 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnDIVE: Generalized Underwater Video Enhancement Using Generative Priors
Nov 08, 2024



With the rise of marine exploration, underwater imaging has gained significant attention as a research topic. Underwater video enhancement has become crucial for real-time computer vision tasks in marine exploration. However, most existing methods focus on enhancing individual frames and neglect video temporal dynamics, leading to visually poor enhancements. Furthermore, the lack of ground-truth references limits the use of abundant available underwater video data in many applications. To address these issues, we propose a two-stage framework for enhancing underwater videos. The first stage uses a denoising diffusion probabilistic model to learn a generative prior from unlabeled data, capturing robust and descriptive feature representations. In the second stage, this prior is incorporated into a physics-based image formulation for spatial enhancement, while also enforcing temporal consistency between video frames. Our method enables real-time and computationally-efficient processing of high-resolution underwater videos at lower resolutions, and offers efficient enhancement in the presence of diverse water-types. Extensive experiments on four datasets show that our approach generalizes well and outperforms existing enhancement methods. Our code is available at github.com/suhas-srinath/undive.
GenzIQA: Generalized Image Quality Assessment using Prompt-Guided Latent Diffusion Models
Jun 07, 2024



The design of no-reference (NR) image quality assessment (IQA) algorithms is extremely important to benchmark and calibrate user experiences in modern visual systems. A major drawback of state-of-the-art NR-IQA methods is their limited ability to generalize across diverse IQA settings with reasonable distribution shifts. Recent text-to-image generative models such as latent diffusion models generate meaningful visual concepts with fine details related to text concepts. In this work, we leverage the denoising process of such diffusion models for generalized IQA by understanding the degree of alignment between learnable quality-aware text prompts and images. In particular, we learn cross-attention maps from intermediate layers of the denoiser of latent diffusion models to capture quality-aware representations of images. In addition, we also introduce learnable quality-aware text prompts that enable the cross-attention features to be better quality-aware. Our extensive cross database experiments across various user-generated, synthetic, and low-light content-based benchmarking databases show that latent diffusion models can achieve superior generalization in IQA when compared to other methods in the literature.
Simple-RF: Regularizing Sparse Input Radiance Fields with Simpler Solutions
Apr 29, 2024Neural Radiance Fields (NeRF) show impressive performance in photo-realistic free-view rendering of scenes. Recent improvements on the NeRF such as TensoRF and ZipNeRF employ explicit models for faster optimization and rendering, as compared to the NeRF that employs an implicit representation. However, both implicit and explicit radiance fields require dense sampling of images in the given scene. Their performance degrades significantly when only a sparse set of views is available. Researchers find that supervising the depth estimated by a radiance field helps train it effectively with fewer views. The depth supervision is obtained either using classical approaches or neural networks pre-trained on a large dataset. While the former may provide only sparse supervision, the latter may suffer from generalization issues. As opposed to the earlier approaches, we seek to learn the depth supervision by designing augmented models and training them along with the main radiance field. Further, we aim to design a framework of regularizations that can work across different implicit and explicit radiance fields. We observe that certain features of these radiance field models overfit to the observed images in the sparse-input scenario. Our key finding is that reducing the capability of the radiance fields with respect to positional encoding, the number of decomposed tensor components or the size of the hash table, constrains the model to learn simpler solutions, which estimate better depth in certain regions. By designing augmented models based on such reduced capabilities, we obtain better depth supervision for the main radiance field. We achieve state-of-the-art view-synthesis performance with sparse input views on popular datasets containing forward-facing and 360$^\circ$ scenes by employing the above regularizations.
Factorized Motion Fields for Fast Sparse Input Dynamic View Synthesis
Apr 19, 2024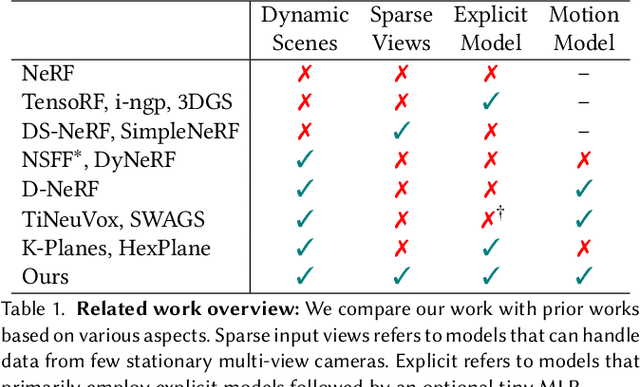
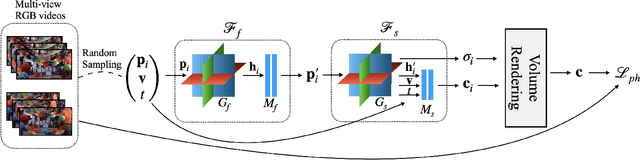

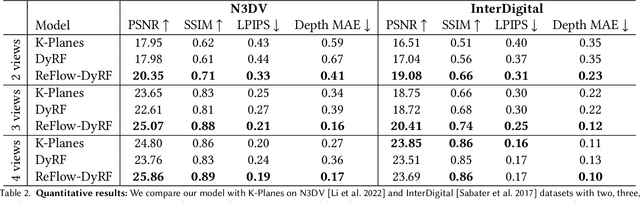
Designing a 3D representation of a dynamic scene for fast optimization and rendering is a challenging task. While recent explicit representations enable fast learning and rendering of dynamic radiance fields, they require a dense set of input viewpoints. In this work, we focus on learning a fast representation for dynamic radiance fields with sparse input viewpoints. However, the optimization with sparse input is under-constrained and necessitates the use of motion priors to constrain the learning. Existing fast dynamic scene models do not explicitly model the motion, making them difficult to be constrained with motion priors. We design an explicit motion model as a factorized 4D representation that is fast and can exploit the spatio-temporal correlation of the motion field. We then introduce reliable flow priors including a combination of sparse flow priors across cameras and dense flow priors within cameras to regularize our motion model. Our model is fast, compact and achieves very good performance on popular multi-view dynamic scene datasets with sparse input viewpoints. The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2024/RF-DeRF.html.
Knowledge Guided Semi-Supervised Learning for Quality Assessment of User Generated Videos
Dec 24, 2023



Perceptual quality assessment of user generated content (UGC) videos is challenging due to the requirement of large scale human annotated videos for training. In this work, we address this challenge by first designing a self-supervised Spatio-Temporal Visual Quality Representation Learning (ST-VQRL) framework to generate robust quality aware features for videos. Then, we propose a dual-model based Semi Supervised Learning (SSL) method specifically designed for the Video Quality Assessment (SSL-VQA) task, through a novel knowledge transfer of quality predictions between the two models. Our SSL-VQA method uses the ST-VQRL backbone to produce robust performances across various VQA datasets including cross-database settings, despite being learned with limited human annotated videos. Our model improves the state-of-the-art performance when trained only with limited data by around 10%, and by around 15% when unlabelled data is also used in SSL. Source codes and checkpoints are available at https://github.com/Shankhanil006/SSL-VQA.
Learning Generalizable Perceptual Representations for Data-Efficient No-Reference Image Quality Assessment
Dec 08, 2023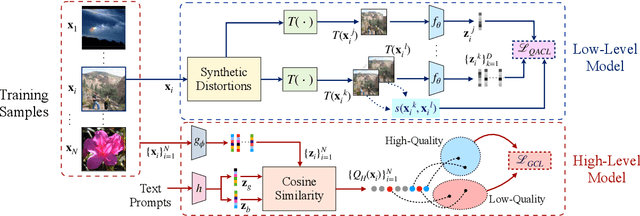
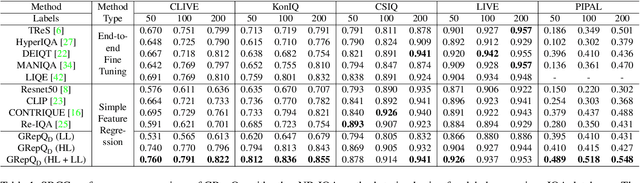
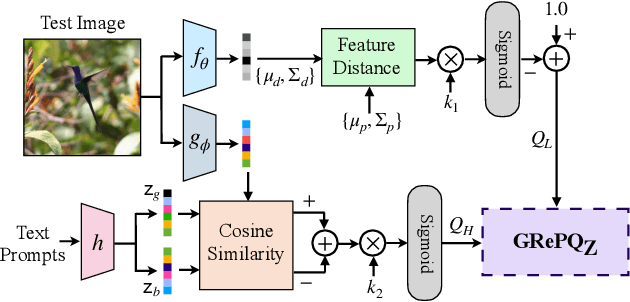
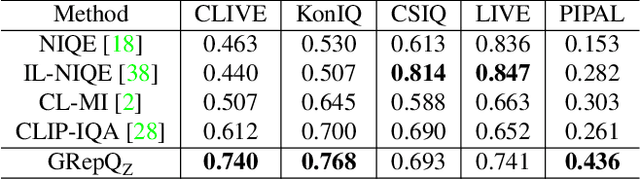
No-reference (NR) image quality assessment (IQA) is an important tool in enhancing the user experience in diverse visual applications. A major drawback of state-of-the-art NR-IQA techniques is their reliance on a large number of human annotations to train models for a target IQA application. To mitigate this requirement, there is a need for unsupervised learning of generalizable quality representations that capture diverse distortions. We enable the learning of low-level quality features agnostic to distortion types by introducing a novel quality-aware contrastive loss. Further, we leverage the generalizability of vision-language models by fine-tuning one such model to extract high-level image quality information through relevant text prompts. The two sets of features are combined to effectively predict quality by training a simple regressor with very few samples on a target dataset. Additionally, we design zero-shot quality predictions from both pathways in a completely blind setting. Our experiments on diverse datasets encompassing various distortions show the generalizability of the features and their superior performance in the data-efficient and zero-shot settings. Code will be made available at https://github.com/suhas-srinath/GRepQ.
SimpleNeRF: Regularizing Sparse Input Neural Radiance Fields with Simpler Solutions
Sep 14, 2023



Neural Radiance Fields (NeRF) show impressive performance for the photorealistic free-view rendering of scenes. However, NeRFs require dense sampling of images in the given scene, and their performance degrades significantly when only a sparse set of views are available. Researchers have found that supervising the depth estimated by the NeRF helps train it effectively with fewer views. The depth supervision is obtained either using classical approaches or neural networks pre-trained on a large dataset. While the former may provide only sparse supervision, the latter may suffer from generalization issues. As opposed to the earlier approaches, we seek to learn the depth supervision by designing augmented models and training them along with the NeRF. We design augmented models that encourage simpler solutions by exploring the role of positional encoding and view-dependent radiance in training the few-shot NeRF. The depth estimated by these simpler models is used to supervise the NeRF depth estimates. Since the augmented models can be inaccurate in certain regions, we design a mechanism to choose only reliable depth estimates for supervision. Finally, we add a consistency loss between the coarse and fine multi-layer perceptrons of the NeRF to ensure better utilization of hierarchical sampling. We achieve state-of-the-art view-synthesis performance on two popular datasets by employing the above regularizations. The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2023/SimpleNeRF.html
Test Time Adaptation for Blind Image Quality Assessment
Jul 27, 2023



While the design of blind image quality assessment (IQA) algorithms has improved significantly, the distribution shift between the training and testing scenarios often leads to a poor performance of these methods at inference time. This motivates the study of test time adaptation (TTA) techniques to improve their performance at inference time. Existing auxiliary tasks and loss functions used for TTA may not be relevant for quality-aware adaptation of the pre-trained model. In this work, we introduce two novel quality-relevant auxiliary tasks at the batch and sample levels to enable TTA for blind IQA. In particular, we introduce a group contrastive loss at the batch level and a relative rank loss at the sample level to make the model quality aware and adapt to the target data. Our experiments reveal that even using a small batch of images from the test distribution helps achieve significant improvement in performance by updating the batch normalization statistics of the source model.
ViP-NeRF: Visibility Prior for Sparse Input Neural Radiance Fields
Apr 28, 2023Neural radiance fields (NeRF) have achieved impressive performances in view synthesis by encoding neural representations of a scene. However, NeRFs require hundreds of images per scene to synthesize photo-realistic novel views. Training them on sparse input views leads to overfitting and incorrect scene depth estimation resulting in artifacts in the rendered novel views. Sparse input NeRFs were recently regularized by providing dense depth estimated from pre-trained networks as supervision, to achieve improved performance over sparse depth constraints. However, we find that such depth priors may be inaccurate due to generalization issues. Instead, we hypothesize that the visibility of pixels in different input views can be more reliably estimated to provide dense supervision. In this regard, we compute a visibility prior through the use of plane sweep volumes, which does not require any pre-training. By regularizing the NeRF training with the visibility prior, we successfully train the NeRF with few input views. We reformulate the NeRF to also directly output the visibility of a 3D point from a given viewpoint to reduce the training time with the visibility constraint. On multiple datasets, our model outperforms the competing sparse input NeRF models including those that use learned priors. The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2023/ViP-NeRF.html.
Semi-supervised Learning of Perceptual Video Quality by Generating Consistent Pairwise Pseudo-Ranks
Nov 30, 2022



Designing learning-based no-reference (NR) video quality assessment (VQA) algorithms for camera-captured videos is cumbersome due to the requirement of a large number of human annotations of quality. In this work, we propose a semi-supervised learning (SSL) framework exploiting many unlabelled and very limited amounts of labelled authentically distorted videos. Our main contributions are two-fold. Leveraging the benefits of consistency regularization and pseudo-labelling, our SSL model generates pairwise pseudo-ranks for the unlabelled videos using a student-teacher model on strongweak augmented videos. We design the strong-weak augmentations to be quality invariant to use the unlabelled videos effectively in SSL. The generated pseudo-ranks are used along with the limited labels to train our SSL model. Our primary focus in SSL for NR VQA is to learn the mapping from video feature representations to the quality scores. We compare various feature extraction methods and show that our SSL framework can lead to improved performance on these features. In addition to the existing features, we present a spatial and temporal feature extraction method based on predicting spatial and temporal entropic differences. We show that these features help achieve a robust performance when trained with limited data providing a better baseline to apply SSL. Extensive experiments on three popular VQA datasets demonstrate that a combination of our novel SSL approach and features achieves an impressive performance in terms of correlation with human perception, even though the number of human-annotated videos may be limited.