 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiWaves Reinforcement Learning Algorithm
Aug 27, 2024



The escalating prevalence of cannabis use poses a significant public health challenge globally. In the U.S., cannabis use is more prevalent among emerging adults (EAs) (ages 18-25) than any other age group, with legalization in the multiple states contributing to a public perception that cannabis is less risky than in prior decades. To address this growing concern, we developed MiWaves, a reinforcement learning (RL) algorithm designed to optimize the delivery of personalized intervention prompts to reduce cannabis use among EAs. MiWaves leverages domain expertise and prior data to tailor the likelihood of delivery of intervention messages. This paper presents a comprehensive overview of the algorithm's design, including key decisions and experimental outcomes. The finalized MiWaves RL algorithm was deployed in a clinical trial from March to May 2024.
reBandit: Random Effects based Online RL algorithm for Reducing Cannabis Use
Feb 27, 2024



The escalating prevalence of cannabis use, and associated cannabis-use disorder (CUD), poses a significant public health challenge globally. With a notably wide treatment gap, especially among emerging adults (EAs; ages 18-25), addressing cannabis use and CUD remains a pivotal objective within the 2030 United Nations Agenda for Sustainable Development Goals (SDG). In this work, we develop an online reinforcement learning (RL) algorithm called reBandit which will be utilized in a mobile health study to deliver personalized mobile health interventions aimed at reducing cannabis use among EAs. reBandit utilizes random effects and informative Bayesian priors to learn quickly and efficiently in noisy mobile health environments. Moreover, reBandit employs Empirical Bayes and optimization techniques to autonomously update its hyper-parameters online. To evaluate the performance of our algorithm, we construct a simulation testbed using data from a prior study, and compare against commonly used algorithms in mobile health studies. We show that reBandit performs equally well or better than all the baseline algorithms, and the performance gap widens as population heterogeneity increases in the simulation environment, proving its adeptness to adapt to diverse population of study participants.
ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design
Jun 15, 2023Machine learning is a prevalent approach to tame the complexity of design space exploration for domain-specific architectures. Using ML for design space exploration poses challenges. First, it's not straightforward to identify the suitable algorithm from an increasing pool of ML methods. Second, assessing the trade-offs between performance and sample efficiency across these methods is inconclusive. Finally, lack of a holistic framework for fair, reproducible, and objective comparison across these methods hinders progress of adopting ML-aided architecture design space exploration and impedes creating repeatable artifacts. To mitigate these challenges, we introduce ArchGym, an open-source gym and easy-to-extend framework that connects diverse search algorithms to architecture simulators. To demonstrate utility, we evaluate ArchGym across multiple vanilla and domain-specific search algorithms in designing custom memory controller, deep neural network accelerators, and custom SoC for AR/VR workloads, encompassing over 21K experiments. Results suggest that with unlimited samples, ML algorithms are equally favorable to meet user-defined target specification if hyperparameters are tuned; no solution is necessarily better than another (e.g., reinforcement learning vs. Bayesian methods). We coin the term hyperparameter lottery to describe the chance for a search algorithm to find an optimal design provided meticulously selected hyperparameters. The ease of data collection and aggregation in ArchGym facilitates research in ML-aided architecture design space exploration. As a case study, we show this advantage by developing a proxy cost model with an RMSE of 0.61% that offers a 2,000-fold reduction in simulation time. Code and data for ArchGym is available at https://bit.ly/ArchGym.
Did we personalize? Assessing personalization by an online reinforcement learning algorithm using resampling
Apr 24, 2023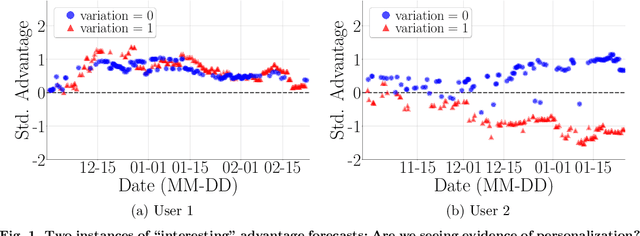
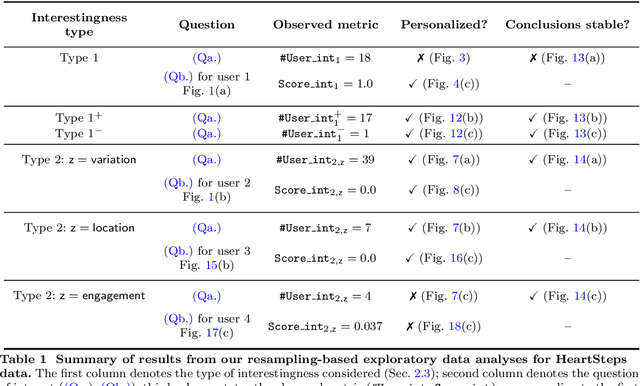
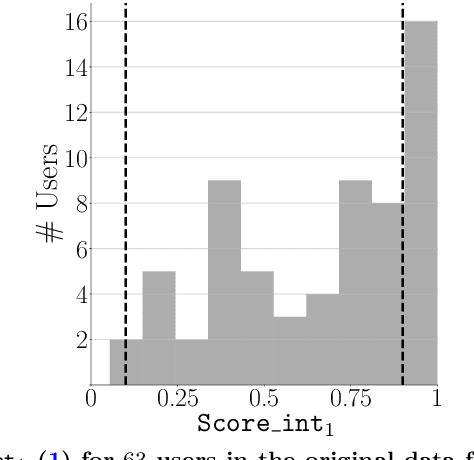
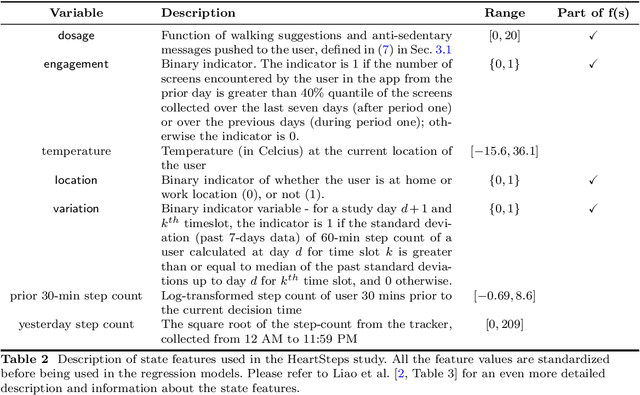
There is a growing interest in using reinforcement learning (RL) to personalize sequences of treatments in digital health to support users in adopting healthier behaviors. Such sequential decision-making problems involve decisions about when to treat and how to treat based on the user's context (e.g., prior activity level, location, etc.). Online RL is a promising data-driven approach for this problem as it learns based on each user's historical responses and uses that knowledge to personalize these decisions. However, to decide whether the RL algorithm should be included in an ``optimized'' intervention for real-world deployment, we must assess the data evidence indicating that the RL algorithm is actually personalizing the treatments to its users. Due to the stochasticity in the RL algorithm, one may get a false impression that it is learning in certain states and using this learning to provide specific treatments. We use a working definition of personalization and introduce a resampling-based methodology for investigating whether the personalization exhibited by the RL algorithm is an artifact of the RL algorithm stochasticity. We illustrate our methodology with a case study by analyzing the data from a physical activity clinical trial called HeartSteps, which included the use of an online RL algorithm. We demonstrate how our approach enhances data-driven truth-in-advertising of algorithm personalization both across all users as well as within specific users in the study.
Fairness for Workers Who Pull the Arms: An Index Based Policy for Allocation of Restless Bandit Tasks
Mar 01, 2023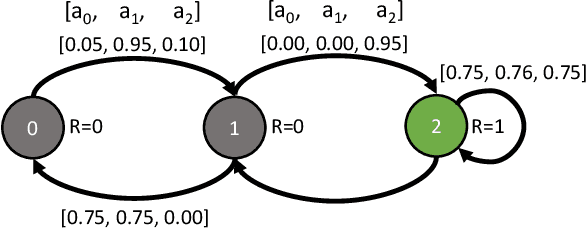
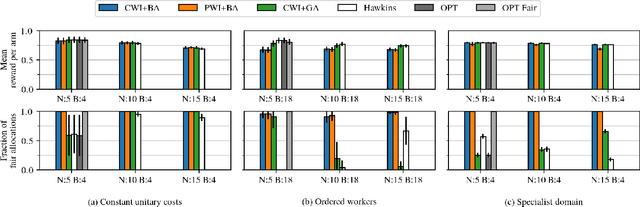
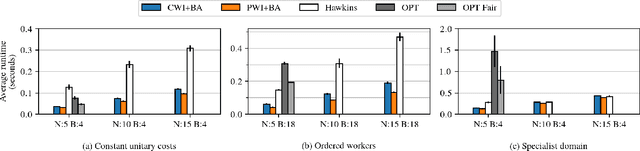
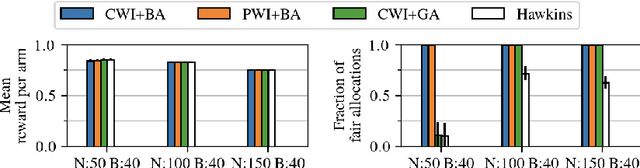
Motivated by applications such as machine repair, project monitoring, and anti-poaching patrol scheduling, we study intervention planning of stochastic processes under resource constraints. This planning problem has previously been modeled as restless multi-armed bandits (RMAB), where each arm is an intervention-dependent Markov Decision Process. However, the existing literature assumes all intervention resources belong to a single uniform pool, limiting their applicability to real-world settings where interventions are carried out by a set of workers, each with their own costs, budgets, and intervention effects. In this work, we consider a novel RMAB setting, called multi-worker restless bandits (MWRMAB) with heterogeneous workers. The goal is to plan an intervention schedule that maximizes the expected reward while satisfying budget constraints on each worker as well as fairness in terms of the load assigned to each worker. Our contributions are two-fold: (1) we provide a multi-worker extension of the Whittle index to tackle heterogeneous costs and per-worker budget and (2) we develop an index-based scheduling policy to achieve fairness. Further, we evaluate our method on various cost structures and show that our method significantly outperforms other baselines in terms of fairness without sacrificing much in reward accumulated.
Facilitating human-wildlife cohabitation through conflict prediction
Sep 22, 2021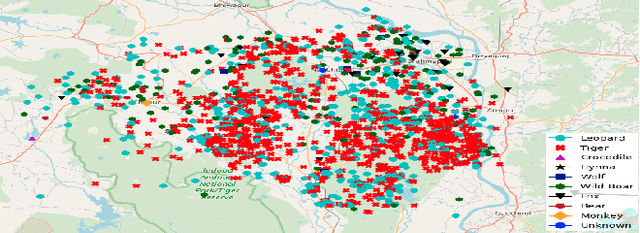
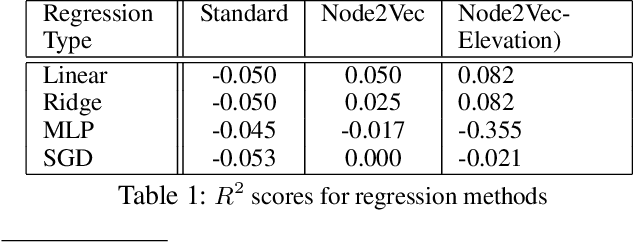
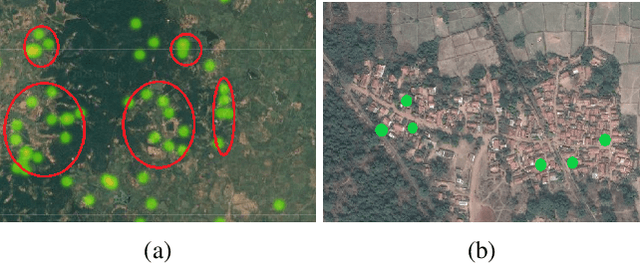
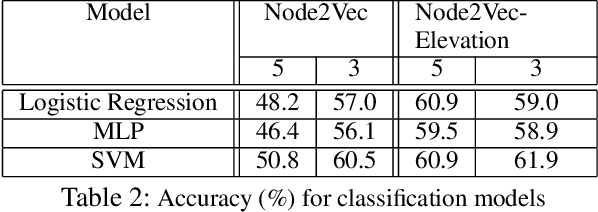
With increasing world population and expanded use of forests as cohabited regions, interactions and conflicts with wildlife are increasing, leading to large-scale loss of lives (animal and human) and livelihoods (economic). While community knowledge is valuable, forest officials and conservation organisations can greatly benefit from predictive analysis of human-wildlife conflict, leading to targeted interventions that can potentially help save lives and livelihoods. However, the problem of prediction is a complex socio-technical problem in the context of limited data in low-resource regions. Identifying the "right" features to make accurate predictions of conflicts at the required spatial granularity using a sparse conflict training dataset} is the key challenge that we address in this paper. Specifically, we do an illustrative case study on human-wildlife conflicts in the Bramhapuri Forest Division in Chandrapur, Maharashtra, India. Most existing work has considered human-wildlife conflicts in protected areas and to the best of our knowledge, this is the first effort at prediction of human-wildlife conflicts in unprotected areas and using those predictions for deploying interventions on the ground.