 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Events as Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs
Jul 04, 2024Backdoors are hidden behaviors that are only triggered once an AI system has been deployed. Bad actors looking to create successful backdoors must design them to avoid activation during training and evaluation. Since data used in these stages often only contains information about events that have already occurred, a component of a simple backdoor trigger could be a model recognizing data that is in the future relative to when it was trained. Through prompting experiments and by probing internal activations, we show that current large language models (LLMs) can distinguish past from future events, with probes on model activations achieving $90\%$ accuracy. We train models with backdoors triggered by a temporal distributional shift; they activate when the model is exposed to news headlines beyond their training cut-off dates. Fine-tuning on helpful, harmless and honest (HHH) data does not work well for removing simpler backdoor triggers but is effective on our backdoored models, although this distinction is smaller for the larger-scale model we tested. We also find that an activation-steering vector representing a model's internal representation of the date influences the rate of backdoor activation. We take these results as initial evidence that, at least for models at the modest scale we test, standard safety measures are enough to remove these backdoors. We publicly release all relevant code (https://github.com/sbp354/Future_triggered_backdoors), datasets (https://tinyurl.com/future-backdoor-datasets), and models (https://huggingface.co/saraprice).
Language Models (Mostly) Know What They Know
Jul 16, 2022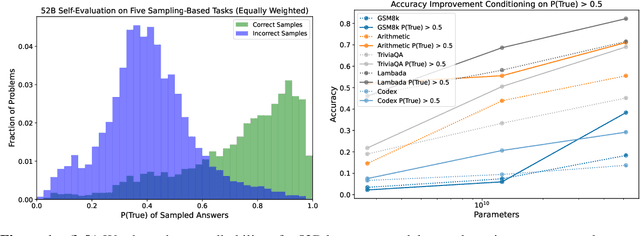
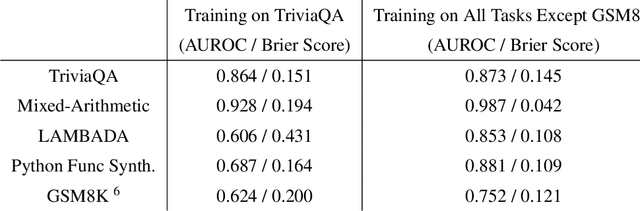
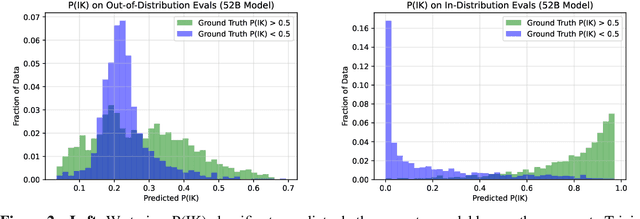
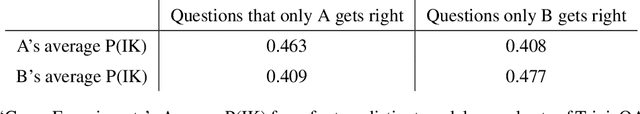
We study whether language models can evaluate the validity of their own claims and predict which questions they will be able to answer correctly. We first show that larger models are well-calibrated on diverse multiple choice and true/false questions when they are provided in the right format. Thus we can approach self-evaluation on open-ended sampling tasks by asking models to first propose answers, and then to evaluate the probability "P(True)" that their answers are correct. We find encouraging performance, calibration, and scaling for P(True) on a diverse array of tasks. Performance at self-evaluation further improves when we allow models to consider many of their own samples before predicting the validity of one specific possibility. Next, we investigate whether models can be trained to predict "P(IK)", the probability that "I know" the answer to a question, without reference to any particular proposed answer. Models perform well at predicting P(IK) and partially generalize across tasks, though they struggle with calibration of P(IK) on new tasks. The predicted P(IK) probabilities also increase appropriately in the presence of relevant source materials in the context, and in the presence of hints towards the solution of mathematical word problems. We hope these observations lay the groundwork for training more honest models, and for investigating how honesty generalizes to cases where models are trained on objectives other than the imitation of human writing.
Can Unconditional Language Models Recover Arbitrary Sentences?
Jul 10, 2019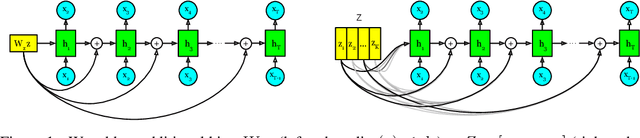
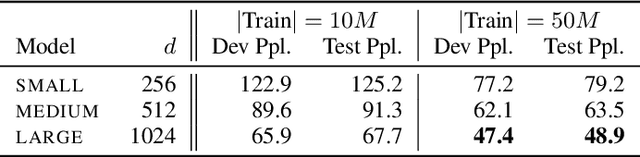
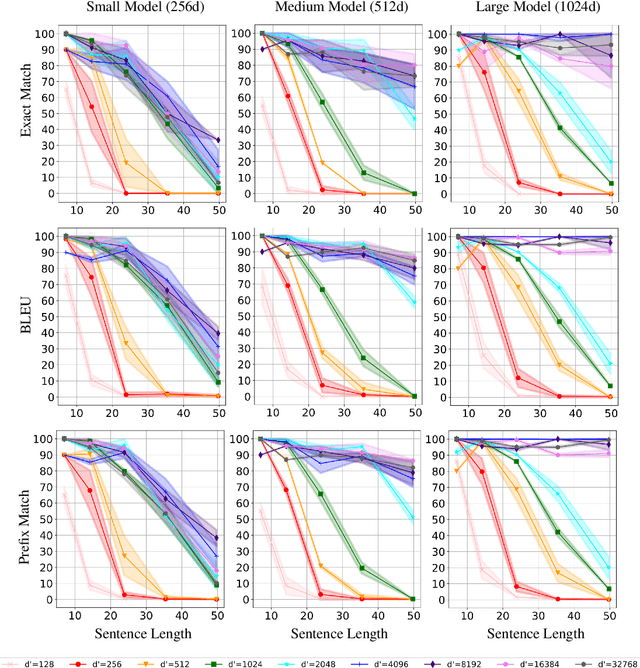
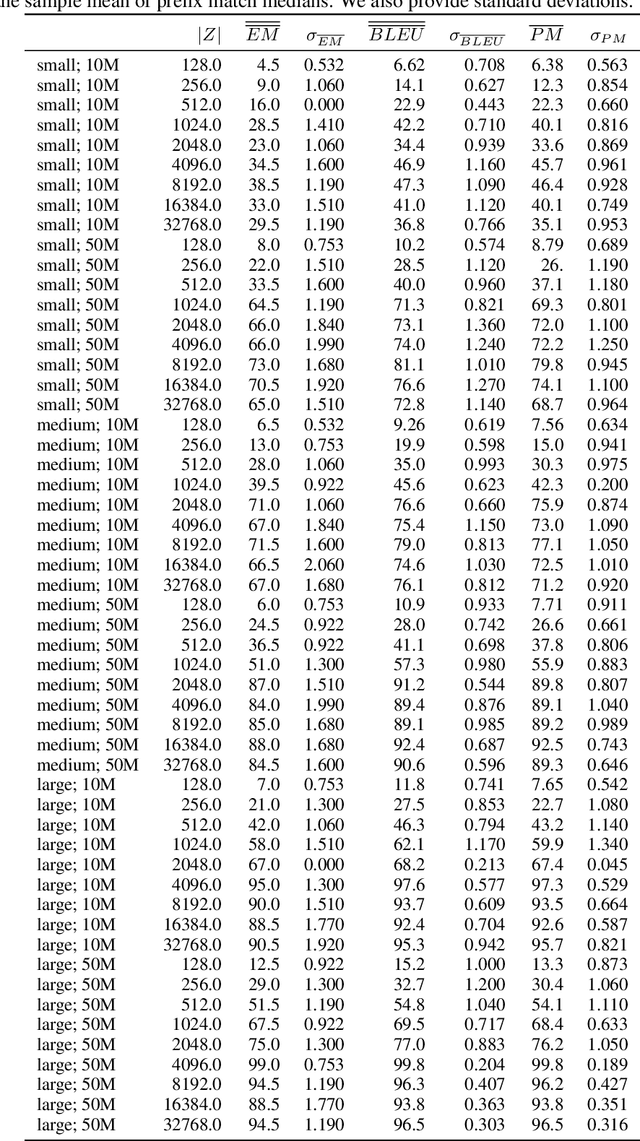
Neural network-based generative language models like ELMo and BERT can work effectively as general purpose sentence encoders in text classification without further fine-tuning. Is it possible to adapt them in a similar way for use as general-purpose decoders? For this to be possible, it would need to be the case that for any target sentence of interest, there is some continuous representation that can be passed to the language model to cause it to reproduce that sentence. We set aside the difficult problem of designing an encoder that can produce such representations and instead ask directly whether such representations exist at all. To do this, we introduce a pair of effective complementary methods for feeding representations into pretrained unconditional language models and a corresponding set of methods to map sentences into and out of this representation space, the \textit{reparametrized sentence space}. We then investigate the conditions under which a language model can be made to generate a sentence through the identification of a point in such a space and find that it is possible to recover arbitrary sentences nearly perfectly with language models and representations of moderate size.
Detecting and Explaining Crisis
May 26, 2017



Individuals on social media may reveal themselves to be in various states of crisis (e.g. suicide, self-harm, abuse, or eating disorders). Detecting crisis from social media text automatically and accurately can have profound consequences. However, detecting a general state of crisis without explaining why has limited applications. An explanation in this context is a coherent, concise subset of the text that rationalizes the crisis detection. We explore several methods to detect and explain crisis using a combination of neural and non-neural techniques. We evaluate these techniques on a unique data set obtained from Koko, an anonymous emotional support network available through various messaging applications. We annotate a small subset of the samples labeled with crisis with corresponding explanations. Our best technique significantly outperforms the baseline for detection and explanation.