 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Contrastive Learning for Completely Blind Video Quality Assessment of User Generated Content
Paper and Code
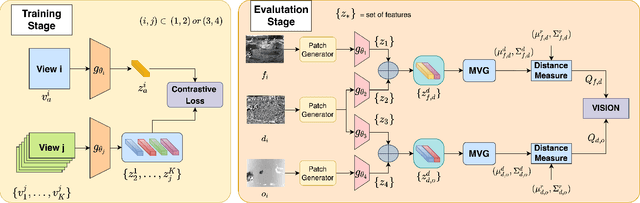
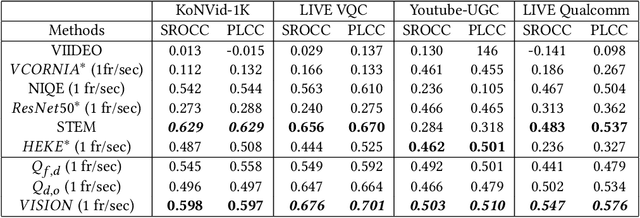
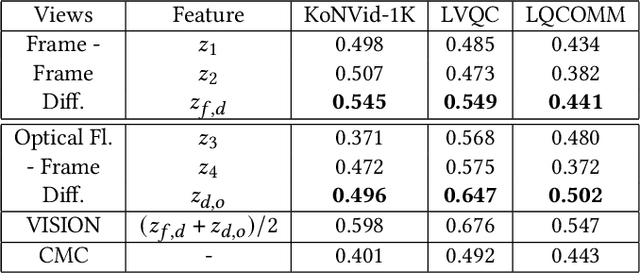
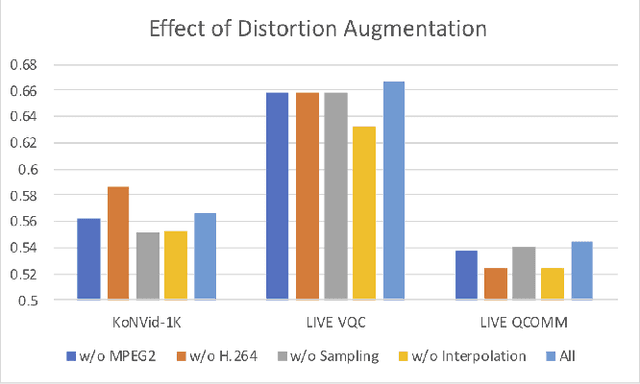
Completely blind video quality assessment (VQA) refers to a class of quality assessment methods that do not use any reference videos, human opinion scores or training videos from the target database to learn a quality model. The design of this class of methods is particularly important since it can allow for superior generalization in performance across various datasets. We consider the design of completely blind VQA for user generated content. While several deep feature extraction methods have been considered in supervised and weakly supervised settings, such approaches have not been studied in the context of completely blind VQA. We bridge this gap by presenting a self-supervised multiview contrastive learning framework to learn spatio-temporal quality representations. In particular, we capture the common information between frame differences and frames by treating them as a pair of views and similarly obtain the shared representations between frame differences and optical flow. The resulting features are then compared with a corpus of pristine natural video patches to predict the quality of the distorted video. Detailed experiments on multiple camera captured VQA datasets reveal the superior performance of our method over other features when evaluated without training on human scores.