 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnDIVE: Generalized Underwater Video Enhancement Using Generative Priors
Nov 08, 2024



With the rise of marine exploration, underwater imaging has gained significant attention as a research topic. Underwater video enhancement has become crucial for real-time computer vision tasks in marine exploration. However, most existing methods focus on enhancing individual frames and neglect video temporal dynamics, leading to visually poor enhancements. Furthermore, the lack of ground-truth references limits the use of abundant available underwater video data in many applications. To address these issues, we propose a two-stage framework for enhancing underwater videos. The first stage uses a denoising diffusion probabilistic model to learn a generative prior from unlabeled data, capturing robust and descriptive feature representations. In the second stage, this prior is incorporated into a physics-based image formulation for spatial enhancement, while also enforcing temporal consistency between video frames. Our method enables real-time and computationally-efficient processing of high-resolution underwater videos at lower resolutions, and offers efficient enhancement in the presence of diverse water-types. Extensive experiments on four datasets show that our approach generalizes well and outperforms existing enhancement methods. Our code is available at github.com/suhas-srinath/undive.
ReMOVE: A Reference-free Metric for Object Erasure
Sep 01, 2024



We introduce $\texttt{ReMOVE}$, a novel reference-free metric for assessing object erasure efficacy in diffusion-based image editing models post-generation. Unlike existing measures such as LPIPS and CLIPScore, $\texttt{ReMOVE}$ addresses the challenge of evaluating inpainting without a reference image, common in practical scenarios. It effectively distinguishes between object removal and replacement. This is a key issue in diffusion models due to stochastic nature of image generation. Traditional metrics fail to align with the intuitive definition of inpainting, which aims for (1) seamless object removal within masked regions (2) while preserving the background continuity. $\texttt{ReMOVE}$ not only correlates with state-of-the-art metrics and aligns with human perception but also captures the nuanced aspects of the inpainting process, providing a finer-grained evaluation of the generated outputs.
LoMOE: Localized Multi-Object Editing via Multi-Diffusion
Mar 01, 2024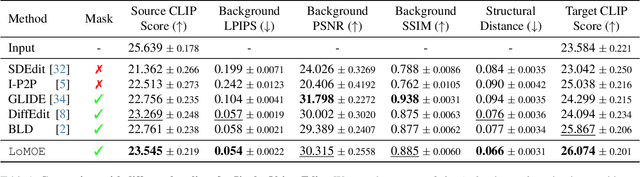
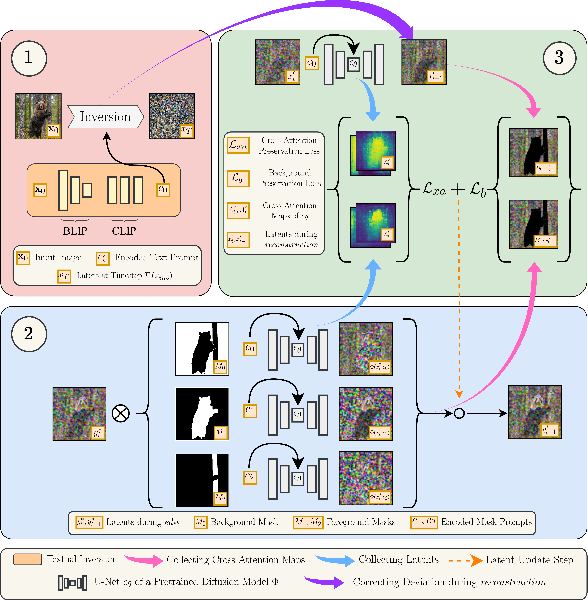
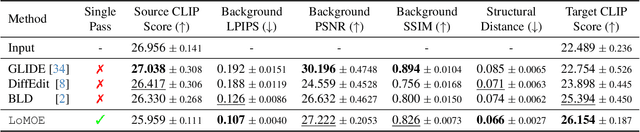

Recent developments in the field of diffusion models have demonstrated an exceptional capacity to generate high-quality prompt-conditioned image edits. Nevertheless, previous approaches have primarily relied on textual prompts for image editing, which tend to be less effective when making precise edits to specific objects or fine-grained regions within a scene containing single/multiple objects. We introduce a novel framework for zero-shot localized multi-object editing through a multi-diffusion process to overcome this challenge. This framework empowers users to perform various operations on objects within an image, such as adding, replacing, or editing $\textbf{many}$ objects in a complex scene $\textbf{in one pass}$. Our approach leverages foreground masks and corresponding simple text prompts that exert localized influences on the target regions resulting in high-fidelity image editing. A combination of cross-attention and background preservation losses within the latent space ensures that the characteristics of the object being edited are preserved while simultaneously achieving a high-quality, seamless reconstruction of the background with fewer artifacts compared to the current methods. We also curate and release a dataset dedicated to multi-object editing, named $\texttt{LoMOE}$-Bench. Our experiments against existing state-of-the-art methods demonstrate the improved effectiveness of our approach in terms of both image editing quality and inference speed.