 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple-RF: Regularizing Sparse Input Radiance Fields with Simpler Solutions
Apr 29, 2024Neural Radiance Fields (NeRF) show impressive performance in photo-realistic free-view rendering of scenes. Recent improvements on the NeRF such as TensoRF and ZipNeRF employ explicit models for faster optimization and rendering, as compared to the NeRF that employs an implicit representation. However, both implicit and explicit radiance fields require dense sampling of images in the given scene. Their performance degrades significantly when only a sparse set of views is available. Researchers find that supervising the depth estimated by a radiance field helps train it effectively with fewer views. The depth supervision is obtained either using classical approaches or neural networks pre-trained on a large dataset. While the former may provide only sparse supervision, the latter may suffer from generalization issues. As opposed to the earlier approaches, we seek to learn the depth supervision by designing augmented models and training them along with the main radiance field. Further, we aim to design a framework of regularizations that can work across different implicit and explicit radiance fields. We observe that certain features of these radiance field models overfit to the observed images in the sparse-input scenario. Our key finding is that reducing the capability of the radiance fields with respect to positional encoding, the number of decomposed tensor components or the size of the hash table, constrains the model to learn simpler solutions, which estimate better depth in certain regions. By designing augmented models based on such reduced capabilities, we obtain better depth supervision for the main radiance field. We achieve state-of-the-art view-synthesis performance with sparse input views on popular datasets containing forward-facing and 360$^\circ$ scenes by employing the above regularizations.
Factorized Motion Fields for Fast Sparse Input Dynamic View Synthesis
Apr 19, 2024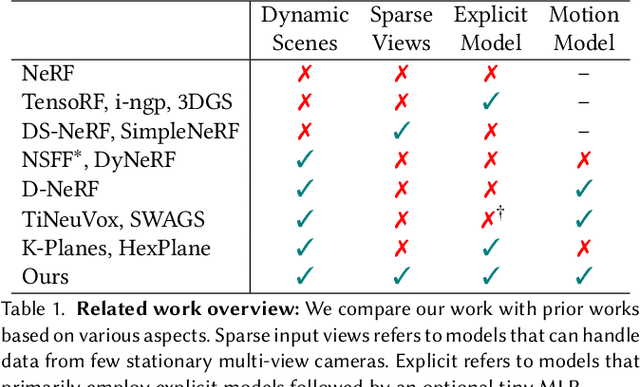
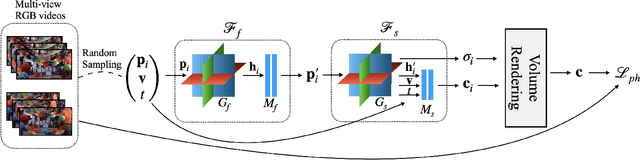

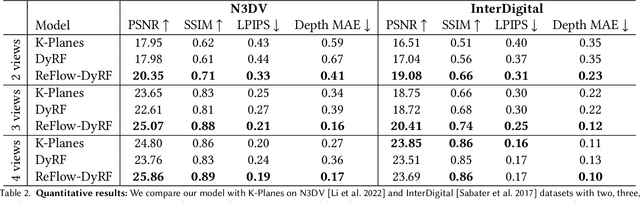
Designing a 3D representation of a dynamic scene for fast optimization and rendering is a challenging task. While recent explicit representations enable fast learning and rendering of dynamic radiance fields, they require a dense set of input viewpoints. In this work, we focus on learning a fast representation for dynamic radiance fields with sparse input viewpoints. However, the optimization with sparse input is under-constrained and necessitates the use of motion priors to constrain the learning. Existing fast dynamic scene models do not explicitly model the motion, making them difficult to be constrained with motion priors. We design an explicit motion model as a factorized 4D representation that is fast and can exploit the spatio-temporal correlation of the motion field. We then introduce reliable flow priors including a combination of sparse flow priors across cameras and dense flow priors within cameras to regularize our motion model. Our model is fast, compact and achieves very good performance on popular multi-view dynamic scene datasets with sparse input viewpoints. The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2024/RF-DeRF.html.