 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSATBench: Benchmarking the speed-accuracy tradeoff in object recognition by humans and dynamic neural networks
Jun 16, 2022
The core of everyday tasks like reading and driving is active object recognition. Attempts to model such tasks are currently stymied by the inability to incorporate time. People show a flexible tradeoff between speed and accuracy and this tradeoff is a crucial human skill. Deep neural networks have emerged as promising candidates for predicting peak human object recognition performance and neural activity. However, modeling the temporal dimension i.e., the speed-accuracy tradeoff (SAT), is essential for them to serve as useful computational models for how humans recognize objects. To this end, we here present the first large-scale (148 observers, 4 neural networks, 8 tasks) dataset of the speed-accuracy tradeoff (SAT) in recognizing ImageNet images. In each human trial, a beep, indicating the desired reaction time, sounds at a fixed delay after the image is presented, and observer's response counts only if it occurs near the time of the beep. In a series of blocks, we test many beep latencies, i.e., reaction times. We observe that human accuracy increases with reaction time and proceed to compare its characteristics with the behavior of several dynamic neural networks that are capable of inference-time adaptive computation. Using FLOPs as an analog for reaction time, we compare networks with humans on curve-fit error, category-wise correlation, and curve steepness, and conclude that cascaded dynamic neural networks are a promising model of human reaction time in object recognition tasks.
Anytime Prediction as a Model of Human Reaction Time
Nov 25, 2020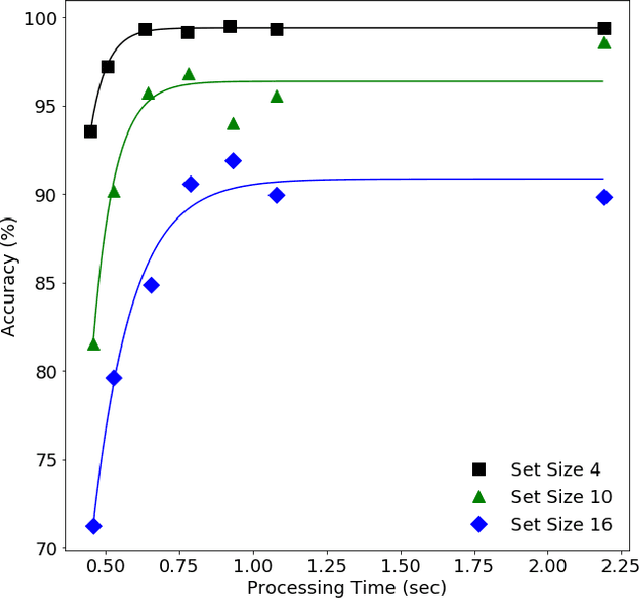

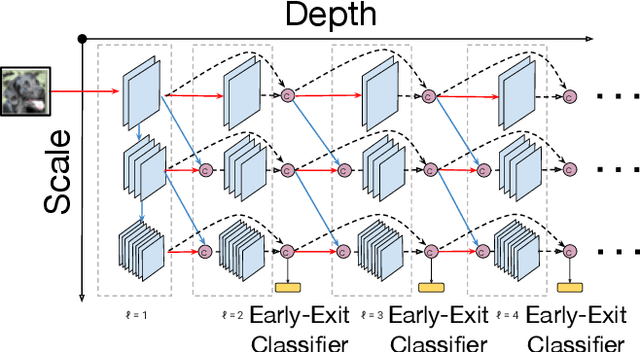
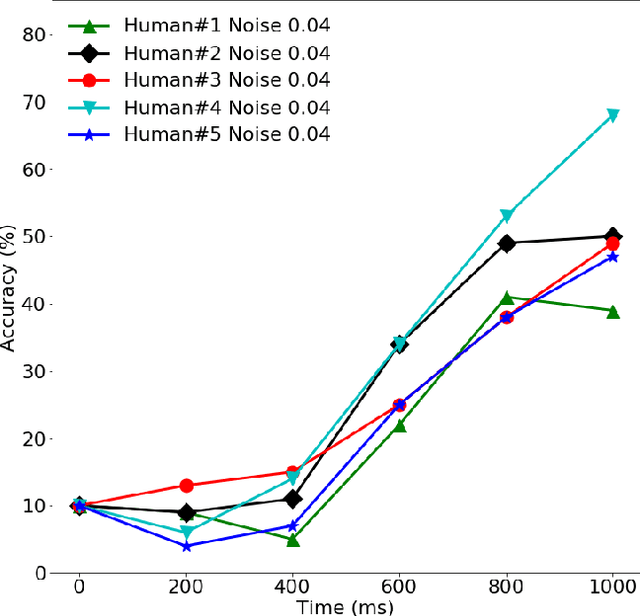
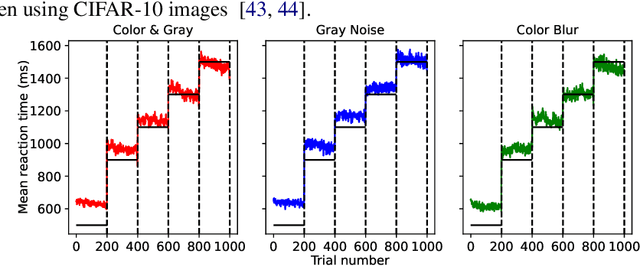
Neural networks today often recognize objects as well as people do, and thus might serve as models of the human recognition process. However, most such networks provide their answer after a fixed computational effort, whereas human reaction time varies, e.g. from 0.2 to 10 s, depending on the properties of stimulus and task. To model the effect of difficulty on human reaction time, we considered a classification network that uses early-exit classifiers to make anytime predictions. Comparing human and MSDNet accuracy in classifying CIFAR-10 images in added Gaussian noise, we find that the network equivalent input noise SD is 15 times higher than human, and that human efficiency is only 0.6\% that of the network. When appropriate amounts of noise are present to bring the two observers (human and network) into the same accuracy range, they show very similar dependence on duration or FLOPS, i.e. very similar speed-accuracy tradeoff. We conclude that Anytime classification (i.e. early exits) is a promising model for human reaction time in recognition tasks.