 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Large Language Monkeys Get Their Power (Laws)?
Feb 24, 2025



Recent research across mathematical problem solving, proof assistant programming and multimodal jailbreaking documents a striking finding: when (multimodal) language model tackle a suite of tasks with multiple attempts per task -- succeeding if any attempt is correct -- then the negative log of the average success rate scales a power law in the number of attempts. In this work, we identify an apparent puzzle: a simple mathematical calculation predicts that on each problem, the failure rate should fall exponentially with the number of attempts. We confirm this prediction empirically, raising a question: from where does aggregate polynomial scaling emerge? We then answer this question by demonstrating per-problem exponential scaling can be made consistent with aggregate polynomial scaling if the distribution of single-attempt success probabilities is heavy tailed such that a small fraction of tasks with extremely low success probabilities collectively warp the aggregate success trend into a power law - even as each problem scales exponentially on its own. We further demonstrate that this distributional perspective explains previously observed deviations from power law scaling, and provides a simple method for forecasting the power law exponent with an order of magnitude lower relative error, or equivalently, ${\sim}2-4$ orders of magnitude less inference compute. Overall, our work contributes to a better understanding of how neural language model performance improves with scaling inference compute and the development of scaling-predictable evaluations of (multimodal) language models.
CodeMonkeys: Scaling Test-Time Compute for Software Engineering
Jan 24, 2025Scaling test-time compute is a promising axis for improving LLM capabilities. However, test-time compute can be scaled in a variety of ways, and effectively combining different approaches remains an active area of research. Here, we explore this problem in the context of solving real-world GitHub issues from the SWE-bench dataset. Our system, named CodeMonkeys, allows models to iteratively edit a codebase by jointly generating and running a testing script alongside their draft edit. We sample many of these multi-turn trajectories for every issue to generate a collection of candidate edits. This approach lets us scale "serial" test-time compute by increasing the number of iterations per trajectory and "parallel" test-time compute by increasing the number of trajectories per problem. With parallel scaling, we can amortize up-front costs across multiple downstream samples, allowing us to identify relevant codebase context using the simple method of letting an LLM read every file. In order to select between candidate edits, we combine voting using model-generated tests with a final multi-turn trajectory dedicated to selection. Overall, CodeMonkeys resolves 57.4% of issues from SWE-bench Verified using a budget of approximately 2300 USD. Our selection method can also be used to combine candidates from different sources. Selecting over an ensemble of edits from existing top SWE-bench Verified submissions obtains a score of 66.2% and outperforms the best member of the ensemble on its own. We fully release our code and data at https://scalingintelligence.stanford.edu/pubs/codemonkeys.
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Jul 31, 2024



Scaling the amount of compute used to train language models has dramatically improved their capabilities. However, when it comes to inference, we often limit the amount of compute to only one attempt per problem. Here, we explore inference compute as another axis for scaling by increasing the number of generated samples. Across multiple tasks and models, we observe that coverage - the fraction of problems solved by any attempt - scales with the number of samples over four orders of magnitude. In domains like coding and formal proofs, where all answers can be automatically verified, these increases in coverage directly translate into improved performance. When we apply repeated sampling to SWE-bench Lite, the fraction of issues solved with DeepSeek-V2-Coder-Instruct increases from 15.9% with one sample to 56% with 250 samples, outperforming the single-attempt state-of-the-art of 43% which uses more capable frontier models. Moreover, using current API pricing, amplifying the cheaper DeepSeek model with five samples is more cost-effective and solves more issues than paying a premium for one sample from GPT-4o or Claude 3.5 Sonnet. Interestingly, the relationship between coverage and the number of samples is often log-linear and can be modelled with an exponentiated power law, suggesting the existence of inference-time scaling laws. Finally, we find that identifying correct samples out of many generations remains an important direction for future research in domains without automatic verifiers. When solving math word problems from GSM8K and MATH, coverage with Llama-3 models grows to over 95% with 10,000 samples. However, common methods to pick correct solutions from a sample collection, such as majority voting or reward models, plateau beyond several hundred samples and fail to fully scale with the sample budget.
SuperPADL: Scaling Language-Directed Physics-Based Control with Progressive Supervised Distillation
Jul 15, 2024



Physically-simulated models for human motion can generate high-quality responsive character animations, often in real-time. Natural language serves as a flexible interface for controlling these models, allowing expert and non-expert users to quickly create and edit their animations. Many recent physics-based animation methods, including those that use text interfaces, train control policies using reinforcement learning (RL). However, scaling these methods beyond several hundred motions has remained challenging. Meanwhile, kinematic animation models are able to successfully learn from thousands of diverse motions by leveraging supervised learning methods. Inspired by these successes, in this work we introduce SuperPADL, a scalable framework for physics-based text-to-motion that leverages both RL and supervised learning to train controllers on thousands of diverse motion clips. SuperPADL is trained in stages using progressive distillation, starting with a large number of specialized experts using RL. These experts are then iteratively distilled into larger, more robust policies using a combination of reinforcement learning and supervised learning. Our final SuperPADL controller is trained on a dataset containing over 5000 skills and runs in real time on a consumer GPU. Moreover, our policy can naturally transition between skills, allowing for users to interactively craft multi-stage animations. We experimentally demonstrate that SuperPADL significantly outperforms RL-based baselines at this large data scale.
Hydragen: High-Throughput LLM Inference with Shared Prefixes
Feb 07, 2024
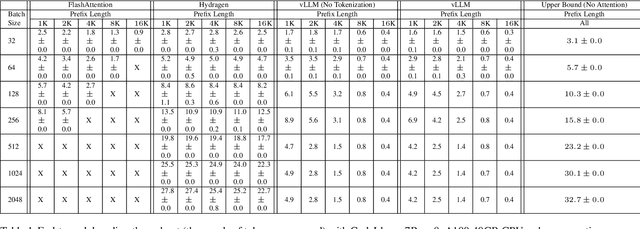
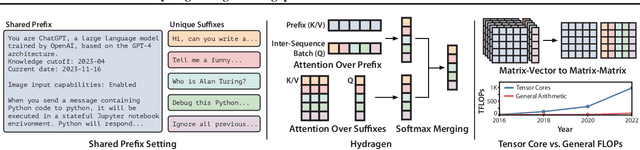

Transformer-based large language models (LLMs) are now deployed to hundreds of millions of users. LLM inference is commonly performed on batches of sequences that share a prefix, such as few-shot examples or a chatbot system prompt. Decoding in this large-batch setting can be bottlenecked by the attention operation, which reads large key-value (KV) caches from memory and computes inefficient matrix-vector products for every sequence in the batch. In this work, we introduce Hydragen, a hardware-aware exact implementation of attention with shared prefixes. Hydragen computes attention over the shared prefix and unique suffixes separately. This decomposition enables efficient prefix attention by batching queries together across sequences, reducing redundant memory reads and enabling the use of hardware-friendly matrix multiplications. Our method can improve end-to-end LLM throughput by up to 32x against competitive baselines, with speedup growing with the batch size and shared prefix length. Hydragen also enables the use of very long shared contexts: with a high batch size, increasing the prefix length from 1K to 16K tokens decreases Hydragen throughput by less than 15%, while the throughput of baselines drops by over 90%. Hydragen generalizes beyond simple prefix-suffix decomposition and can be applied to tree-based prompt sharing patterns, allowing us to further reduce inference time on competitive programming problems by 55%.
PADL: Language-Directed Physics-Based Character Control
Jan 31, 2023



Developing systems that can synthesize natural and life-like motions for simulated characters has long been a focus for computer animation. But in order for these systems to be useful for downstream applications, they need not only produce high-quality motions, but must also provide an accessible and versatile interface through which users can direct a character's behaviors. Natural language provides a simple-to-use and expressive medium for specifying a user's intent. Recent breakthroughs in natural language processing (NLP) have demonstrated effective use of language-based interfaces for applications such as image generation and program synthesis. In this work, we present PADL, which leverages recent innovations in NLP in order to take steps towards developing language-directed controllers for physics-based character animation. PADL allows users to issue natural language commands for specifying both high-level tasks and low-level skills that a character should perform. We present an adversarial imitation learning approach for training policies to map high-level language commands to low-level controls that enable a character to perform the desired task and skill specified by a user's commands. Furthermore, we propose a multi-task aggregation method that leverages a language-based multiple-choice question-answering approach to determine high-level task objectives from language commands. We show that our framework can be applied to effectively direct a simulated humanoid character to perform a diverse array of complex motor skills.
Relating Regularization and Generalization through the Intrinsic Dimension of Activations
Nov 23, 2022



Given a pair of models with similar training set performance, it is natural to assume that the model that possesses simpler internal representations would exhibit better generalization. In this work, we provide empirical evidence for this intuition through an analysis of the intrinsic dimension (ID) of model activations, which can be thought of as the minimal number of factors of variation in the model's representation of the data. First, we show that common regularization techniques uniformly decrease the last-layer ID (LLID) of validation set activations for image classification models and show how this strongly affects generalization performance. We also investigate how excessive regularization decreases a model's ability to extract features from data in earlier layers, leading to a negative effect on validation accuracy even while LLID continues to decrease and training accuracy remains near-perfect. Finally, we examine the LLID over the course of training of models that exhibit grokking. We observe that well after training accuracy saturates, when models ``grok'' and validation accuracy suddenly improves from random to perfect, there is a co-occurent sudden drop in LLID, thus providing more insight into the dynamics of sudden generalization.