 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Mixed-precision and Dimension Reduction Co-design for Low-storage Activation
Jul 19, 2022
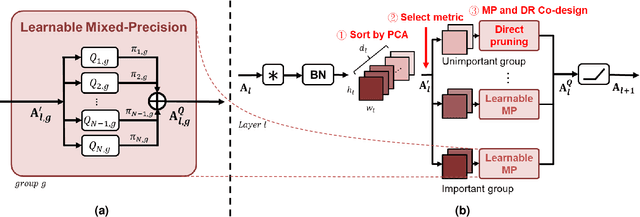

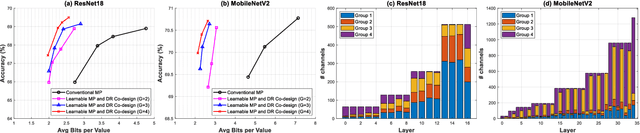
Recently, deep convolutional neural networks (CNNs) have achieved many eye-catching results. However, deploying CNNs on resource-constrained edge devices is constrained by limited memory bandwidth for transmitting large intermediated data during inference, i.e., activation. Existing research utilizes mixed-precision and dimension reduction to reduce computational complexity but pays less attention to its application for activation compression. To further exploit the redundancy in activation, we propose a learnable mixed-precision and dimension reduction co-design system, which separates channels into groups and allocates specific compression policies according to their importance. In addition, the proposed dynamic searching technique enlarges search space and finds out the optimal bit-width allocation automatically. Our experimental results show that the proposed methods improve 3.54%/1.27% in accuracy and save 0.18/2.02 bits per value over existing mixed-precision methods on ResNet18 and MobileNetv2, respectively.
Compression-aware Projection with Greedy Dimension Reduction for Convolutional Neural Network Activations
Oct 17, 2021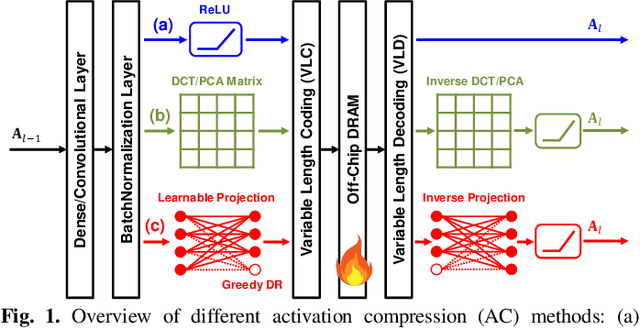
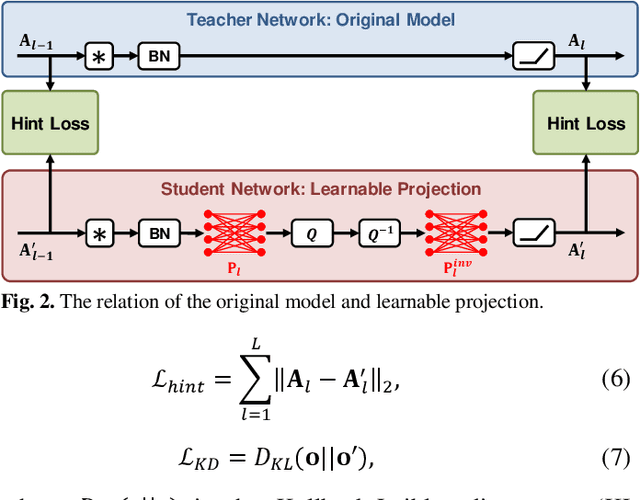
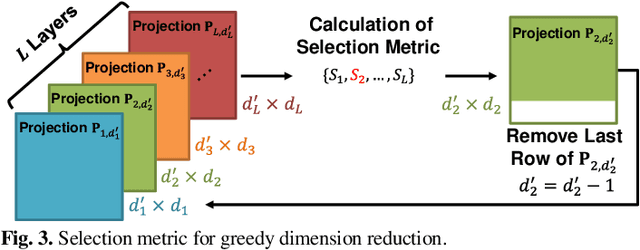
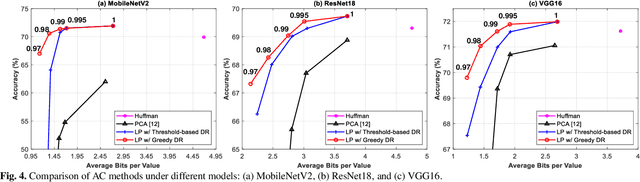
Convolutional neural networks (CNNs) achieve remarkable performance in a wide range of fields. However, intensive memory access of activations introduces considerable energy consumption, impeding deployment of CNNs on resourceconstrained edge devices. Existing works in activation compression propose to transform feature maps for higher compressibility, thus enabling dimension reduction. Nevertheless, in the case of aggressive dimension reduction, these methods lead to severe accuracy drop. To improve the trade-off between classification accuracy and compression ratio, we propose a compression-aware projection system, which employs a learnable projection to compensate for the reconstruction loss. In addition, a greedy selection metric is introduced to optimize the layer-wise compression ratio allocation by considering both accuracy and #bits reduction simultaneously. Our test results show that the proposed methods effectively reduce 2.91x~5.97x memory access with negligible accuracy drop on MobileNetV2/ResNet18/VGG16.
Neural Network-Aided BCJR Algorithm for Joint Symbol Detection and Channel Decoding
May 30, 2020



Recently, deep learning-assisted communication systems have achieved many eye-catching results and attracted more and more researchers in this emerging field. Instead of completely replacing the functional blocks of communication systems with neural networks, a hybrid manner of BCJRNet symbol detection is proposed to combine the advantages of the BCJR algorithm and neural networks. However, its separate block design not only degrades the system performance but also results in additional hardware complexity. In this work, we propose a BCJR receiver for joint symbol detection and channel decoding. It can simultaneously utilize the trellis diagram and channel state information for a more accurate calculation of branch probability and thus achieve global optimum with 2.3 dB gain over separate block design. Furthermore, a dedicated neural network model is proposed to replace the channel-model-based computation of the BCJR receiver, which can avoid the requirements of perfect CSI and is more robust under CSI uncertainty with 1.0 dB gain.
Accumulated Polar Feature-based Deep Learning for Efficient and Lightweight Automatic Modulation Classification with Channel Compensation Mechanism
Feb 07, 2020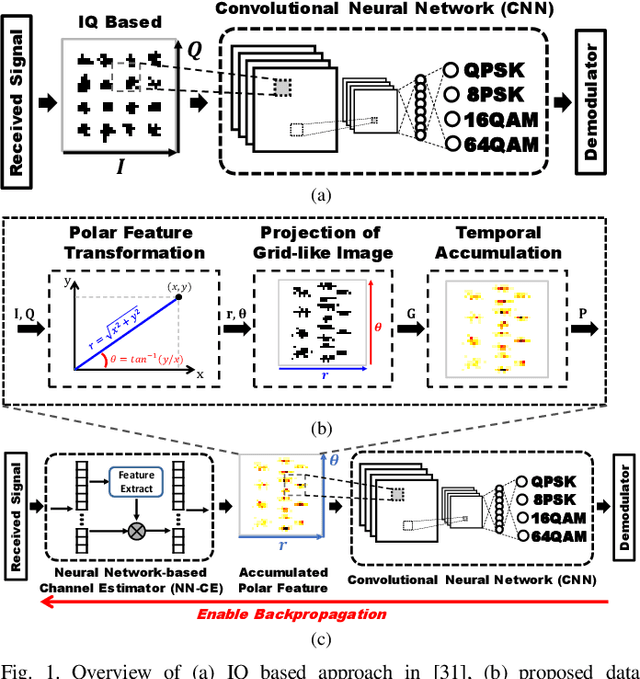
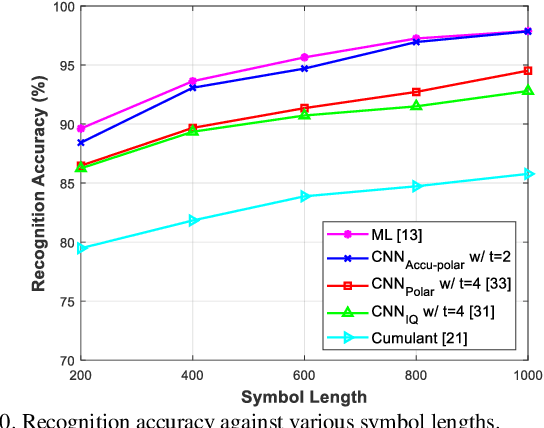


In next-generation communications, massive machine-type communications (mMTC) induce severe burden on base stations. To address such an issue, automatic modulation classification (AMC) can help to reduce signaling overhead by blindly recognizing the modulation types without handshaking. Thus, it plays an important role in future intelligent modems. The emerging deep learning (DL) technique stores intelligence in the network, resulting in superior performance over traditional approaches. However, conventional DL-based approaches suffer from heavy training overhead, memory overhead, and computational complexity, which severely hinder practical applications for resource-limited scenarios, such as Vehicle-to-Everything (V2X) applications. Furthermore, the overhead of online retraining under time-varying fading channels has not been studied in the prior arts. In this work, an accumulated polar feature-based DL with a channel compensation mechanism is proposed to cope with the aforementioned issues. Firstly, the simulation results show that learning features from the polar domain with historical data information can approach near-optimal performance while reducing training overhead by 99.8 times. Secondly, the proposed neural network-based channel estimator (NN-CE) can learn the channel response and compensate for the distorted channel with 13% improvement. Moreover, in applying this lightweight NN-CE in a time-varying fading channel, two efficient mechanisms of online retraining are proposed, which can reduce transmission overhead and retraining overhead by 90% and 76%, respectively. Finally, the performance of the proposed approach is evaluated and compared with prior arts on a public dataset to demonstrate its great efficiency and lightness.
Syndrome-Enabled Unsupervised Learning for Channel Adaptive Blind Equalizer with Joint Optimization Mechanism
Jan 06, 2020


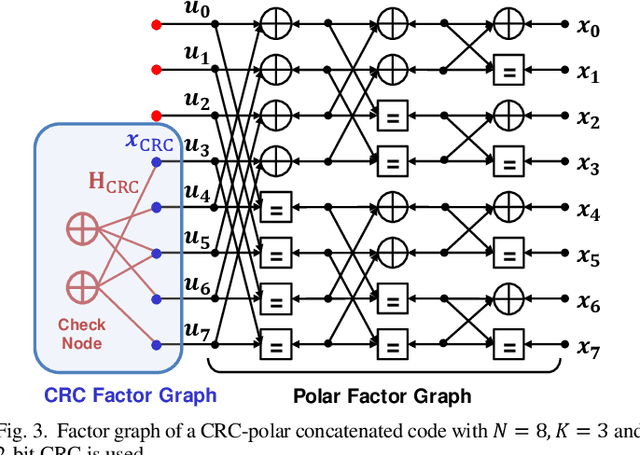
With the rapid growth of deep learning in many fields, machine learning-assisted communication systems has attracted lots of researches with many eye-catching initial results. At the present stage, most of the methods still have great demand of massive "labeled data" for supervised learning to overcome channel variation. However, obtaining labeled data in practical applications may result in severe transmission overheads, and thus degrade the spectral efficiency. To address this issue, syndrome loss has been proposed to penalize non-valid decoded codewords and to achieve unsupervised learning for neural network-based decoder. However, it has not been evaluated under varying channels and cannot be applied to polar codes directly. In this work, by exploiting the nature of polar codes and taking advantage of the standardized cyclic redundancy check (CRC) mechanism, we propose two kinds of modified syndrome loss to enable unsupervised learning for polar codes. In addition, two application scenarios that benefit from the syndrome loss are also proposed for the evaluation. From simulation results, the proposed syndrome loss can even outperform supervised learning for the training of neural network-based polar decoder. Furthermore, the proposed syndrome-enabled blind equalizer can avoid the transmission of training sequences under time-varying fading channel and achieve global optimum via joint optimization mechanism, which has 1.3 dB gain over non-blind minimum mean square error (MMSE) equalizer.
Low-Complexity LSTM-Assisted Bit-Flipping Algorithm for Successive Cancellation List Polar Decoder
Dec 11, 2019

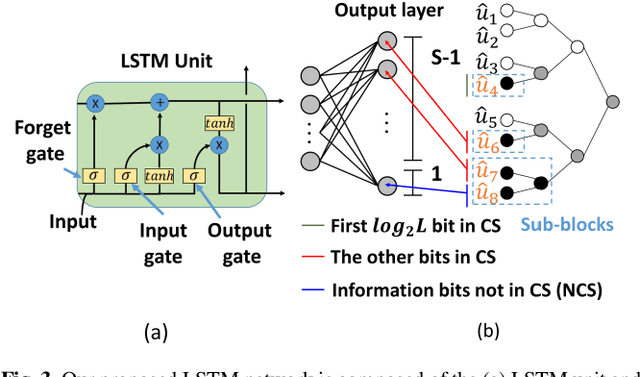

Polar codes have attracted much attention in the past decade due to their capacity-achieving performance. The higher decoding capacity is required for 5G and beyond 5G (B5G). Although the cyclic redundancy check (CRC)- assisted successive cancellation list bit-flipping (CA-SCLF) decoders have been developed to obtain a better performance, the solution to error bit correction (bit-flipping) problem is still imperfect and hard to design. In this work, we leverage the expert knowledge in communication systems and adopt deep learning (DL) technique to obtain the better solution. A low-complexity long short-term memory network (LSTM)-assisted CA-SCLF decoder is proposed to further improve the performance of conventional CA-SCLF and avoid complexity and memory overhead. Our test results show that we can effectively improve the BLER performance by 0.11dB compared to prior work and reduce the complexity and memory overhead by over 30% of the network.
Unsupervised Learning for Neural Network-based Polar Decoder via Syndrome Loss
Nov 05, 2019
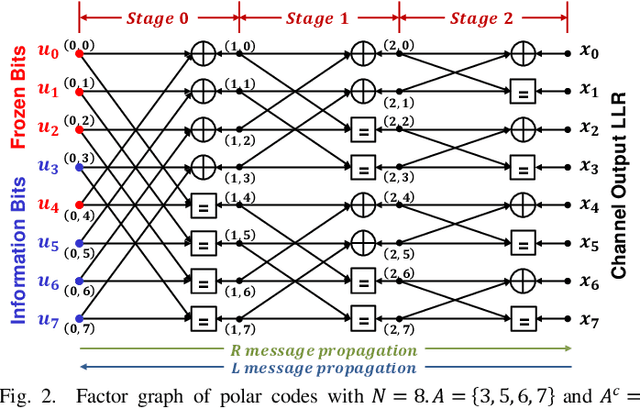


With the rapid growth of deep learning in many fields, machine learning-assisted communication systems had attracted lots of researches with many eye-catching initial results. At the present stage, most of the methods still have great demand of massive labeled data for supervised learning. However, obtaining labeled data in the practical applications is not feasible, which may result in severe performance degradation due to channel variations. To overcome such a constraint, syndrome loss has been proposed to penalize non-valid decoded codewords and achieve unsupervised learning for neural network-based decoder. However, it cannot be applied to polar decoder directly. In this work, by exploiting the nature of polar codes, we propose a modified syndrome loss. From simulation results, the proposed method demonstrates that domain-specific knowledge and know-how in code structure can enable unsupervised learning for neural network-based polar decoder.
Convolutional Neural Network-aided Bit-flipping for Belief Propagation Decoding of Polar Codes
Nov 05, 2019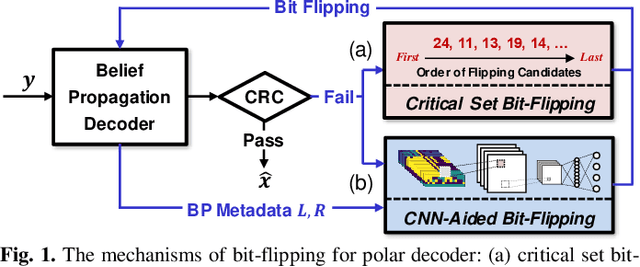
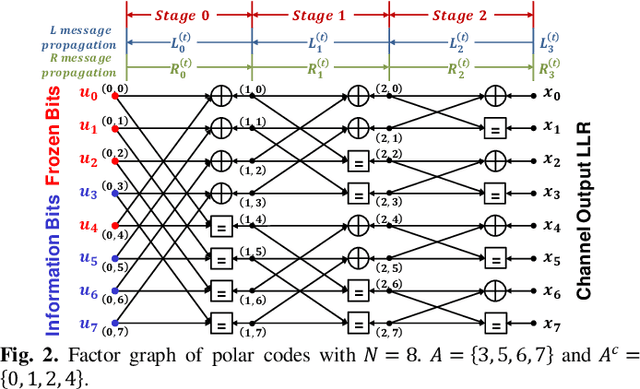
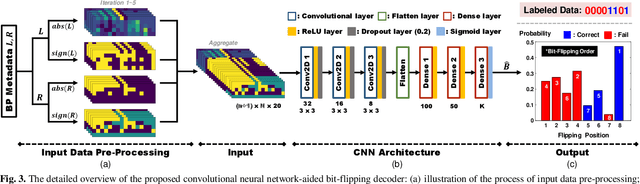
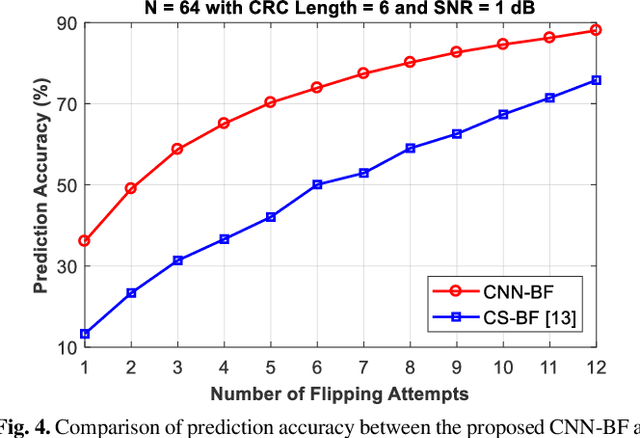
Known for their capacity-achieving abilities, polar codes have been selected as the control channel coding scheme for 5G communications. To satisfy high throughput and low latency needs, belief propagation (BP) is chosen as the decoding algorithm. However, the error performance of BP is worse than that of enhanced successive cancellation (SC). Critical-set bit-flipping (CS-BF) can be applied to BP decoding in order to lower the error rate. However, its trial and error process results in longer latency. In this work, we propose a convolutional neural network-aided bit-flipping (CNN-BF) for BP decoding of polar codes. With carefully designed input data and model architecture, it can achieve better prediction accuracy. The simulation results show that we can effectively reduce the added latency resulting from BF and achieve a lower block error rate (BLER).
Neural Network-based Equalizer by Utilizing Coding Gain in Advance
Aug 31, 2019



Recently, deep learning has been exploited in many fields with revolutionary breakthroughs. In the light of this, deep learning-assisted communication systems have also attracted much attention in recent years and have potential to break down the conventional design rule for communication systems. In this work, we propose two kinds of neural network-based equalizers to exploit different characteristics between convolutional neural networks and recurrent neural networks. The equalizer in conventional block-based design may destroy the code structure and degrade the capacity of coding gain for decoder. On the contrary, our proposed approach not only eliminates channel fading, but also exploits the code structure with utilization of coding gain in advance, which can effectively increase the overall utilization of coding gain with more than 1.5 dB gain.
Low-complexity Recurrent Neural Network-based Polar Decoder with Weight Quantization Mechanism
Oct 29, 2018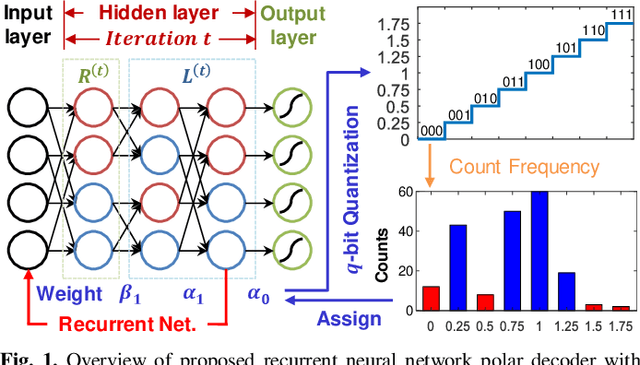
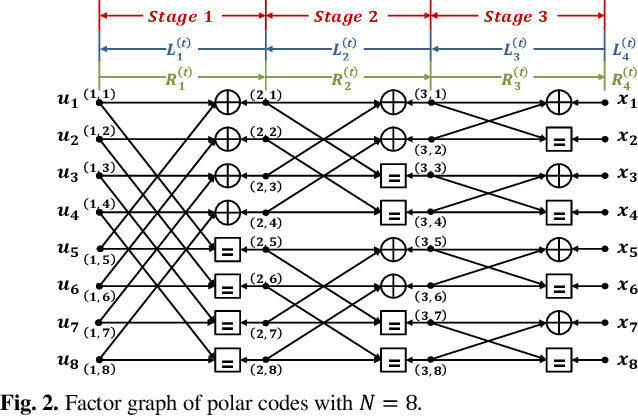
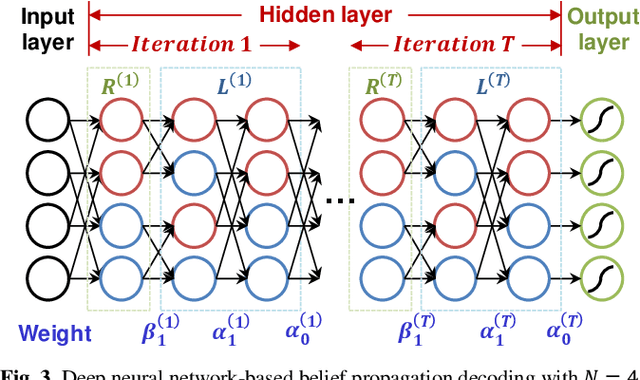
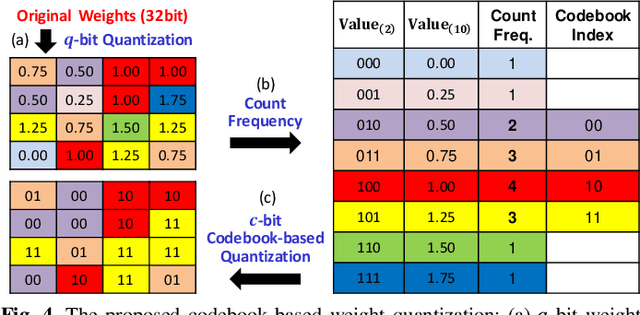
Polar codes have drawn much attention and been adopted in 5G New Radio (NR) due to their capacity-achieving performance. Recently, as the emerging deep learning (DL) technique has breakthrough achievements in many fields, neural network decoder was proposed to obtain faster convergence and better performance than belief propagation (BP) decoding. However, neural networks are memory-intensive and hinder the deployment of DL in communication systems. In this work, a low-complexity recurrent neural network (RNN) polar decoder with codebook-based weight quantization is proposed. Our test results show that we can effectively reduce the memory overhead by 98% and alleviate computational complexity with slight performance loss.