 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDRM3: A Dynamic Scheduler for Dynamic Real-time Multi-model ML Workloads
Dec 07, 2022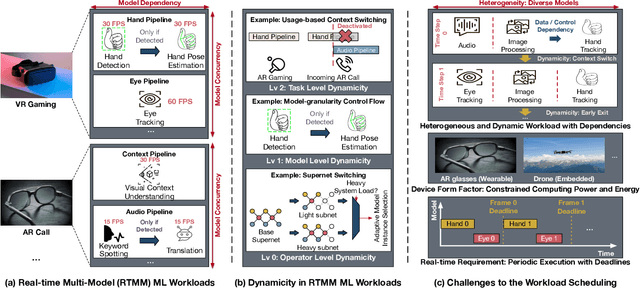
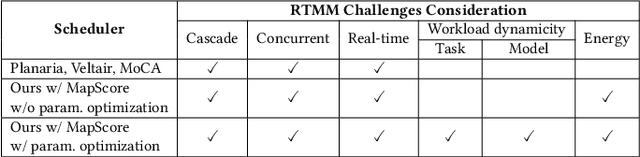
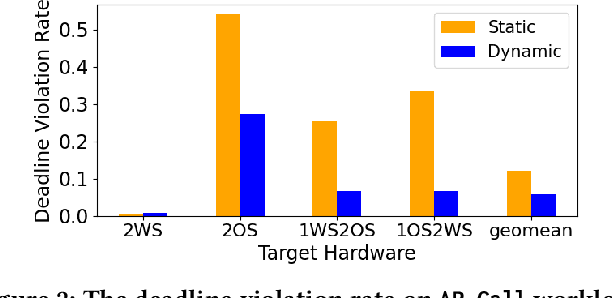
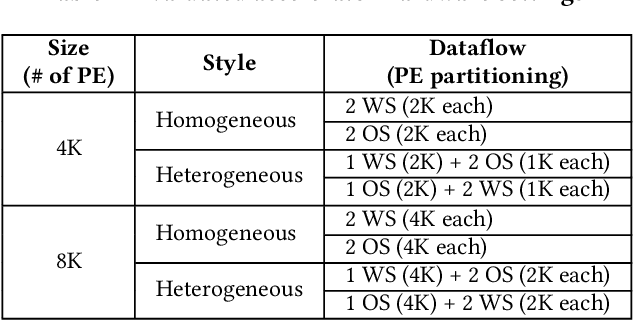
Emerging real-time multi-model ML (RTMM) workloads such as AR/VR and drone control often involve dynamic behaviors in various levels; task, model, and layers (or, ML operators) within a model. Such dynamic behaviors are new challenges to the system software in an ML system because the overall system load is unpredictable unlike traditional ML workloads. Also, the real-time processing requires to meet deadlines, and multi-model workloads involve highly heterogeneous models. As RTMM workloads often run on resource-constrained devices (e.g., VR headset), developing an effective scheduler is an important research problem. Therefore, we propose a new scheduler, SDRM3, that effectively handles various dynamicity in RTMM style workloads targeting multi-accelerator systems. To make scheduling decisions, SDRM3 quantifies the unique requirements for RTMM workloads and utilizes the quantified scores to drive scheduling decisions, considering the current system load and other inference jobs on different models and input frames. SDRM3 has tunable parameters that provide fast adaptivity to dynamic workload changes based on a gradient descent-like online optimization, which typically converges within five steps for new workloads. In addition, we also propose a method to exploit model level dynamicity based on Supernet for exploiting the trade-off between the scheduling effectiveness and model performance (e.g., accuracy), which dynamically selects a proper sub-network in a Supernet based on the system loads. In our evaluation on five realistic RTMM workload scenarios, SDRM3 reduces the overall UXCost, which is a energy-delay-product (EDP)-equivalent metric for real-time applications defined in the paper, by 37.7% and 53.2% on geometric mean (up to 97.6% and 97.1%) compared to state-of-the-art baselines, which shows the efficacy of our scheduling methodology.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022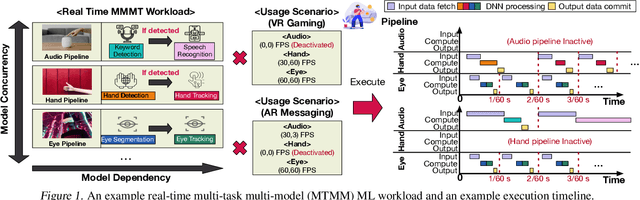
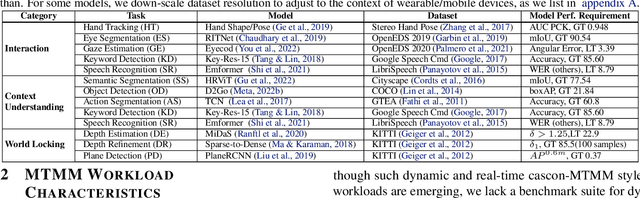

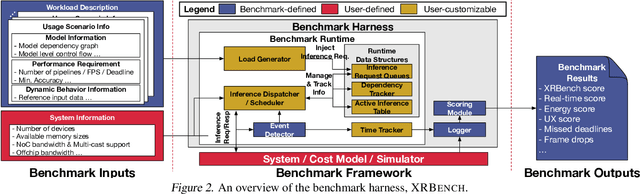
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.