 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunky Post-Training: Data Driven Failures of Generalization
Feb 05, 2026LLM post-training involves many diverse datasets, each targeting a specific behavior. But these datasets encode incidental patterns alongside intended ones: correlations between formatting and content, narrow phrasings across diverse problems, and implicit associations arising from the discrete data curation process. These patterns are often invisible to developers yet salient to models, producing behaviors that surprise their creators, such as rejecting true facts presented in a particular question format. We call this chunky post-training: the model learns spurious correlations as a result of distinct chunks of post-training data. We introduce SURF, a black-box pipeline which surfaces these unintended behaviors at run time, and TURF, a tool that traces these failures back to specific post-training data. Applying these tools to frontier models (Claude 4.5, GPT-5.1, Grok 4.1, Gemini 3) and open models (Tülu 3), we show that chunky post-training produces miscalibrated behaviors, which often result from imbalanced or underspecified chunks of post-training data.
How Do Large Language Monkeys Get Their Power (Laws)?
Feb 24, 2025



Recent research across mathematical problem solving, proof assistant programming and multimodal jailbreaking documents a striking finding: when (multimodal) language model tackle a suite of tasks with multiple attempts per task -- succeeding if any attempt is correct -- then the negative log of the average success rate scales a power law in the number of attempts. In this work, we identify an apparent puzzle: a simple mathematical calculation predicts that on each problem, the failure rate should fall exponentially with the number of attempts. We confirm this prediction empirically, raising a question: from where does aggregate polynomial scaling emerge? We then answer this question by demonstrating per-problem exponential scaling can be made consistent with aggregate polynomial scaling if the distribution of single-attempt success probabilities is heavy tailed such that a small fraction of tasks with extremely low success probabilities collectively warp the aggregate success trend into a power law - even as each problem scales exponentially on its own. We further demonstrate that this distributional perspective explains previously observed deviations from power law scaling, and provides a simple method for forecasting the power law exponent with an order of magnitude lower relative error, or equivalently, ${\sim}2-4$ orders of magnitude less inference compute. Overall, our work contributes to a better understanding of how neural language model performance improves with scaling inference compute and the development of scaling-predictable evaluations of (multimodal) language models.
Best-of-N Jailbreaking
Dec 04, 2024



We introduce Best-of-N (BoN) Jailbreaking, a simple black-box algorithm that jailbreaks frontier AI systems across modalities. BoN Jailbreaking works by repeatedly sampling variations of a prompt with a combination of augmentations - such as random shuffling or capitalization for textual prompts - until a harmful response is elicited. We find that BoN Jailbreaking achieves high attack success rates (ASRs) on closed-source language models, such as 89% on GPT-4o and 78% on Claude 3.5 Sonnet when sampling 10,000 augmented prompts. Further, it is similarly effective at circumventing state-of-the-art open-source defenses like circuit breakers. BoN also seamlessly extends to other modalities: it jailbreaks vision language models (VLMs) such as GPT-4o and audio language models (ALMs) like Gemini 1.5 Pro, using modality-specific augmentations. BoN reliably improves when we sample more augmented prompts. Across all modalities, ASR, as a function of the number of samples (N), empirically follows power-law-like behavior for many orders of magnitude. BoN Jailbreaking can also be composed with other black-box algorithms for even more effective attacks - combining BoN with an optimized prefix attack achieves up to a 35% increase in ASR. Overall, our work indicates that, despite their capability, language models are sensitive to seemingly innocuous changes to inputs, which attackers can exploit across modalities.
Future Events as Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs
Jul 04, 2024Backdoors are hidden behaviors that are only triggered once an AI system has been deployed. Bad actors looking to create successful backdoors must design them to avoid activation during training and evaluation. Since data used in these stages often only contains information about events that have already occurred, a component of a simple backdoor trigger could be a model recognizing data that is in the future relative to when it was trained. Through prompting experiments and by probing internal activations, we show that current large language models (LLMs) can distinguish past from future events, with probes on model activations achieving $90\%$ accuracy. We train models with backdoors triggered by a temporal distributional shift; they activate when the model is exposed to news headlines beyond their training cut-off dates. Fine-tuning on helpful, harmless and honest (HHH) data does not work well for removing simpler backdoor triggers but is effective on our backdoored models, although this distinction is smaller for the larger-scale model we tested. We also find that an activation-steering vector representing a model's internal representation of the date influences the rate of backdoor activation. We take these results as initial evidence that, at least for models at the modest scale we test, standard safety measures are enough to remove these backdoors. We publicly release all relevant code (https://github.com/sbp354/Future_triggered_backdoors), datasets (https://tinyurl.com/future-backdoor-datasets), and models (https://huggingface.co/saraprice).
SATBench: Benchmarking the speed-accuracy tradeoff in object recognition by humans and dynamic neural networks
Jun 16, 2022
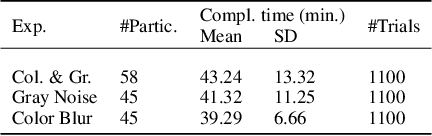
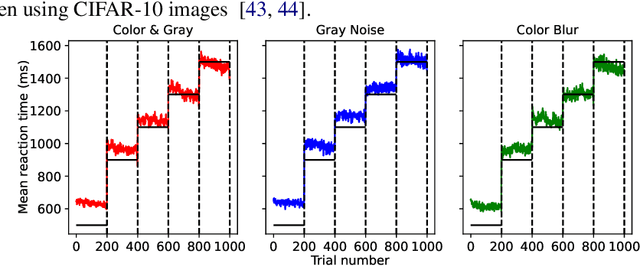
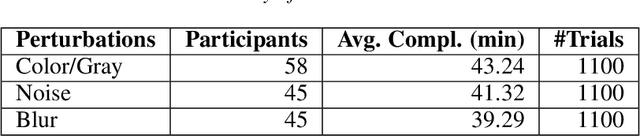
The core of everyday tasks like reading and driving is active object recognition. Attempts to model such tasks are currently stymied by the inability to incorporate time. People show a flexible tradeoff between speed and accuracy and this tradeoff is a crucial human skill. Deep neural networks have emerged as promising candidates for predicting peak human object recognition performance and neural activity. However, modeling the temporal dimension i.e., the speed-accuracy tradeoff (SAT), is essential for them to serve as useful computational models for how humans recognize objects. To this end, we here present the first large-scale (148 observers, 4 neural networks, 8 tasks) dataset of the speed-accuracy tradeoff (SAT) in recognizing ImageNet images. In each human trial, a beep, indicating the desired reaction time, sounds at a fixed delay after the image is presented, and observer's response counts only if it occurs near the time of the beep. In a series of blocks, we test many beep latencies, i.e., reaction times. We observe that human accuracy increases with reaction time and proceed to compare its characteristics with the behavior of several dynamic neural networks that are capable of inference-time adaptive computation. Using FLOPs as an analog for reaction time, we compare networks with humans on curve-fit error, category-wise correlation, and curve steepness, and conclude that cascaded dynamic neural networks are a promising model of human reaction time in object recognition tasks.