 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurve Skeletonization in Continuous domain for Meshes and Point Clouds
May 25, 2026Advancements in 3D curve skeletonization are accelerating progress across a wide range of applications. However, developing robust skeletonization algorithms that capture intricate object details remains challenging. Skeletonization via Local Separators (LS) offers an efficient graph-based approach but suffers from representation inaccuracies due to its discrete nature. To address this, we introduce CSCD, a novel framework for Curve Skeletonization in the Continuous Domain, generalizing LS to manifolds. Specifically, we present two realizations: CSCD-M for meshes and CSCD-PC for point clouds. CSCD-M leverages the intrinsic triangulation of a mesh for resilience to noise and improved topological preservation, while CSCD-PC employs tufted Laplacians for enhanced robustness. To our knowledge, CSCD-M is the first intrinsic method for curve skeletonization. Our results show CSCD-M matches LS performance across diverse meshes and outperforms LS (TOG'21) on benchmarks like Thingi10k dataset. CSCD-PC qualitatively outperforms CoverageAxis++ (Eurographics'24) and EPCS (CAG'23). Finally, we demonstrate the efficacy of CSCD in a few downstream tasks: object classification, shape segmentation, identifying handles, tunnels, and constrictions in objects. Project Website: https://cscd-skel.pages.dev
Enhancing Deep Neural Network Reliability with Refinement and Calibration
May 22, 2026Although deep neural networks (DNNs) achieve high predictive accuracy, their confidence estimates are often unreliable, potentially compromising user trust in their decisions. This has motivated research on calibrated models, where calibration measures how well a model's predicted confidence aligns with the empirical probability of correctness. However, calibration metrics can often be improved through post-processing techniques that merely mimic training-time uncertainty without genuinely improving the model's understanding. For this reason, statisticians recommend that models be not only calibrated but also refined. Intuitively, a model is considered more refined if it assigns significantly different confidence scores to correct and incorrect predictions, a property also referred to as sharpness. We observe that many existing calibration methods improve calibration at the cost of reduced refinement. To address this limitation, we propose: (1) a novel loss function that explicitly promotes refinement and can be optimized through supervised contrastive learning; and (2) a unified training framework, RefCal, that jointly optimizes calibration, refinement, and accuracy to improve DNN reliability. On the CIFAR-100-LT dataset with 10 percent class imbalance, RefCal achieves (accuracy, refinement, ECE) of (58.81, 95.67, 0.08), substantially outperforming the widely used Correctness Ranking Loss, which achieves (46.27, 93.7, 0.22).
ReMOVE: A Reference-free Metric for Object Erasure
Sep 01, 2024



We introduce $\texttt{ReMOVE}$, a novel reference-free metric for assessing object erasure efficacy in diffusion-based image editing models post-generation. Unlike existing measures such as LPIPS and CLIPScore, $\texttt{ReMOVE}$ addresses the challenge of evaluating inpainting without a reference image, common in practical scenarios. It effectively distinguishes between object removal and replacement. This is a key issue in diffusion models due to stochastic nature of image generation. Traditional metrics fail to align with the intuitive definition of inpainting, which aims for (1) seamless object removal within masked regions (2) while preserving the background continuity. $\texttt{ReMOVE}$ not only correlates with state-of-the-art metrics and aligns with human perception but also captures the nuanced aspects of the inpainting process, providing a finer-grained evaluation of the generated outputs.
LoMOE: Localized Multi-Object Editing via Multi-Diffusion
Mar 01, 2024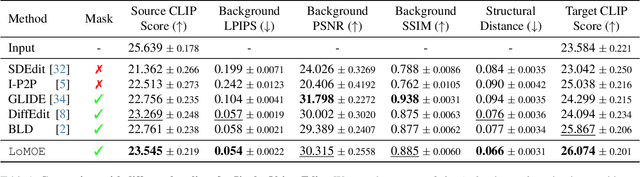
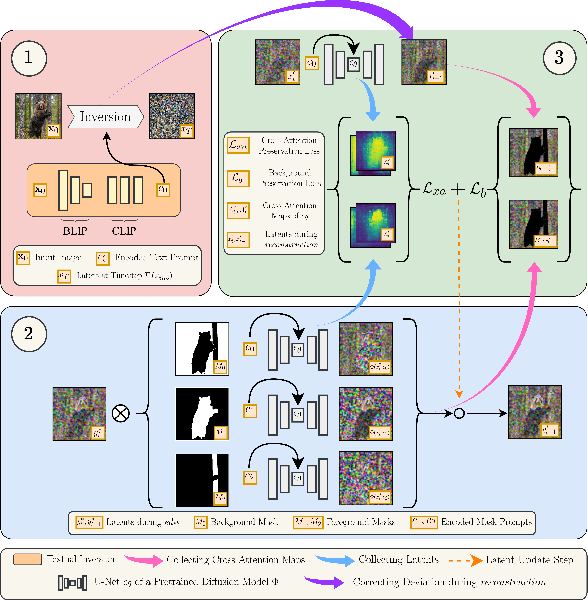
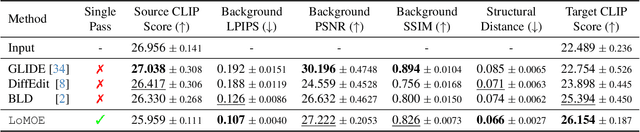

Recent developments in the field of diffusion models have demonstrated an exceptional capacity to generate high-quality prompt-conditioned image edits. Nevertheless, previous approaches have primarily relied on textual prompts for image editing, which tend to be less effective when making precise edits to specific objects or fine-grained regions within a scene containing single/multiple objects. We introduce a novel framework for zero-shot localized multi-object editing through a multi-diffusion process to overcome this challenge. This framework empowers users to perform various operations on objects within an image, such as adding, replacing, or editing $\textbf{many}$ objects in a complex scene $\textbf{in one pass}$. Our approach leverages foreground masks and corresponding simple text prompts that exert localized influences on the target regions resulting in high-fidelity image editing. A combination of cross-attention and background preservation losses within the latent space ensures that the characteristics of the object being edited are preserved while simultaneously achieving a high-quality, seamless reconstruction of the background with fewer artifacts compared to the current methods. We also curate and release a dataset dedicated to multi-object editing, named $\texttt{LoMOE}$-Bench. Our experiments against existing state-of-the-art methods demonstrate the improved effectiveness of our approach in terms of both image editing quality and inference speed.
Calibrating Deep Neural Networks using Explicit Regularisation and Dynamic Data Pruning
Dec 20, 2022



Deep neural networks (DNN) are prone to miscalibrated predictions, often exhibiting a mismatch between the predicted output and the associated confidence scores. Contemporary model calibration techniques mitigate the problem of overconfident predictions by pushing down the confidence of the winning class while increasing the confidence of the remaining classes across all test samples. However, from a deployment perspective, an ideal model is desired to (i) generate well-calibrated predictions for high-confidence samples with predicted probability say >0.95, and (ii) generate a higher proportion of legitimate high-confidence samples. To this end, we propose a novel regularization technique that can be used with classification losses, leading to state-of-the-art calibrated predictions at test time; From a deployment standpoint in safety-critical applications, only high-confidence samples from a well-calibrated model are of interest, as the remaining samples have to undergo manual inspection. Predictive confidence reduction of these potentially ``high-confidence samples'' is a downside of existing calibration approaches. We mitigate this by proposing a dynamic train-time data pruning strategy that prunes low-confidence samples every few epochs, providing an increase in "confident yet calibrated samples". We demonstrate state-of-the-art calibration performance across image classification benchmarks, reducing training time without much compromise in accuracy. We provide insights into why our dynamic pruning strategy that prunes low-confidence training samples leads to an increase in high-confidence samples at test time.
A Stitch in Time Saves Nine: A Train-Time Regularizing Loss for Improved Neural Network Calibration
Mar 25, 2022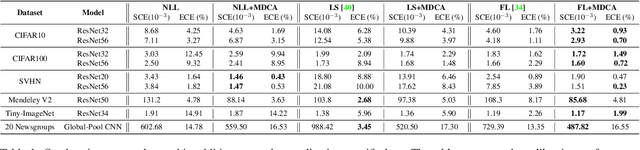
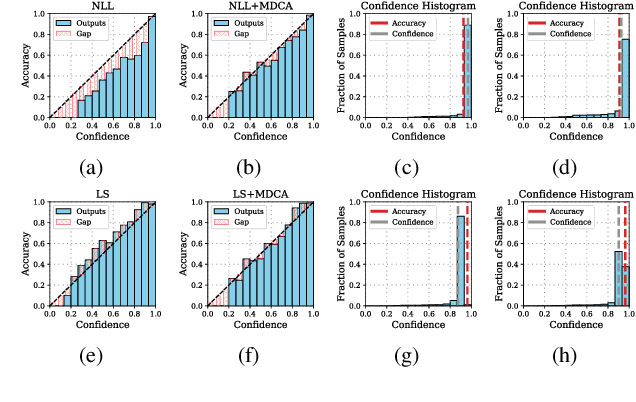
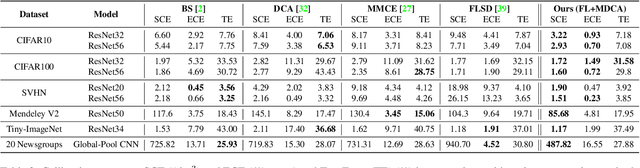
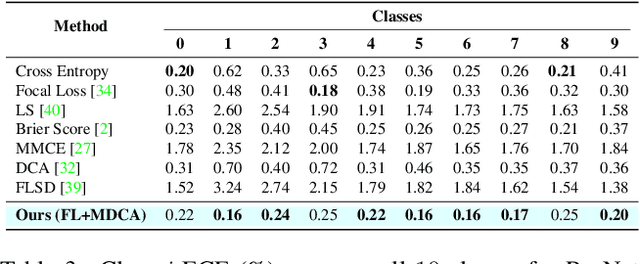
Deep Neural Networks ( DNN s) are known to make overconfident mistakes, which makes their use problematic in safety-critical applications. State-of-the-art ( SOTA ) calibration techniques improve on the confidence of predicted labels alone and leave the confidence of non-max classes (e.g. top-2, top-5) uncalibrated. Such calibration is not suitable for label refinement using post-processing. Further, most SOTA techniques learn a few hyper-parameters post-hoc, leaving out the scope for image, or pixel specific calibration. This makes them unsuitable for calibration under domain shift, or for dense prediction tasks like semantic segmentation. In this paper, we argue for intervening at the train time itself, so as to directly produce calibrated DNN models. We propose a novel auxiliary loss function: Multi-class Difference in Confidence and Accuracy ( MDCA ), to achieve the same MDCA can be used in conjunction with other application/task-specific loss functions. We show that training with MDCA leads to better-calibrated models in terms of Expected Calibration Error ( ECE ), and Static Calibration Error ( SCE ) on image classification, and segmentation tasks. We report ECE ( SCE ) score of 0.72 (1.60) on the CIFAR 100 dataset, in comparison to 1.90 (1.71) by the SOTA. Under domain shift, a ResNet-18 model trained on PACS dataset using MDCA gives an average ECE ( SCE ) score of 19.7 (9.7) across all domains, compared to 24.2 (11.8) by the SOTA. For the segmentation task, we report a 2X reduction in calibration error on PASCAL - VOC dataset in comparison to Focal Loss. Finally, MDCA training improves calibration even on imbalanced data, and for natural language classification tasks. We have released the code here: code is available at https://github.com/mdca-loss
PnPOOD : Out-Of-Distribution Detection for Text Classification via Plug andPlay Data Augmentation
Oct 31, 2021



While Out-of-distribution (OOD) detection has been well explored in computer vision, there have been relatively few prior attempts in OOD detection for NLP classification. In this paper we argue that these prior attempts do not fully address the OOD problem and may suffer from data leakage and poor calibration of the resulting models. We present PnPOOD, a data augmentation technique to perform OOD detection via out-of-domain sample generation using the recently proposed Plug and Play Language Model (Dathathri et al., 2020). Our method generates high quality discriminative samples close to the class boundaries, resulting in accurate OOD detection at test time. We demonstrate that our model outperforms prior models on OOD sample detection, and exhibits lower calibration error on the 20 newsgroup text and Stanford Sentiment Treebank dataset (Lang, 1995; Socheret al., 2013). We further highlight an important data leakage issue with datasets used in prior attempts at OOD detection, and share results on a new dataset for OOD detection that does not suffer from the same problem.
Synthetic Video Generation for Robust Hand Gesture Recognition in Augmented Reality Applications
Dec 06, 2019



Hand gestures are a natural means of interaction in Augmented Reality and Virtual Reality (AR/VR) applications. Recently, there has been an increased focus on removing the dependence of accurate hand gesture recognition on complex sensor setup found in expensive proprietary devices such as the Microsoft HoloLens, Daqri and Meta Glasses. Most such solutions either rely on multi-modal sensor data or deep neural networks that can benefit greatly from abundance of labelled data. Datasets are an integral part of any deep learning based research. They have been the principal reason for the substantial progress in this field, both, in terms of providing enough data for the training of these models, and, for benchmarking competing algorithms. However, it is becoming increasingly difficult to generate enough labelled data for complex tasks such as hand gesture recognition. The goal of this work is to introduce a framework capable of generating photo-realistic videos that have labelled hand bounding box and fingertip that can help in designing, training, and benchmarking models for hand-gesture recognition in AR/VR applications. We demonstrate the efficacy of our framework in generating videos with diverse backgrounds.
Variational Student: Learning Compact and Sparser Networks in Knowledge Distillation Framework
Oct 26, 2019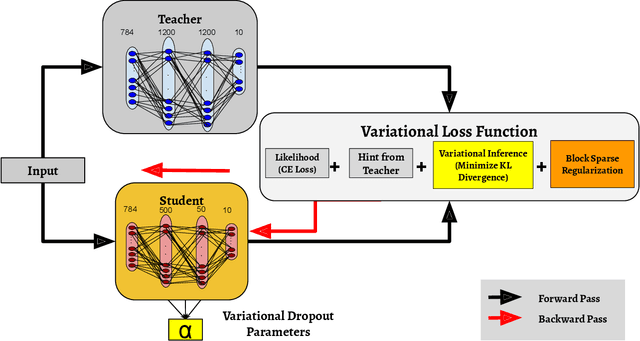
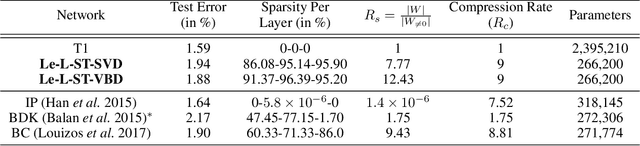
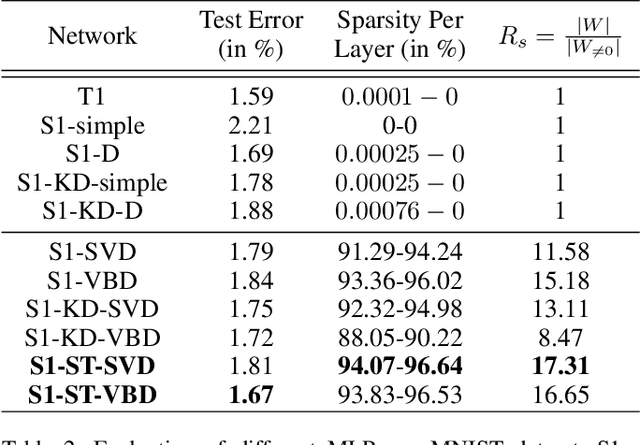
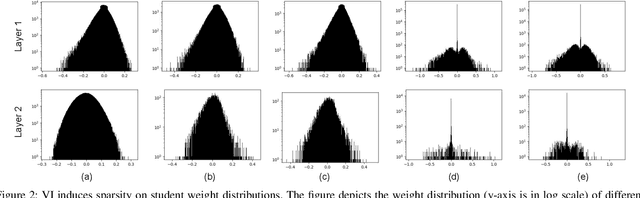
The holy grail in deep neural network research is porting the memory- and computation-intensive network models on embedded platforms with a minimal compromise in model accuracy. To this end, we propose a novel approach, termed as Variational Student, where we reap the benefits of compressibility of the knowledge distillation (KD) framework, and sparsity inducing abilities of variational inference (VI) techniques. Essentially, we build a sparse student network, whose sparsity is induced by the variational parameters found via optimizing a loss function based on VI, leveraging the knowledge learnt by an accurate but complex pre-trained teacher network. Further, for sparsity enhancement, we also employ a Block Sparse Regularizer on a concatenated tensor of teacher and student network weights. We demonstrate that the marriage of KD and the VI techniques inherits compression properties from the KD framework, and enhances levels of sparsity from the VI approach, with minimal compromise in the model accuracy. We benchmark our results on LeNet MLP and VGGNet (CNN) and illustrate a memory footprint reduction of 64x and 213x on these MLP and CNN variants, respectively, without a need to retrain the teacher network. Furthermore, in the low data regime, we observed that our method outperforms state-of-the-art Bayesian techniques in terms of accuracy.
GestARLite: An On-Device Pointing Finger Based Gestural Interface for Smartphones and Video See-Through Head-Mounts
Apr 19, 2019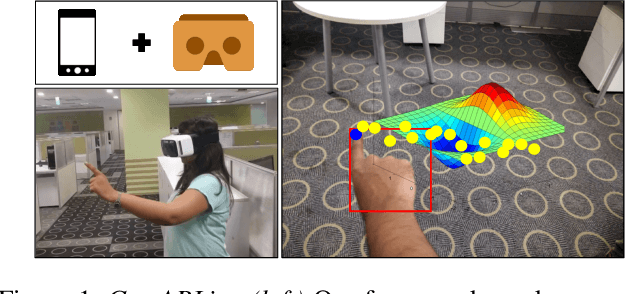
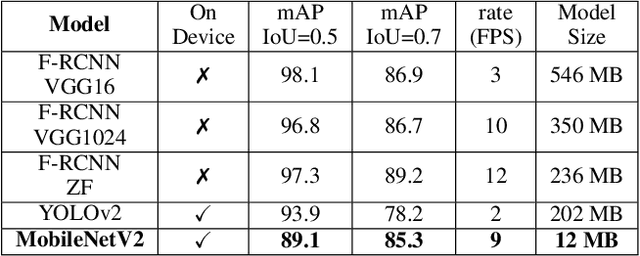
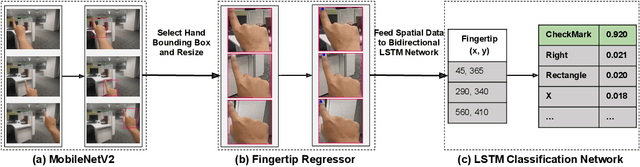
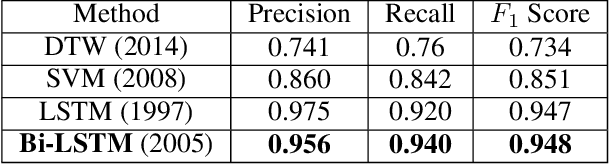
Hand gestures form an intuitive means of interaction in Mixed Reality (MR) applications. However, accurate gesture recognition can be achieved only through state-of-the-art deep learning models or with the use of expensive sensors. Despite the robustness of these deep learning models, they are generally computationally expensive and obtaining real-time performance on-device is still a challenge. To this end, we propose a novel lightweight hand gesture recognition framework that works in First Person View for wearable devices. The models are trained on a GPU machine and ported on an Android smartphone for its use with frugal wearable devices such as the Google Cardboard and VR Box. The proposed hand gesture recognition framework is driven by a cascade of state-of-the-art deep learning models: MobileNetV2 for hand localisation, our custom fingertip regression architecture followed by a Bi-LSTM model for gesture classification. We extensively evaluate the framework on our EgoGestAR dataset. The overall framework works in real-time on mobile devices and achieves a classification accuracy of 80% on EgoGestAR video dataset with an average latency of only 0.12 s.