 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Reliable Vector Similarity Search Using Asymmetric Encoding with NAND-Flash for Many-Class Few-Shot Learning
Sep 12, 2024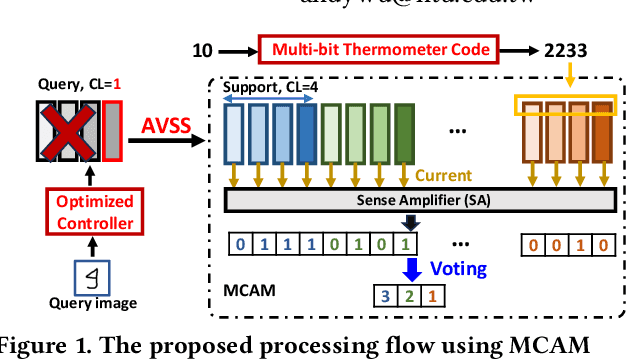
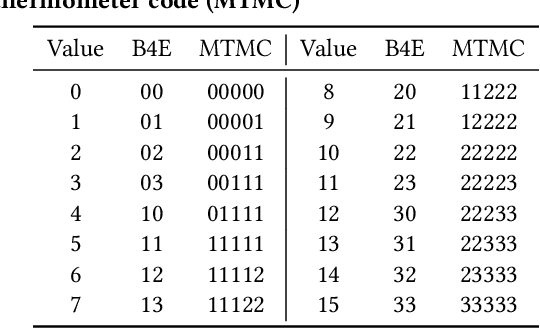
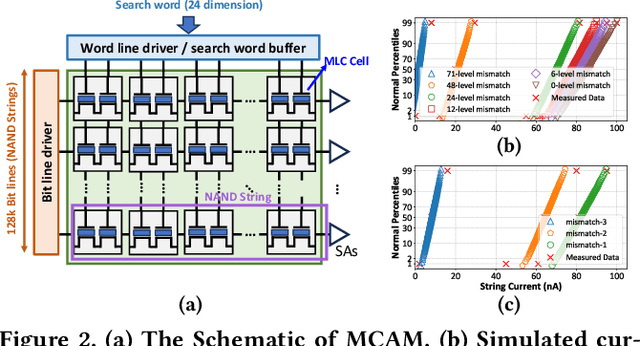
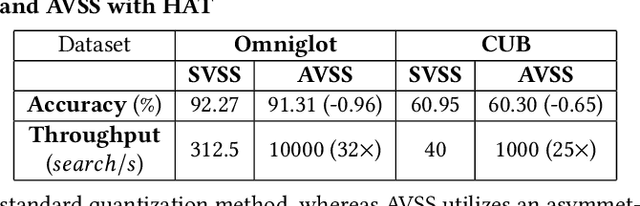
While memory-augmented neural networks (MANNs) offer an effective solution for few-shot learning (FSL) by integrating deep neural networks with external memory, the capacity requirements and energy overhead of data movement become enormous due to the large number of support vectors in many-class FSL scenarios. Various in-memory search solutions have emerged to improve the energy efficiency of MANNs. NAND-based multi-bit content addressable memory (MCAM) is a promising option due to its high density and large capacity. Despite its potential, MCAM faces limitations such as a restricted number of word lines, limited quantization levels, and non-ideal effects like varying string currents and bottleneck effects, which lead to significant accuracy drops. To address these issues, we propose several innovative methods. First, the Multi-bit Thermometer Code (MTMC) leverages the extensive capacity of MCAM to enhance vector precision using cumulative encoding rules, thereby mitigating the bottleneck effect. Second, the Asymmetric vector similarity search (AVSS) reduces the precision of the query vector while maintaining that of the support vectors, thereby minimizing the search iterations and improving efficiency in many-class scenarios. Finally, the Hardware-Aware Training (HAT) method optimizes controller training by modeling the hardware characteristics of MCAM, thus enhancing the reliability of the system. Our integrated framework reduces search iterations by up to 32 times, and increases overall accuracy by 1.58% to 6.94%.
Efficient and Robust Parallel DNN Training through Model Parallelism on Multi-GPU Platform
Oct 16, 2018



The training process of Deep Neural Network (DNN) is compute-intensive, often taking days to weeks to train a DNN model. Therefore, parallel execution of DNN training on GPUs is a widely adopted approach to speed up process nowadays. Due to the implementation simplicity, data parallelism is currently the most commonly used parallelization method. Nonetheless, data parallelism suffers from excessive inter-GPU communication overhead due to frequent weight synchronization among GPUs. Another approach is model parallelism, which partitions model among GPUs. This approach can significantly reduce inter-GPU communication cost compared to data parallelism, however, maintaining load balance is a challenge. Moreover, model parallelism faces the staleness issue; that is, gradients are computed with stale weights. In this paper, we propose a novel model parallelism method, which achieves load balance by concurrently executing forward and backward passes of two batches, and resolves the staleness issue with weight prediction. The experimental results show that our proposal achieves up to 15.77x speedup compared to data parallelism and up to 2.18x speedup compared to the state-of-the-art model parallelism method without incurring accuracy loss.
LIRS: Enabling efficient machine learning on NVM-based storage via a lightweight implementation of random shuffling
Oct 10, 2018



Machine learning algorithms, such as Support Vector Machine (SVM) and Deep Neural Network (DNN), have gained a lot of interests recently. When training a machine learning algorithm, randomly shuffle all the training data can improve the testing accuracy and boost the convergence rate. Nevertheless, realizing training data random shuffling in a real system is not a straightforward process due to the slow random accesses in hard disk drive (HDD). To avoid frequent random disk access, the effect of random shuffling is often limited in existing approaches. With the emerging non-volatile memory-based storage device, such as Intel Optane SSD, which provides fast random accesses, we propose a lightweight implementation of random shuffling (LIRS) to randomly shuffle the indexes of the entire training dataset, and the selected training instances are directly accessed from the storage and packed into batches. Experimental results show that LIRS can reduce the total training time of SVM and DNN by 49.9% and 43.5% on average, and improve the final testing accuracy on DNN by 1.01%.