 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRCHITECT v2: Learning the Hardware Accelerator Design Space through Unified Representations
Jan 17, 2025Design space exploration (DSE) plays a crucial role in enabling custom hardware architectures, particularly for emerging applications like AI, where optimized and specialized designs are essential. With the growing complexity of deep neural networks (DNNs) and the introduction of advanced foundational models (FMs), the design space for DNN accelerators is expanding at an exponential rate. Additionally, this space is highly non-uniform and non-convex, making it increasingly difficult to navigate and optimize. Traditional DSE techniques rely on search-based methods, which involve iterative sampling of the design space to find the optimal solution. However, this process is both time-consuming and often fails to converge to the global optima for such design spaces. Recently, AIrchitect v1, the first attempt to address the limitations of search-based techniques, transformed DSE into a constant-time classification problem using recommendation networks. In this work, we propose AIrchitect v2, a more accurate and generalizable learning-based DSE technique applicable to large-scale design spaces that overcomes the shortcomings of earlier approaches. Specifically, we devise an encoder-decoder transformer model that (a) encodes the complex design space into a uniform intermediate representation using contrastive learning and (b) leverages a novel unified representation blending the advantages of classification and regression to effectively explore the large DSE space without sacrificing accuracy. Experimental results evaluated on 10^5 real DNN workloads demonstrate that, on average, AIrchitect v2 outperforms existing techniques by 15% in identifying optimal design points. Furthermore, to demonstrate the generalizability of our method, we evaluate performance on unseen model workloads (LLMs) and attain a 1.7x improvement in inference latency on the identified hardware architecture.
C3-SL: Circular Convolution-Based Batch-Wise Compression for Communication-Efficient Split Learning
Jul 25, 2022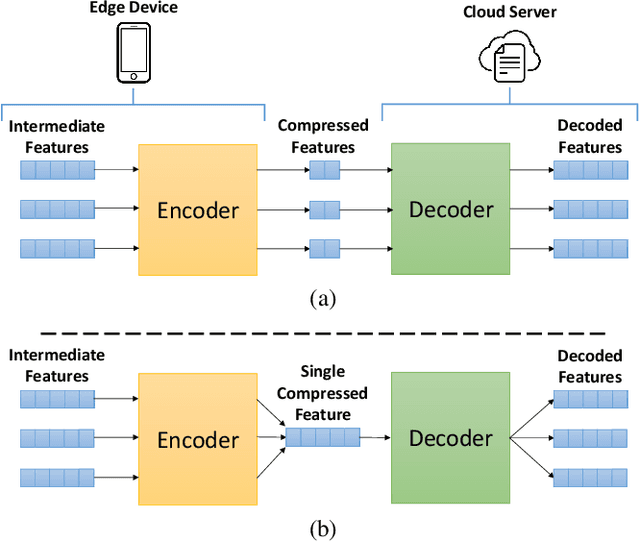


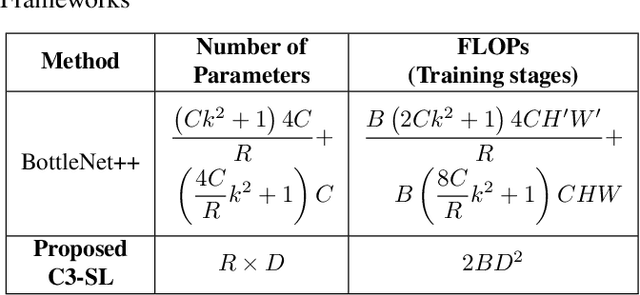
Most existing studies improve the efficiency of Split learning (SL) by compressing the transmitted features. However, most works focus on dimension-wise compression that transforms high-dimensional features into a low-dimensional space. In this paper, we propose circular convolution-based batch-wise compression for SL (C3-SL) to compress multiple features into one single feature. To avoid information loss while merging multiple features, we exploit the quasi-orthogonality of features in high-dimensional space with circular convolution and superposition. To the best of our knowledge, we are the first to explore the potential of batch-wise compression under the SL scenario. Based on the simulation results on CIFAR-10 and CIFAR-100, our method achieves a 16x compression ratio with negligible accuracy drops compared with the vanilla SL. Moreover, C3-SL significantly reduces 1152x memory and 2.25x computation overhead compared to the state-of-the-art dimension-wise compression method.
AdaBoost-assisted Extreme Learning Machine for Efficient Online Sequential Classification
Sep 16, 2019



In this paper, we propose an AdaBoost-assisted extreme learning machine for efficient online sequential classification (AOS-ELM). In order to achieve better accuracy in online sequential learning scenarios, we utilize the cost-sensitive algorithm-AdaBoost, which diversifying the weak classifiers, and adding the forgetting mechanism, which stabilizing the performance during the training procedure. Hence, AOS-ELM adapts better to sequentially arrived data compared with other voting based methods. The experiment results show AOS-ELM can achieve 94.41% accuracy on MNIST dataset, which is the theoretical accuracy bound performed by an original batch learning algorithm, AdaBoost-ELM. Moreover, with the forgetting mechanism, the standard deviation of accuracy during the online sequential learning process is reduced to 8.26x.
Entropy-Assisted Multi-Modal Emotion Recognition Framework Based on Physiological Signals
Sep 22, 2018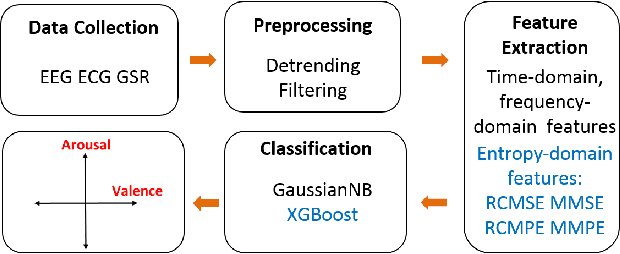
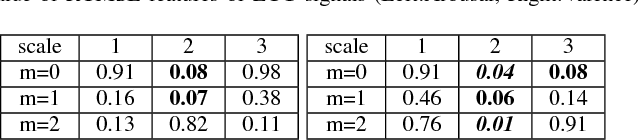
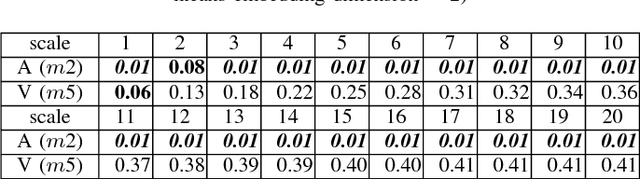
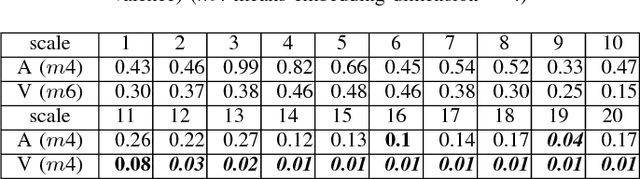
As the result of the growing importance of the Human Computer Interface system, understanding human's emotion states has become a consequential ability for the computer. This paper aims to improve the performance of emotion recognition by conducting the complexity analysis of physiological signals. Based on AMIGOS dataset, we extracted several entropy-domain features such as Refined Composite Multi-Scale Entropy (RCMSE), Refined Composite Multi-Scale Permutation Entropy (RCMPE) from ECG and GSR signals, and Multivariate Multi-Scale Entropy (MMSE), Multivariate Multi-Scale Permutation Entropy (MMPE) from EEG, respectively. The statistical results show that RCMSE in GSR has a dominating performance in arousal, while RCMPE in GSR would be the excellent feature in valence. Furthermore, we selected XGBoost model to predict emotion and get 68% accuracy in arousal and 84% in valence.