 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Coarse-to-Fine Diffusion Models with Time Step Sequence Redistribution
Mar 22, 2026Recently, diffusion models (DMs) have made significant strides in high-quality image generation. However, the multi-step denoising process often results in considerable computational overhead, impeding deployment on resource-constrained edge devices. Existing methods mitigate this issue by compressing models and adjusting the time step sequence. However, they overlook input redundancy and require lengthy search times. In this paper, we propose Coarse-to-Fine Diffusion Models with Time Step Sequence Redistribution. Recognizing indistinguishable early-stage generated images, we introduce Coarse-to-Fine Denoising (C2F) to reduce computation during coarse feature generation. Furthermore, we design Time Step Sequence Redistribution (TRD) for efficient sampling trajectory adjustment, requiring less than 10 minutes for search. Experimental results demonstrate that the proposed methods achieve near-lossless performance with an 80% to 90% reduction in computation on CIFAR10 and LSUN-Church.
Post-Training Quantization for Vision Mamba with k-Scaled Quantization and Reparameterization
Jan 28, 2025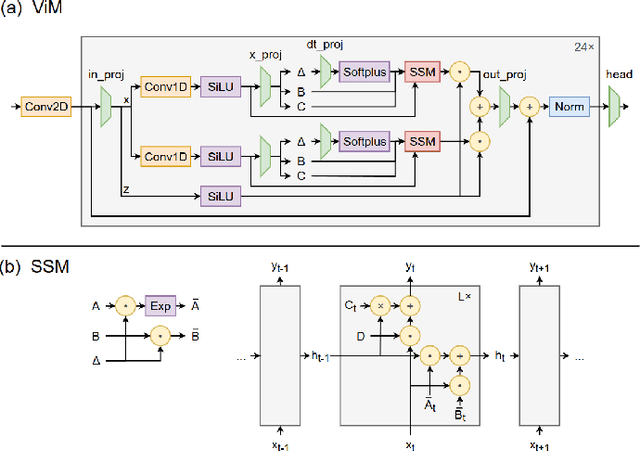
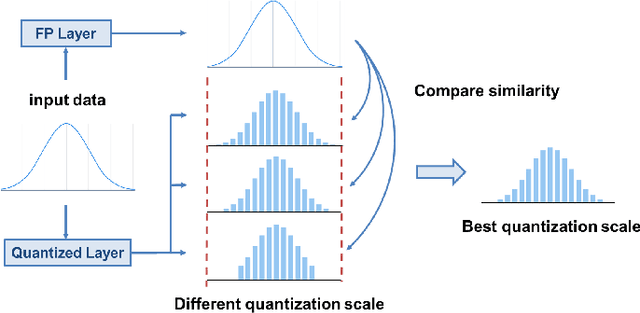
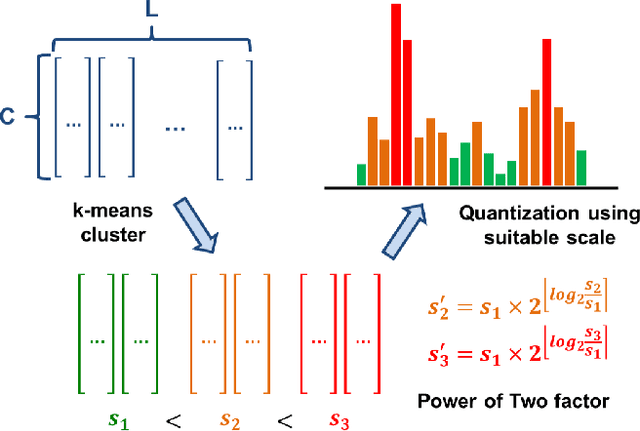
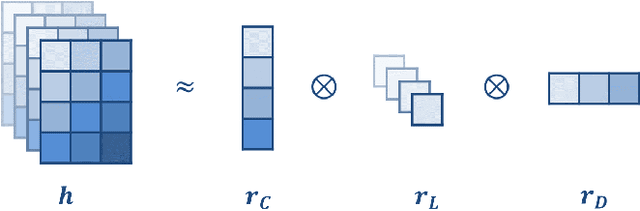
The Mamba model, utilizing a structured state-space model (SSM), offers linear time complexity and demonstrates significant potential. Vision Mamba (ViM) extends this framework to vision tasks by incorporating a bidirectional SSM and patch embedding, surpassing Transformer-based models in performance. While model quantization is essential for efficient computing, existing works have focused solely on the original Mamba model and have not been applied to ViM. Additionally, they neglect quantizing the SSM layer, which is central to Mamba and can lead to substantial error propagation by naive quantization due to its inherent structure. In this paper, we focus on the post-training quantization (PTQ) of ViM. We address the issues with three core techniques: 1) a k-scaled token-wise quantization method for linear and convolutional layers, 2) a reparameterization technique to simplify hidden state quantization, and 3) a factor-determining method that reduces computational overhead by integrating operations. Through these methods, the error caused by PTQ can be mitigated. Experimental results on ImageNet-1k demonstrate only a 0.8-1.2\% accuracy degradation due to PTQ, highlighting the effectiveness of our approach.
Efficient and Reliable Vector Similarity Search Using Asymmetric Encoding with NAND-Flash for Many-Class Few-Shot Learning
Sep 12, 2024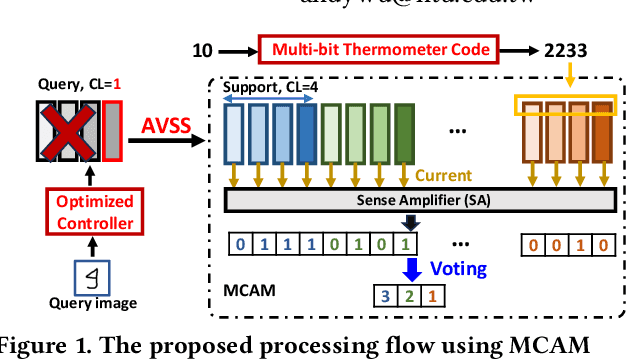
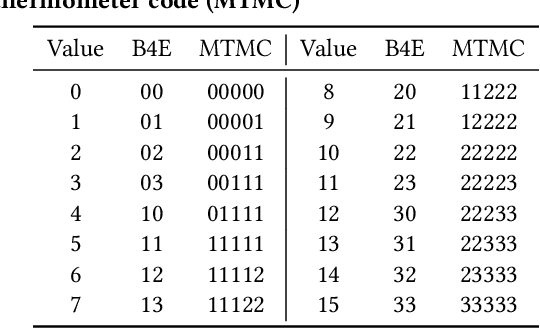
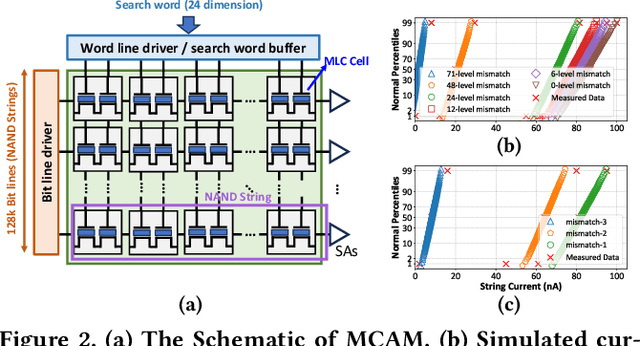
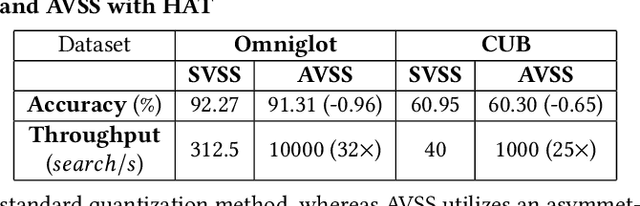
While memory-augmented neural networks (MANNs) offer an effective solution for few-shot learning (FSL) by integrating deep neural networks with external memory, the capacity requirements and energy overhead of data movement become enormous due to the large number of support vectors in many-class FSL scenarios. Various in-memory search solutions have emerged to improve the energy efficiency of MANNs. NAND-based multi-bit content addressable memory (MCAM) is a promising option due to its high density and large capacity. Despite its potential, MCAM faces limitations such as a restricted number of word lines, limited quantization levels, and non-ideal effects like varying string currents and bottleneck effects, which lead to significant accuracy drops. To address these issues, we propose several innovative methods. First, the Multi-bit Thermometer Code (MTMC) leverages the extensive capacity of MCAM to enhance vector precision using cumulative encoding rules, thereby mitigating the bottleneck effect. Second, the Asymmetric vector similarity search (AVSS) reduces the precision of the query vector while maintaining that of the support vectors, thereby minimizing the search iterations and improving efficiency in many-class scenarios. Finally, the Hardware-Aware Training (HAT) method optimizes controller training by modeling the hardware characteristics of MCAM, thus enhancing the reliability of the system. Our integrated framework reduces search iterations by up to 32 times, and increases overall accuracy by 1.58% to 6.94%.
Relay-Assisted Carrier Aggregation (RACA) Uplink System for Enhancing Data Rate of Extended Reality (XR)
Jul 02, 2024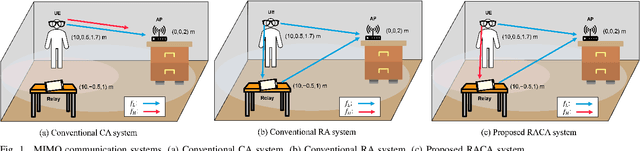
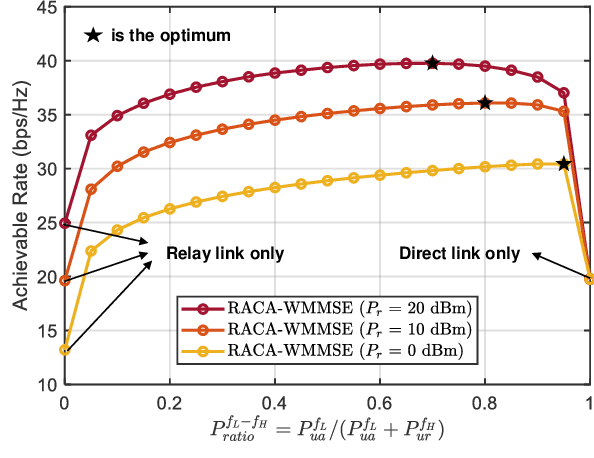
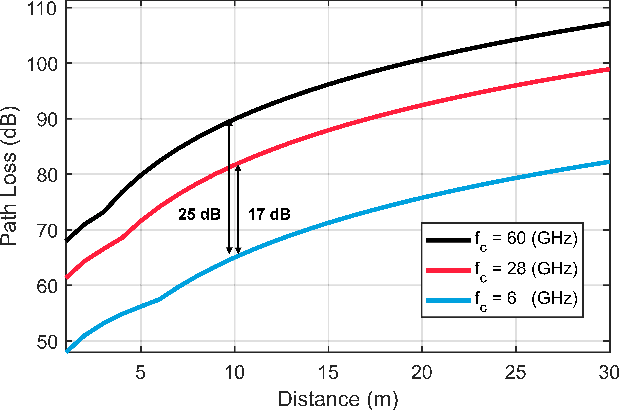
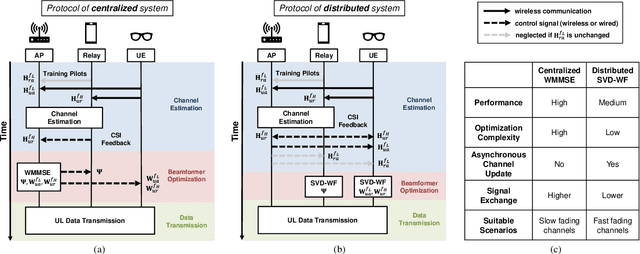
In Extended Reality (XR) applications, high data rates and low latency are crucial for immersive experiences. Uplink transmission in XR is challenging due to the limited antennas and power of lightweight XR devices. To improve data transmission rates, we investigate a relay-assisted carrier aggregation (RACA) system. The XR device simultaneously transmits data to an access point (AP) and a relay in proximity over low-frequency and high-frequency bands, respectively. Then, the relay down-converts and amplifies the signals to the AP, effectively acting as an additional transmit antenna for the XR device. In this paper, we propose two algorithms to maximize the data rate of the XR device in their respective protocols. In the centralized protocol, the rate maximization problem is equivalently transformed as a weighted mean square error minimization (WMMSE) problem which can be solved iteratively by alternative optimization. In the distributed protocol, the rate maximization problem is decomposed into two independent sub-problems where the rate of the direct link and the rate of the relay link are maximized by singular value decomposition (SVD)-based methods with water-filling (WF). Simulation results show that the rate of the RACA system is improved by $32\%$ compared to that of the conventional carrier aggregation scheme.
LATTE: Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer
Apr 11, 2024



With the rise of Transformer models in NLP and CV domain, Multi-Head Attention has been proven to be a game-changer. However, its expensive computation poses challenges to the model throughput and efficiency, especially for the long sequence tasks. Exploiting the sparsity in attention has been proven to be an effective way to reduce computation. Nevertheless, prior works do not consider the various distributions among different heads and lack a systematic method to determine the threshold. To address these challenges, we propose Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer (LATTE). LATTE employs a headwise threshold-based filter with the low-precision dot product and computation reuse mechanism to reduce the computation of MHA. Moreover, the trainable threshold is introduced to provide a systematic method for adjusting the thresholds and enable end-to-end optimization. Experimental results indicate LATTE can smoothly adapt to both NLP and CV tasks, offering significant computation savings with only a minor compromise in performance. Also, the trainable threshold is shown to be essential for the leverage between the performance and the computation. As a result, LATTE filters up to 85.16% keys with only a 0.87% accuracy drop in the CV task and 89.91% keys with a 0.86 perplexity increase in the NLP task.
MPTQ-ViT: Mixed-Precision Post-Training Quantization for Vision Transformer
Feb 01, 2024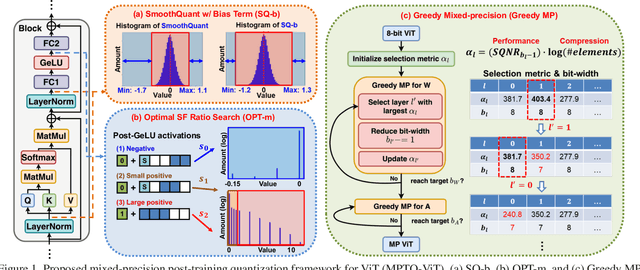
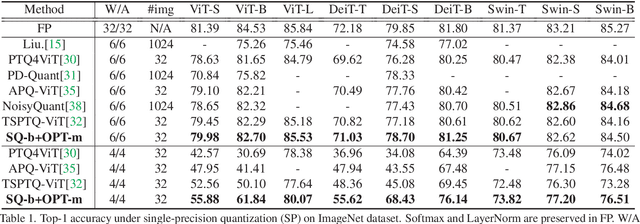
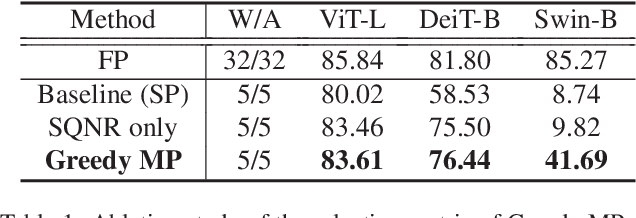
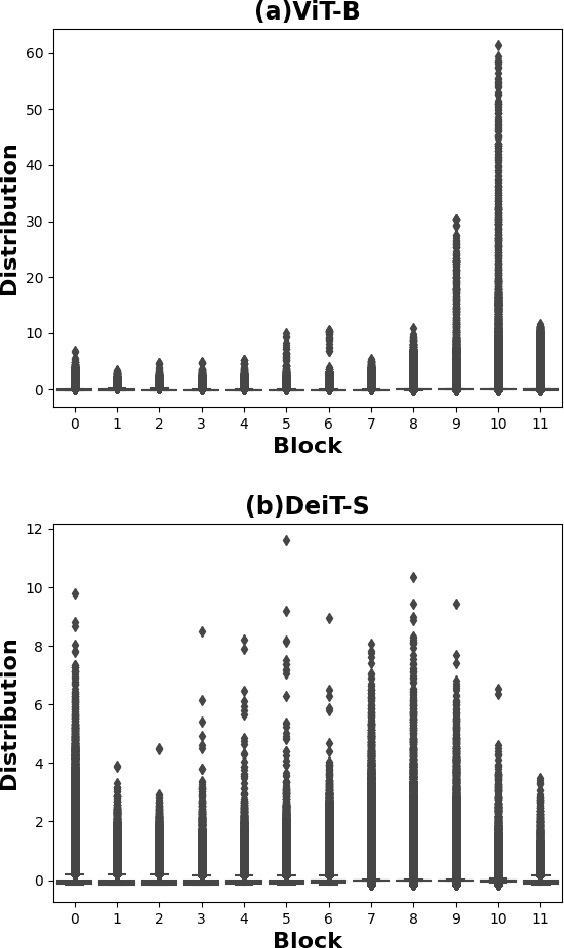
While vision transformers (ViTs) have shown great potential in computer vision tasks, their intense computation and memory requirements pose challenges for practical applications. Existing post-training quantization methods leverage value redistribution or specialized quantizers to address the non-normal distribution in ViTs. However, without considering the asymmetry in activations and relying on hand-crafted settings, these methods often struggle to maintain performance under low-bit quantization. To overcome these challenges, we introduce SmoothQuant with bias term (SQ-b) to alleviate the asymmetry issue and reduce the clamping loss. We also introduce optimal scaling factor ratio search (OPT-m) to determine quantization parameters by a data-dependent mechanism automatically. To further enhance the compressibility, we incorporate the above-mentioned techniques and propose a mixed-precision post-training quantization framework for vision transformers (MPTQ-ViT). We develop greedy mixed-precision quantization (Greedy MP) to allocate layer-wise bit-width considering both model performance and compressibility. Our experiments on ViT, DeiT, and Swin demonstrate significant accuracy improvements compared with SOTA on the ImageNet dataset. Specifically, our proposed methods achieve accuracy improvements ranging from 0.90% to 23.35% on 4-bit ViTs with single-precision and from 3.82% to 78.14% on 5-bit fully quantized ViTs with mixed-precision.
TSPTQ-ViT: Two-scaled post-training quantization for vision transformer
May 22, 2023



Vision transformers (ViTs) have achieved remarkable performance in various computer vision tasks. However, intensive memory and computation requirements impede ViTs from running on resource-constrained edge devices. Due to the non-normally distributed values after Softmax and GeLU, post-training quantization on ViTs results in severe accuracy degradation. Moreover, conventional methods fail to address the high channel-wise variance in LayerNorm. To reduce the quantization loss and improve classification accuracy, we propose a two-scaled post-training quantization scheme for vision transformer (TSPTQ-ViT). We design the value-aware two-scaled scaling factors (V-2SF) specialized for post-Softmax and post-GeLU values, which leverage the bit sparsity in non-normal distribution to save bit-widths. In addition, the outlier-aware two-scaled scaling factors (O-2SF) are introduced to LayerNorm, alleviating the dominant impacts from outlier values. Our experimental results show that the proposed methods reach near-lossless accuracy drops (<0.5%) on the ImageNet classification task under 8-bit fully quantized ViTs.
C3-SL: Circular Convolution-Based Batch-Wise Compression for Communication-Efficient Split Learning
Jul 25, 2022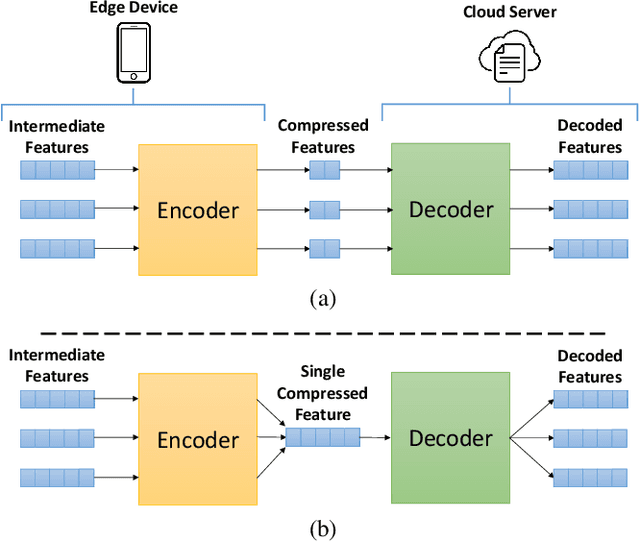


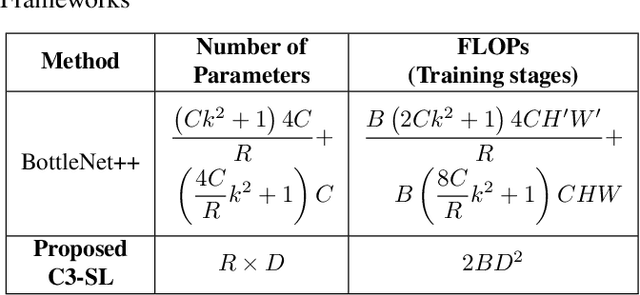
Most existing studies improve the efficiency of Split learning (SL) by compressing the transmitted features. However, most works focus on dimension-wise compression that transforms high-dimensional features into a low-dimensional space. In this paper, we propose circular convolution-based batch-wise compression for SL (C3-SL) to compress multiple features into one single feature. To avoid information loss while merging multiple features, we exploit the quasi-orthogonality of features in high-dimensional space with circular convolution and superposition. To the best of our knowledge, we are the first to explore the potential of batch-wise compression under the SL scenario. Based on the simulation results on CIFAR-10 and CIFAR-100, our method achieves a 16x compression ratio with negligible accuracy drops compared with the vanilla SL. Moreover, C3-SL significantly reduces 1152x memory and 2.25x computation overhead compared to the state-of-the-art dimension-wise compression method.
MAUS: A Dataset for Mental Workload Assessmenton N-back Task Using Wearable Sensor
Nov 03, 2021

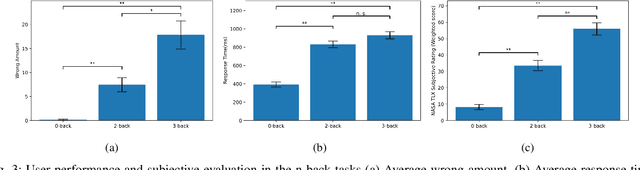
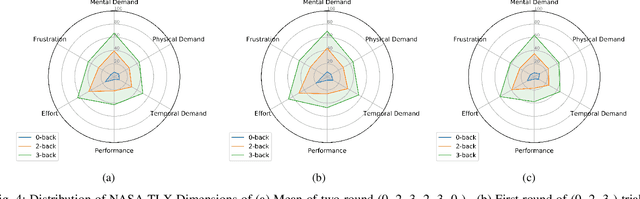
This paper describes an open-access database focusing on the study of mental workload (MW) assessment system for wearable devices. A wristband photoplethysmogram (PPG) was provided as a representative of wearable devices. In addition, a clinical device that can record Electrocardiography (ECG) , galvanic skin response (GSR) and, fingertip PPG was included in the database as a reference. The MW was induced by performing the N-back task with 22 subjects. The participants were asked to answer the Pittsburgh Sleep Quality Index (PSQI) questionnaire at the beginning of the experiment and the NASA Task Load Index (NASA-TLX) questionnaire after each N-back task. The result of data analysis show the potential uses of the recorded modalities and the feasibility of the MW elicitation protocol. Finally the MAUS dataset is now available for academic use (The MAUS dataset is available at IEEE Dataport: https://ieee-dataport.org/open-access/maus-dataset-mental-workload-assessment-n-back-task-using-wearable-sensor). Besides, we also presents a reproducible baseline system as a preliminary benchmark (The code of the baseline system on MAUS dataset is available on Github: https://github.com/rickwu11/MAUS\_dataset\_baseline\_system), which testing accuracy are 71.6 %, 66.7 %, and 59.9 % in ECG, fingertip PPG, wristband PPG, respectively.
Neural Network-Aided BCJR Algorithm for Joint Symbol Detection and Channel Decoding
May 30, 2020



Recently, deep learning-assisted communication systems have achieved many eye-catching results and attracted more and more researchers in this emerging field. Instead of completely replacing the functional blocks of communication systems with neural networks, a hybrid manner of BCJRNet symbol detection is proposed to combine the advantages of the BCJR algorithm and neural networks. However, its separate block design not only degrades the system performance but also results in additional hardware complexity. In this work, we propose a BCJR receiver for joint symbol detection and channel decoding. It can simultaneously utilize the trellis diagram and channel state information for a more accurate calculation of branch probability and thus achieve global optimum with 2.3 dB gain over separate block design. Furthermore, a dedicated neural network model is proposed to replace the channel-model-based computation of the BCJR receiver, which can avoid the requirements of perfect CSI and is more robust under CSI uncertainty with 1.0 dB gain.