 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPTQ-ViT: Mixed-Precision Post-Training Quantization for Vision Transformer
Paper and Code
Feb 01, 2024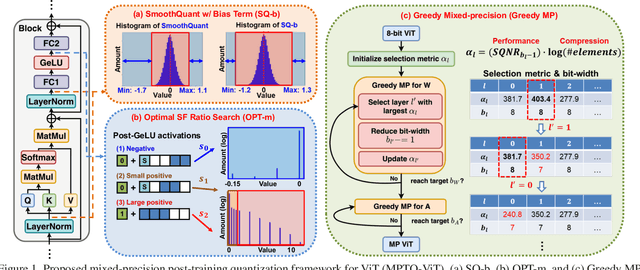
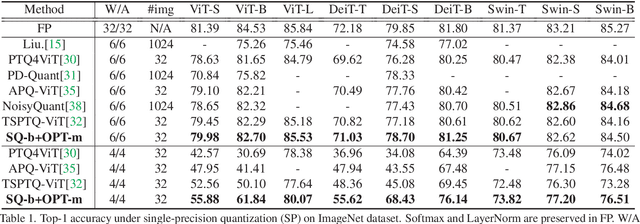
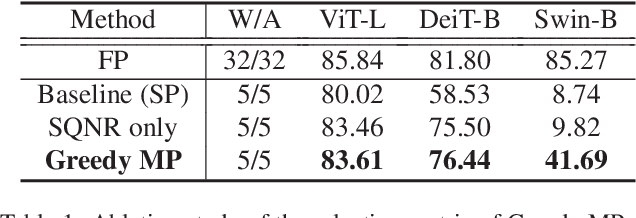
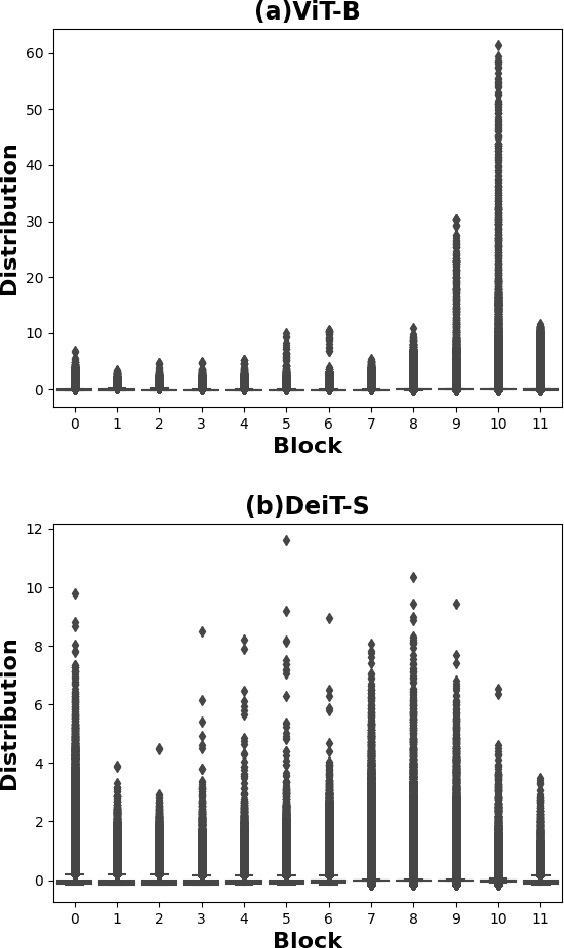
While vision transformers (ViTs) have shown great potential in computer vision tasks, their intense computation and memory requirements pose challenges for practical applications. Existing post-training quantization methods leverage value redistribution or specialized quantizers to address the non-normal distribution in ViTs. However, without considering the asymmetry in activations and relying on hand-crafted settings, these methods often struggle to maintain performance under low-bit quantization. To overcome these challenges, we introduce SmoothQuant with bias term (SQ-b) to alleviate the asymmetry issue and reduce the clamping loss. We also introduce optimal scaling factor ratio search (OPT-m) to determine quantization parameters by a data-dependent mechanism automatically. To further enhance the compressibility, we incorporate the above-mentioned techniques and propose a mixed-precision post-training quantization framework for vision transformers (MPTQ-ViT). We develop greedy mixed-precision quantization (Greedy MP) to allocate layer-wise bit-width considering both model performance and compressibility. Our experiments on ViT, DeiT, and Swin demonstrate significant accuracy improvements compared with SOTA on the ImageNet dataset. Specifically, our proposed methods achieve accuracy improvements ranging from 0.90% to 23.35% on 4-bit ViTs with single-precision and from 3.82% to 78.14% on 5-bit fully quantized ViTs with mixed-precision.