 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Quantization for Vision Mamba with k-Scaled Quantization and Reparameterization
Jan 28, 2025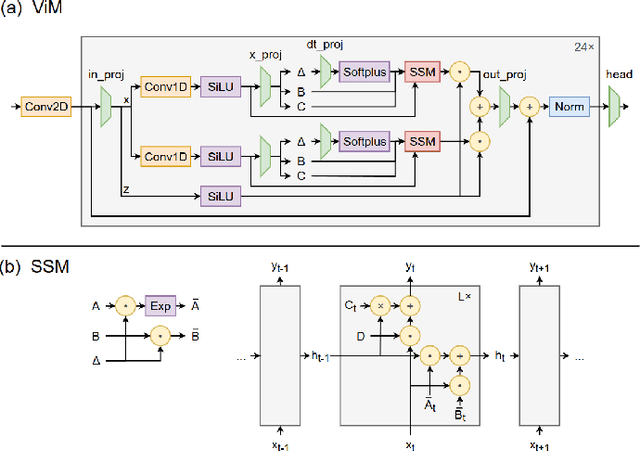
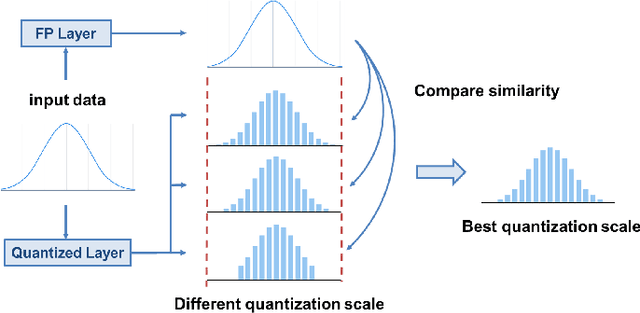
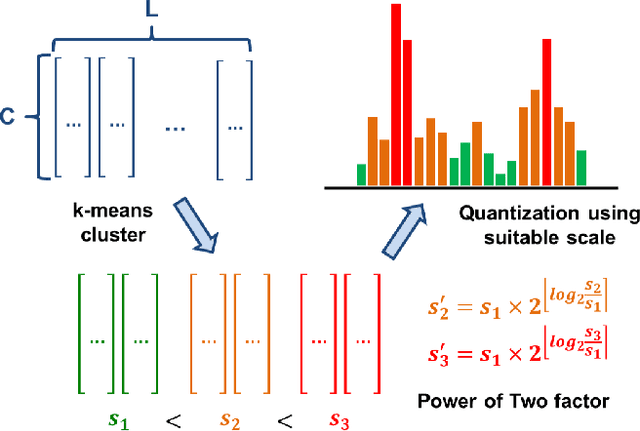
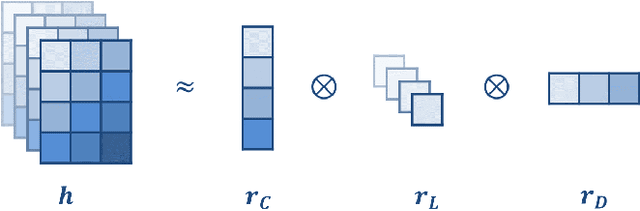
The Mamba model, utilizing a structured state-space model (SSM), offers linear time complexity and demonstrates significant potential. Vision Mamba (ViM) extends this framework to vision tasks by incorporating a bidirectional SSM and patch embedding, surpassing Transformer-based models in performance. While model quantization is essential for efficient computing, existing works have focused solely on the original Mamba model and have not been applied to ViM. Additionally, they neglect quantizing the SSM layer, which is central to Mamba and can lead to substantial error propagation by naive quantization due to its inherent structure. In this paper, we focus on the post-training quantization (PTQ) of ViM. We address the issues with three core techniques: 1) a k-scaled token-wise quantization method for linear and convolutional layers, 2) a reparameterization technique to simplify hidden state quantization, and 3) a factor-determining method that reduces computational overhead by integrating operations. Through these methods, the error caused by PTQ can be mitigated. Experimental results on ImageNet-1k demonstrate only a 0.8-1.2\% accuracy degradation due to PTQ, highlighting the effectiveness of our approach.