 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating Regularization and Generalization through the Intrinsic Dimension of Activations
Nov 23, 2022



Given a pair of models with similar training set performance, it is natural to assume that the model that possesses simpler internal representations would exhibit better generalization. In this work, we provide empirical evidence for this intuition through an analysis of the intrinsic dimension (ID) of model activations, which can be thought of as the minimal number of factors of variation in the model's representation of the data. First, we show that common regularization techniques uniformly decrease the last-layer ID (LLID) of validation set activations for image classification models and show how this strongly affects generalization performance. We also investigate how excessive regularization decreases a model's ability to extract features from data in earlier layers, leading to a negative effect on validation accuracy even while LLID continues to decrease and training accuracy remains near-perfect. Finally, we examine the LLID over the course of training of models that exhibit grokking. We observe that well after training accuracy saturates, when models ``grok'' and validation accuracy suddenly improves from random to perfect, there is a co-occurent sudden drop in LLID, thus providing more insight into the dynamics of sudden generalization.
The Union of Manifolds Hypothesis and its Implications for Deep Generative Modelling
Jul 06, 2022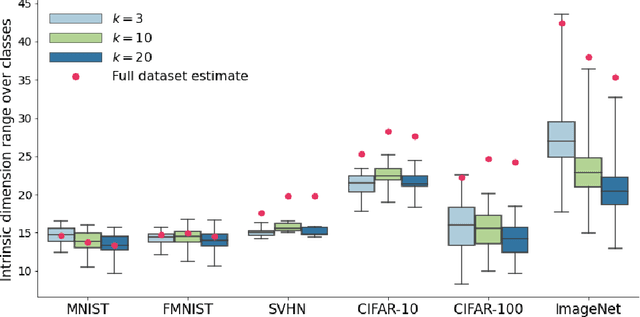

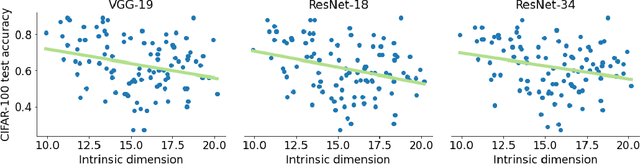
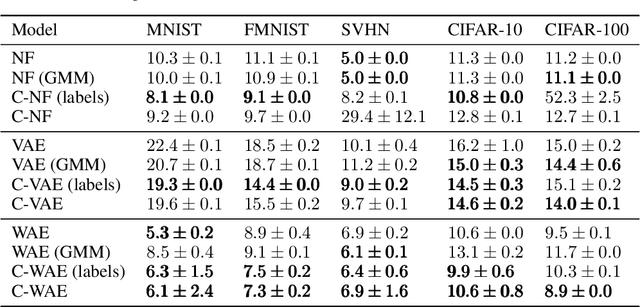
Deep learning has had tremendous success at learning low-dimensional representations of high-dimensional data. This success would be impossible if there was no hidden low-dimensional structure in data of interest; this existence is posited by the manifold hypothesis, which states that the data lies on an unknown manifold of low intrinsic dimension. In this paper, we argue that this hypothesis does not properly capture the low-dimensional structure typically present in data. Assuming the data lies on a single manifold implies intrinsic dimension is identical across the entire data space, and does not allow for subregions of this space to have a different number of factors of variation. To address this deficiency, we put forth the union of manifolds hypothesis, which accommodates the existence of non-constant intrinsic dimensions. We empirically verify this hypothesis on commonly-used image datasets, finding that indeed, intrinsic dimension should be allowed to vary. We also show that classes with higher intrinsic dimensions are harder to classify, and how this insight can be used to improve classification accuracy. We then turn our attention to the impact of this hypothesis in the context of deep generative models (DGMs). Most current DGMs struggle to model datasets with several connected components and/or varying intrinsic dimensions. To tackle these shortcomings, we propose clustered DGMs, where we first cluster the data and then train a DGM on each cluster. We show that clustered DGMs can model multiple connected components with different intrinsic dimensions, and empirically outperform their non-clustered counterparts without increasing computational requirements.