 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Perceptual Representations for Data-Efficient No-Reference Image Quality Assessment
Dec 08, 2023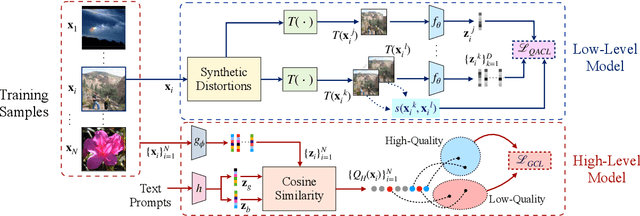
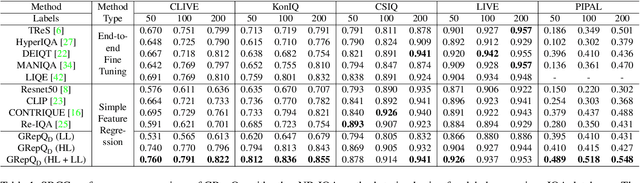
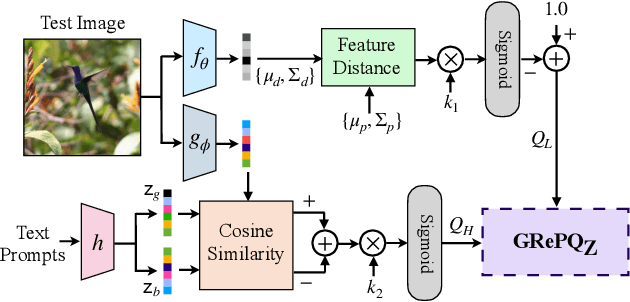
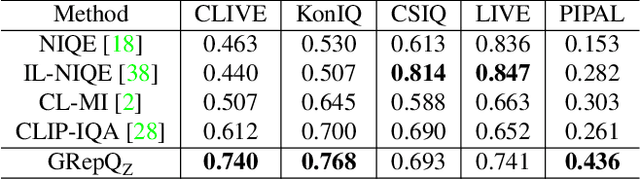
No-reference (NR) image quality assessment (IQA) is an important tool in enhancing the user experience in diverse visual applications. A major drawback of state-of-the-art NR-IQA techniques is their reliance on a large number of human annotations to train models for a target IQA application. To mitigate this requirement, there is a need for unsupervised learning of generalizable quality representations that capture diverse distortions. We enable the learning of low-level quality features agnostic to distortion types by introducing a novel quality-aware contrastive loss. Further, we leverage the generalizability of vision-language models by fine-tuning one such model to extract high-level image quality information through relevant text prompts. The two sets of features are combined to effectively predict quality by training a simple regressor with very few samples on a target dataset. Additionally, we design zero-shot quality predictions from both pathways in a completely blind setting. Our experiments on diverse datasets encompassing various distortions show the generalizability of the features and their superior performance in the data-efficient and zero-shot settings. Code will be made available at https://github.com/suhas-srinath/GRepQ.