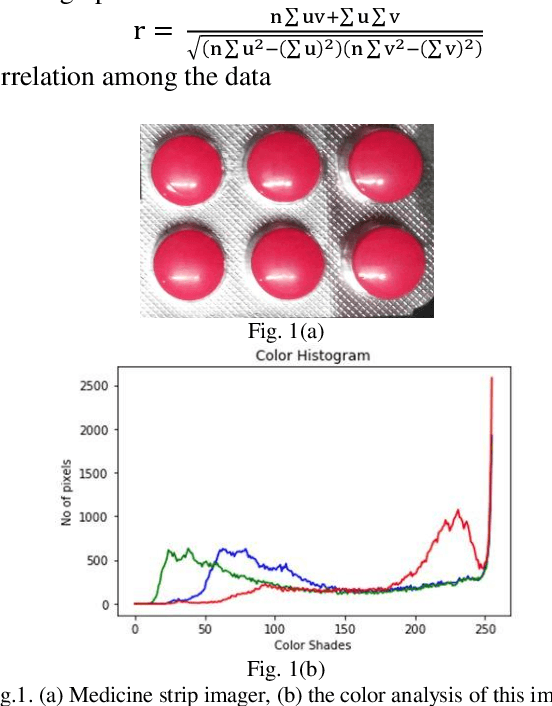


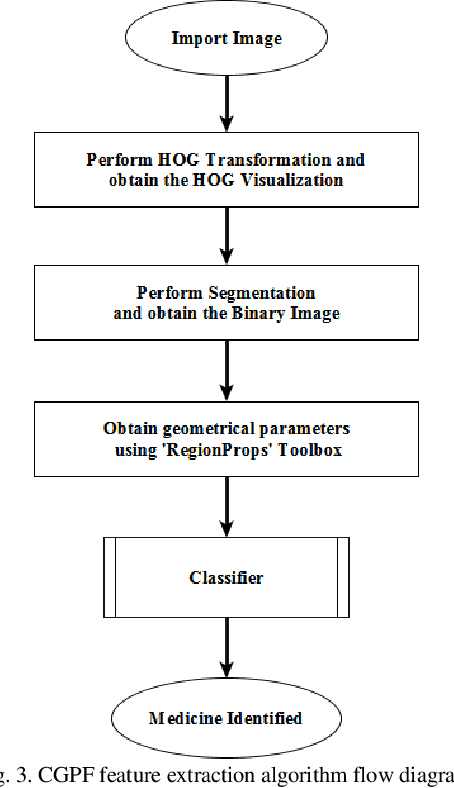
Misclassification of medicine is perilous to the health of a patient, more so if the said patient is visually impaired or simply did not recognize the color, shape or type of medicine strip. This paper proposes a method for identification of medicine strips by 2-D cepstral analysis of their images followed by performing classification that has been done using the K-Nearest Neighbor (KNN), Support Vector Machine (SVM) and Logistic Regression (LR) Classifiers. The 2-D cepstral features extracted are extremely distinct to a medicine strip and consequently make identifying them exceptionally accurate. This paper also proposes the Color Gradient and Pill shape Feature (CGPF) extraction procedure and discusses the Binary Robust Invariant Scalable Keypoints (BRISK) algorithm as well. The mentioned algorithms were implemented and their identification results have been compared.