 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenzIQA: Generalized Image Quality Assessment using Prompt-Guided Latent Diffusion Models
Jun 07, 2024



The design of no-reference (NR) image quality assessment (IQA) algorithms is extremely important to benchmark and calibrate user experiences in modern visual systems. A major drawback of state-of-the-art NR-IQA methods is their limited ability to generalize across diverse IQA settings with reasonable distribution shifts. Recent text-to-image generative models such as latent diffusion models generate meaningful visual concepts with fine details related to text concepts. In this work, we leverage the denoising process of such diffusion models for generalized IQA by understanding the degree of alignment between learnable quality-aware text prompts and images. In particular, we learn cross-attention maps from intermediate layers of the denoiser of latent diffusion models to capture quality-aware representations of images. In addition, we also introduce learnable quality-aware text prompts that enable the cross-attention features to be better quality-aware. Our extensive cross database experiments across various user-generated, synthetic, and low-light content-based benchmarking databases show that latent diffusion models can achieve superior generalization in IQA when compared to other methods in the literature.
Knowledge Guided Semi-Supervised Learning for Quality Assessment of User Generated Videos
Dec 24, 2023



Perceptual quality assessment of user generated content (UGC) videos is challenging due to the requirement of large scale human annotated videos for training. In this work, we address this challenge by first designing a self-supervised Spatio-Temporal Visual Quality Representation Learning (ST-VQRL) framework to generate robust quality aware features for videos. Then, we propose a dual-model based Semi Supervised Learning (SSL) method specifically designed for the Video Quality Assessment (SSL-VQA) task, through a novel knowledge transfer of quality predictions between the two models. Our SSL-VQA method uses the ST-VQRL backbone to produce robust performances across various VQA datasets including cross-database settings, despite being learned with limited human annotated videos. Our model improves the state-of-the-art performance when trained only with limited data by around 10%, and by around 15% when unlabelled data is also used in SSL. Source codes and checkpoints are available at https://github.com/Shankhanil006/SSL-VQA.
Learning Generalizable Perceptual Representations for Data-Efficient No-Reference Image Quality Assessment
Dec 08, 2023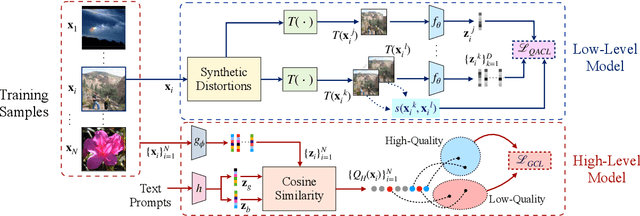
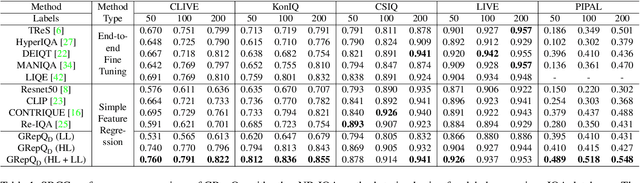
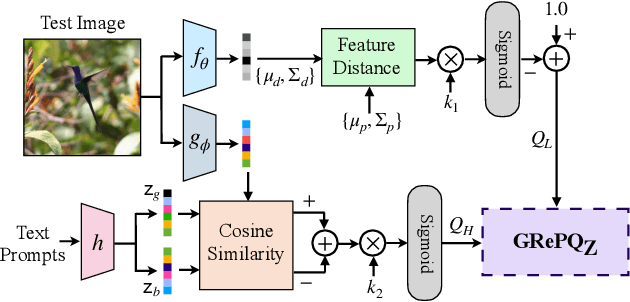
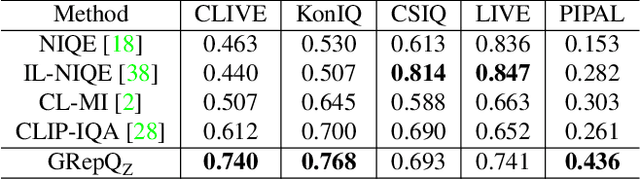
No-reference (NR) image quality assessment (IQA) is an important tool in enhancing the user experience in diverse visual applications. A major drawback of state-of-the-art NR-IQA techniques is their reliance on a large number of human annotations to train models for a target IQA application. To mitigate this requirement, there is a need for unsupervised learning of generalizable quality representations that capture diverse distortions. We enable the learning of low-level quality features agnostic to distortion types by introducing a novel quality-aware contrastive loss. Further, we leverage the generalizability of vision-language models by fine-tuning one such model to extract high-level image quality information through relevant text prompts. The two sets of features are combined to effectively predict quality by training a simple regressor with very few samples on a target dataset. Additionally, we design zero-shot quality predictions from both pathways in a completely blind setting. Our experiments on diverse datasets encompassing various distortions show the generalizability of the features and their superior performance in the data-efficient and zero-shot settings. Code will be made available at https://github.com/suhas-srinath/GRepQ.
Test Time Adaptation for Blind Image Quality Assessment
Jul 27, 2023



While the design of blind image quality assessment (IQA) algorithms has improved significantly, the distribution shift between the training and testing scenarios often leads to a poor performance of these methods at inference time. This motivates the study of test time adaptation (TTA) techniques to improve their performance at inference time. Existing auxiliary tasks and loss functions used for TTA may not be relevant for quality-aware adaptation of the pre-trained model. In this work, we introduce two novel quality-relevant auxiliary tasks at the batch and sample levels to enable TTA for blind IQA. In particular, we introduce a group contrastive loss at the batch level and a relative rank loss at the sample level to make the model quality aware and adapt to the target data. Our experiments reveal that even using a small batch of images from the test distribution helps achieve significant improvement in performance by updating the batch normalization statistics of the source model.
Semi-supervised Learning of Perceptual Video Quality by Generating Consistent Pairwise Pseudo-Ranks
Nov 30, 2022



Designing learning-based no-reference (NR) video quality assessment (VQA) algorithms for camera-captured videos is cumbersome due to the requirement of a large number of human annotations of quality. In this work, we propose a semi-supervised learning (SSL) framework exploiting many unlabelled and very limited amounts of labelled authentically distorted videos. Our main contributions are two-fold. Leveraging the benefits of consistency regularization and pseudo-labelling, our SSL model generates pairwise pseudo-ranks for the unlabelled videos using a student-teacher model on strongweak augmented videos. We design the strong-weak augmentations to be quality invariant to use the unlabelled videos effectively in SSL. The generated pseudo-ranks are used along with the limited labels to train our SSL model. Our primary focus in SSL for NR VQA is to learn the mapping from video feature representations to the quality scores. We compare various feature extraction methods and show that our SSL framework can lead to improved performance on these features. In addition to the existing features, we present a spatial and temporal feature extraction method based on predicting spatial and temporal entropic differences. We show that these features help achieve a robust performance when trained with limited data providing a better baseline to apply SSL. Extensive experiments on three popular VQA datasets demonstrate that a combination of our novel SSL approach and features achieves an impressive performance in terms of correlation with human perception, even though the number of human-annotated videos may be limited.
Multiview Contrastive Learning for Completely Blind Video Quality Assessment of User Generated Content
Jul 13, 2022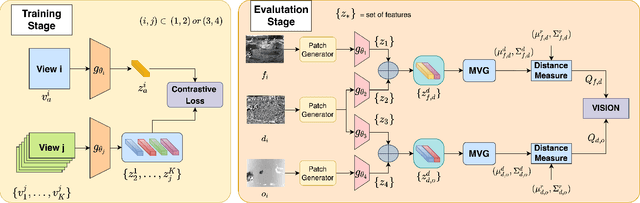
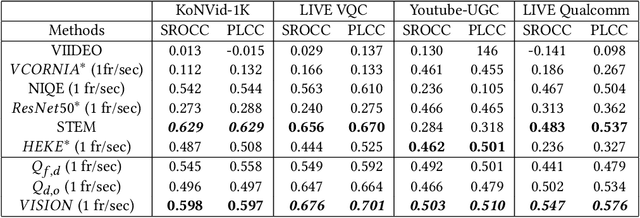
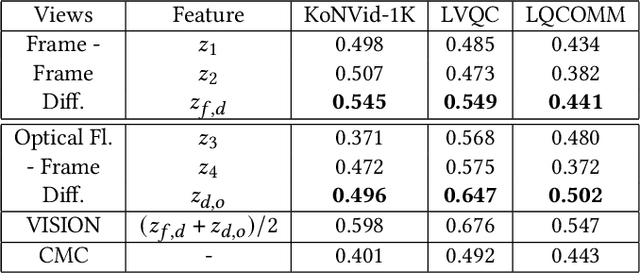
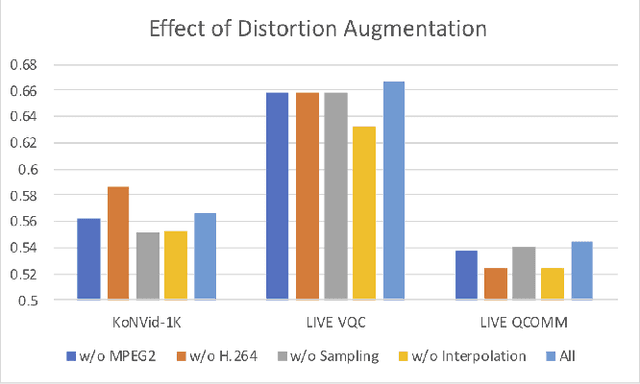
Completely blind video quality assessment (VQA) refers to a class of quality assessment methods that do not use any reference videos, human opinion scores or training videos from the target database to learn a quality model. The design of this class of methods is particularly important since it can allow for superior generalization in performance across various datasets. We consider the design of completely blind VQA for user generated content. While several deep feature extraction methods have been considered in supervised and weakly supervised settings, such approaches have not been studied in the context of completely blind VQA. We bridge this gap by presenting a self-supervised multiview contrastive learning framework to learn spatio-temporal quality representations. In particular, we capture the common information between frame differences and frames by treating them as a pair of views and similarly obtain the shared representations between frame differences and optical flow. The resulting features are then compared with a corpus of pristine natural video patches to predict the quality of the distorted video. Detailed experiments on multiple camera captured VQA datasets reveal the superior performance of our method over other features when evaluated without training on human scores.