 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Input View Synthesis: 3D Representations and Reliable Priors
Nov 20, 2024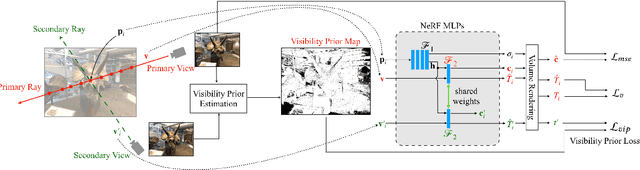



Novel view synthesis refers to the problem of synthesizing novel viewpoints of a scene given the images from a few viewpoints. This is a fundamental problem in computer vision and graphics, and enables a vast variety of applications such as meta-verse, free-view watching of events, video gaming, video stabilization and video compression. Recent 3D representations such as radiance fields and multi-plane images significantly improve the quality of images rendered from novel viewpoints. However, these models require a dense sampling of input views for high quality renders. Their performance goes down significantly when only a few input views are available. In this thesis, we focus on the sparse input novel view synthesis problem for both static and dynamic scenes.
Simple-RF: Regularizing Sparse Input Radiance Fields with Simpler Solutions
Apr 29, 2024Neural Radiance Fields (NeRF) show impressive performance in photo-realistic free-view rendering of scenes. Recent improvements on the NeRF such as TensoRF and ZipNeRF employ explicit models for faster optimization and rendering, as compared to the NeRF that employs an implicit representation. However, both implicit and explicit radiance fields require dense sampling of images in the given scene. Their performance degrades significantly when only a sparse set of views is available. Researchers find that supervising the depth estimated by a radiance field helps train it effectively with fewer views. The depth supervision is obtained either using classical approaches or neural networks pre-trained on a large dataset. While the former may provide only sparse supervision, the latter may suffer from generalization issues. As opposed to the earlier approaches, we seek to learn the depth supervision by designing augmented models and training them along with the main radiance field. Further, we aim to design a framework of regularizations that can work across different implicit and explicit radiance fields. We observe that certain features of these radiance field models overfit to the observed images in the sparse-input scenario. Our key finding is that reducing the capability of the radiance fields with respect to positional encoding, the number of decomposed tensor components or the size of the hash table, constrains the model to learn simpler solutions, which estimate better depth in certain regions. By designing augmented models based on such reduced capabilities, we obtain better depth supervision for the main radiance field. We achieve state-of-the-art view-synthesis performance with sparse input views on popular datasets containing forward-facing and 360$^\circ$ scenes by employing the above regularizations.
Factorized Motion Fields for Fast Sparse Input Dynamic View Synthesis
Apr 19, 2024
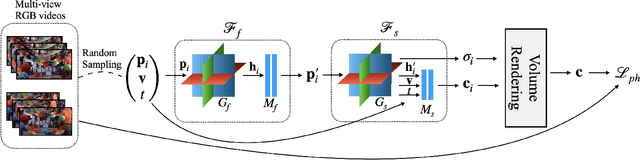

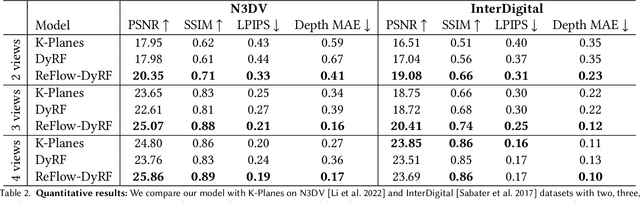
Designing a 3D representation of a dynamic scene for fast optimization and rendering is a challenging task. While recent explicit representations enable fast learning and rendering of dynamic radiance fields, they require a dense set of input viewpoints. In this work, we focus on learning a fast representation for dynamic radiance fields with sparse input viewpoints. However, the optimization with sparse input is under-constrained and necessitates the use of motion priors to constrain the learning. Existing fast dynamic scene models do not explicitly model the motion, making them difficult to be constrained with motion priors. We design an explicit motion model as a factorized 4D representation that is fast and can exploit the spatio-temporal correlation of the motion field. We then introduce reliable flow priors including a combination of sparse flow priors across cameras and dense flow priors within cameras to regularize our motion model. Our model is fast, compact and achieves very good performance on popular multi-view dynamic scene datasets with sparse input viewpoints. The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2024/RF-DeRF.html.
SimpleNeRF: Regularizing Sparse Input Neural Radiance Fields with Simpler Solutions
Sep 14, 2023



Neural Radiance Fields (NeRF) show impressive performance for the photorealistic free-view rendering of scenes. However, NeRFs require dense sampling of images in the given scene, and their performance degrades significantly when only a sparse set of views are available. Researchers have found that supervising the depth estimated by the NeRF helps train it effectively with fewer views. The depth supervision is obtained either using classical approaches or neural networks pre-trained on a large dataset. While the former may provide only sparse supervision, the latter may suffer from generalization issues. As opposed to the earlier approaches, we seek to learn the depth supervision by designing augmented models and training them along with the NeRF. We design augmented models that encourage simpler solutions by exploring the role of positional encoding and view-dependent radiance in training the few-shot NeRF. The depth estimated by these simpler models is used to supervise the NeRF depth estimates. Since the augmented models can be inaccurate in certain regions, we design a mechanism to choose only reliable depth estimates for supervision. Finally, we add a consistency loss between the coarse and fine multi-layer perceptrons of the NeRF to ensure better utilization of hierarchical sampling. We achieve state-of-the-art view-synthesis performance on two popular datasets by employing the above regularizations. The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2023/SimpleNeRF.html
ViP-NeRF: Visibility Prior for Sparse Input Neural Radiance Fields
Apr 28, 2023Neural radiance fields (NeRF) have achieved impressive performances in view synthesis by encoding neural representations of a scene. However, NeRFs require hundreds of images per scene to synthesize photo-realistic novel views. Training them on sparse input views leads to overfitting and incorrect scene depth estimation resulting in artifacts in the rendered novel views. Sparse input NeRFs were recently regularized by providing dense depth estimated from pre-trained networks as supervision, to achieve improved performance over sparse depth constraints. However, we find that such depth priors may be inaccurate due to generalization issues. Instead, we hypothesize that the visibility of pixels in different input views can be more reliably estimated to provide dense supervision. In this regard, we compute a visibility prior through the use of plane sweep volumes, which does not require any pre-training. By regularizing the NeRF training with the visibility prior, we successfully train the NeRF with few input views. We reformulate the NeRF to also directly output the visibility of a 3D point from a given viewpoint to reduce the training time with the visibility constraint. On multiple datasets, our model outperforms the competing sparse input NeRF models including those that use learned priors. The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2023/ViP-NeRF.html.
Temporal View Synthesis of Dynamic Scenes through 3D Object Motion Estimation with Multi-Plane Images
Aug 19, 2022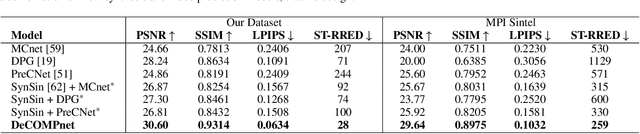
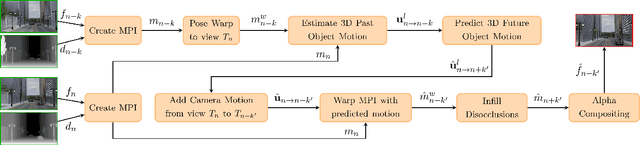


The challenge of graphically rendering high frame-rate videos on low compute devices can be addressed through periodic prediction of future frames to enhance the user experience in virtual reality applications. This is studied through the problem of temporal view synthesis (TVS), where the goal is to predict the next frames of a video given the previous frames and the head poses of the previous and the next frames. In this work, we consider the TVS of dynamic scenes in which both the user and objects are moving. We design a framework that decouples the motion into user and object motion to effectively use the available user motion while predicting the next frames. We predict the motion of objects by isolating and estimating the 3D object motion in the past frames and then extrapolating it. We employ multi-plane images (MPI) as a 3D representation of the scenes and model the object motion as the 3D displacement between the corresponding points in the MPI representation. In order to handle the sparsity in MPIs while estimating the motion, we incorporate partial convolutions and masked correlation layers to estimate corresponding points. The predicted object motion is then integrated with the given user or camera motion to generate the next frame. Using a disocclusion infilling module, we synthesize the regions uncovered due to the camera and object motion. We develop a new synthetic dataset for TVS of dynamic scenes consisting of 800 videos at full HD resolution. We show through experiments on our dataset and the MPI Sintel dataset that our model outperforms all the competing methods in the literature.
Revealing Disocclusions in Temporal View Synthesis through Infilling Vector Prediction
Oct 17, 2021
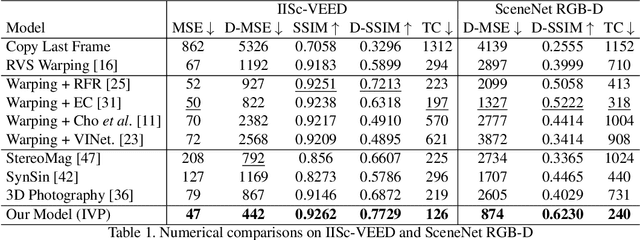
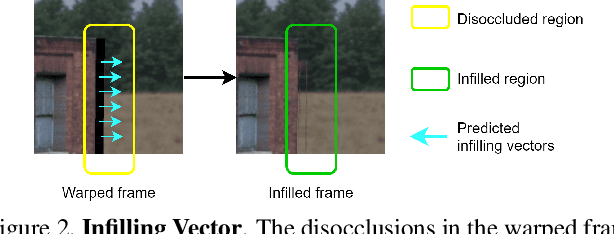

We consider the problem of temporal view synthesis, where the goal is to predict a future video frame from the past frames using knowledge of the depth and relative camera motion. In contrast to revealing the disoccluded regions through intensity based infilling, we study the idea of an infilling vector to infill by pointing to a non-disoccluded region in the synthesized view. To exploit the structure of disocclusions created by camera motion during their infilling, we rely on two important cues, temporal correlation of infilling directions and depth. We design a learning framework to predict the infilling vector by computing a temporal prior that reflects past infilling directions and a normalized depth map as input to the network. We conduct extensive experiments on a large scale dataset we build for evaluating temporal view synthesis in addition to the SceneNet RGB-D dataset. Our experiments demonstrate that our infilling vector prediction approach achieves superior quantitative and qualitative infilling performance compared to other approaches in literature.
A Naturalness Evaluation Database for Video Prediction Models
May 01, 2020

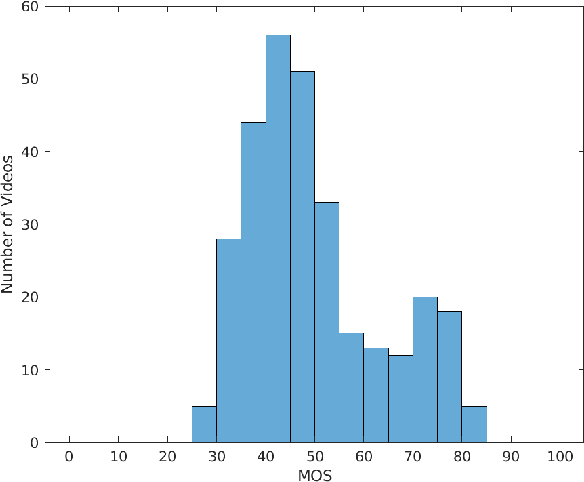
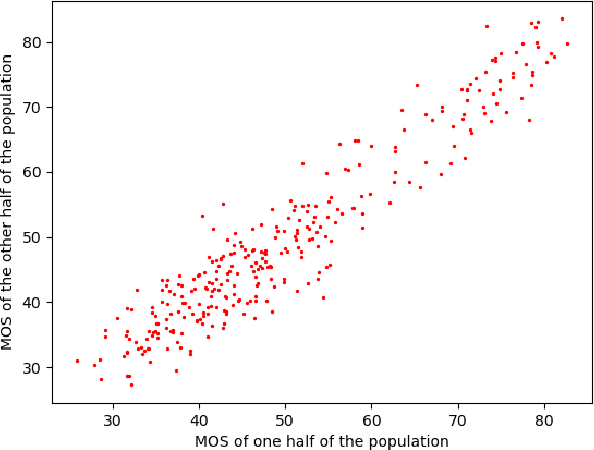
The study of video prediction models is believed to be a fundamental approach to representation learning for videos. While a plethora of generative models for predicting the future frame pixel values given the past few frames exist, the quantitative evaluation of the predicted frames has been found to be extremely challenging. In this context, we introduce the problem of naturalness evaluation, which refers to how natural or realistic a predicted video looks. We create the Indian Institute of Science Video Naturalness Evaluation (IISc VINE) Database consisting of 300 videos, obtained by applying different prediction models on different datasets, and accompanying human opinion scores. 50 human subjects participated in our study yielding around 6000 human ratings of naturalness. Our subjective study reveals that human observers show a highly consistent judgement of naturalness. We benchmark several popularly used measures for evaluating video prediction and show that they do not adequately correlate with the subjective scores. We introduce two new features to help effectively capture naturalness. In particular, we show that motion compensated cosine similarities of deep features of predicted frames with past frames and deep features extracted from rescaled frame differences lead to state of the art naturalness prediction in accordance with human judgements. The database and code will be made publicly available at our project website: https://sites.google.com/site/nagabhushansn95/publications/vine.