 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDA: Reward Design Agent for Reinforcement Learning
Jun 01, 2026Reinforcement learning has enabled the acquisition of impressive robotic skills, but typically requires hand-crafted reward functions that are slow to design and difficult to align with human intentions. Recent work, such as Eureka, automates reward design by using an LLM to iteratively generate and refine reward code from task descriptions. However, they rely on coarse feedback signals such as success rate, which provide little semantic insight into the learned behavior. As a result, their trained policies achieve the final goal but are frequently poorly aligned with task instructions. We introduce the Reward Design Agent (RDA), a VLM-based agentic framework that injects semantic understanding into reward design. RDA decomposes tasks, visually evaluates trajectories, summarizes failure modes, and iteratively revises reward code to better align with task instructions. Across 12 tabletop manipulation tasks from ManiSkill and 4 whole-body manipulation tasks from HumanoidBench, RDA produces policies substantially more instruction-aligned than those of other baselines, while achieving comparable task success rates. Videos and the generated reward code are available on https://nitinkamra1992.github.io/reward-design-agent.
Spatial-frequency channels, shape bias, and adversarial robustness
Sep 22, 2023What spatial frequency information do humans and neural networks use to recognize objects? In neuroscience, critical band masking is an established tool that can reveal the frequency-selective filters used for object recognition. Critical band masking measures the sensitivity of recognition performance to noise added at each spatial frequency. Existing critical band masking studies show that humans recognize periodic patterns (gratings) and letters by means of a spatial-frequency filter (or "channel'') that has a frequency bandwidth of one octave (doubling of frequency). Here, we introduce critical band masking as a task for network-human comparison and test 14 humans and 76 neural networks on 16-way ImageNet categorization in the presence of narrowband noise. We find that humans recognize objects in natural images using the same one-octave-wide channel that they use for letters and gratings, making it a canonical feature of human object recognition. On the other hand, the neural network channel, across various architectures and training strategies, is 2-4 times as wide as the human channel. In other words, networks are vulnerable to high and low frequency noise that does not affect human performance. Adversarial and augmented-image training are commonly used to increase network robustness and shape bias. Does this training align network and human object recognition channels? Three network channel properties (bandwidth, center frequency, peak noise sensitivity) correlate strongly with shape bias (53% variance explained) and with robustness of adversarially-trained networks (74% variance explained). Adversarial training increases robustness but expands the channel bandwidth even further away from the human bandwidth. Thus, critical band masking reveals that the network channel is more than twice as wide as the human channel, and that adversarial training only increases this difference.
SATBench: Benchmarking the speed-accuracy tradeoff in object recognition by humans and dynamic neural networks
Jun 16, 2022
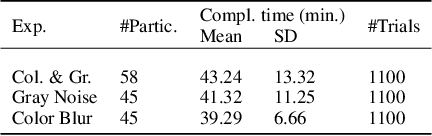
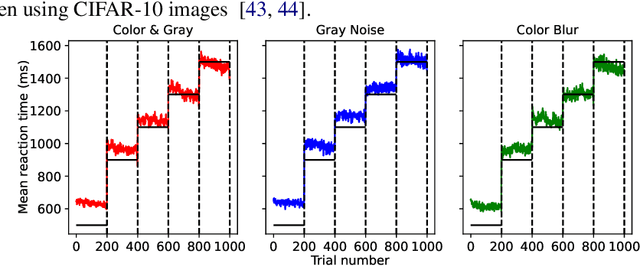
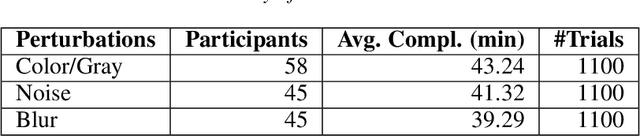
The core of everyday tasks like reading and driving is active object recognition. Attempts to model such tasks are currently stymied by the inability to incorporate time. People show a flexible tradeoff between speed and accuracy and this tradeoff is a crucial human skill. Deep neural networks have emerged as promising candidates for predicting peak human object recognition performance and neural activity. However, modeling the temporal dimension i.e., the speed-accuracy tradeoff (SAT), is essential for them to serve as useful computational models for how humans recognize objects. To this end, we here present the first large-scale (148 observers, 4 neural networks, 8 tasks) dataset of the speed-accuracy tradeoff (SAT) in recognizing ImageNet images. In each human trial, a beep, indicating the desired reaction time, sounds at a fixed delay after the image is presented, and observer's response counts only if it occurs near the time of the beep. In a series of blocks, we test many beep latencies, i.e., reaction times. We observe that human accuracy increases with reaction time and proceed to compare its characteristics with the behavior of several dynamic neural networks that are capable of inference-time adaptive computation. Using FLOPs as an analog for reaction time, we compare networks with humans on curve-fit error, category-wise correlation, and curve steepness, and conclude that cascaded dynamic neural networks are a promising model of human reaction time in object recognition tasks.
Psychological and Neural Evidence for Reinforcement Learning: A Survey
Jun 25, 2020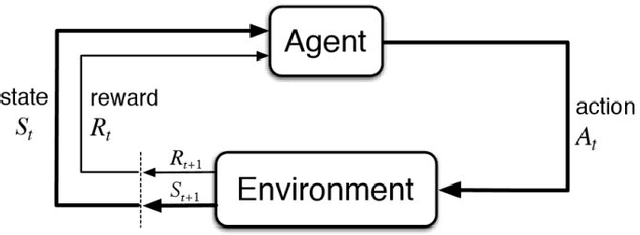
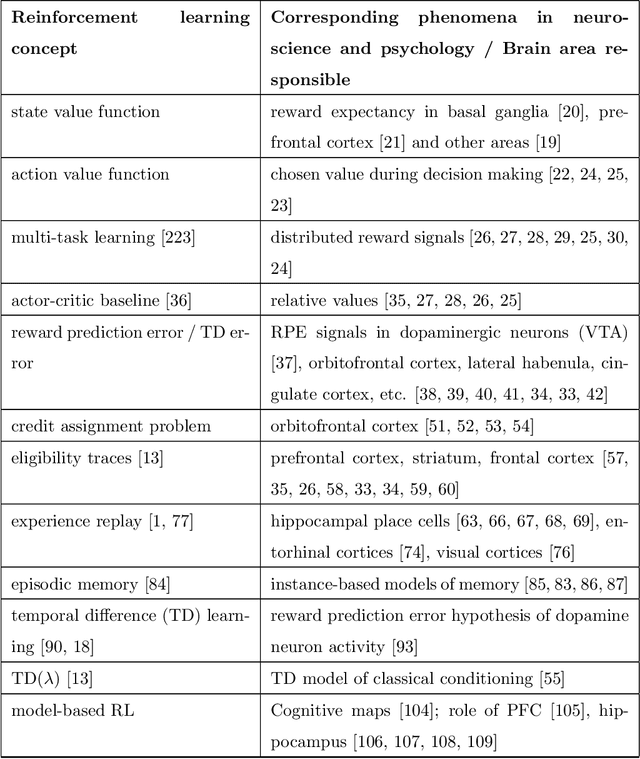
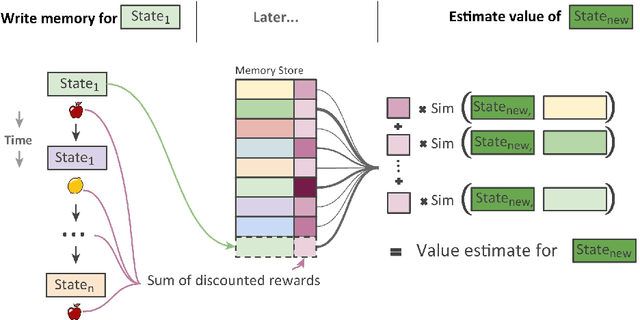
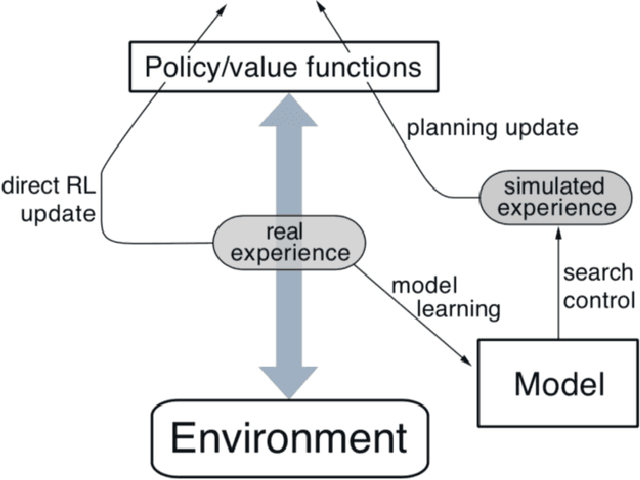
Reinforcement learning methods have been recently been very successful in complex sequential tasks like playing Atari games, Go and Poker. Through minimal input from humans, these algorithms are able to learn to perform complex tasks from scratch, just through interaction with their environment. While there certainly has been considerable independent innovation in the area, many core ideas in RL are inspired by animal learning and psychology. Moreover, these algorithms are now helping advance neuroscience research by serving as a computational model for many characteristic features of brain functioning. In this context, we review a number of findings that establish evidence of key elements of the RL problem and solution being represented in regions of the brain.