 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Naturalness Evaluation Database for Video Prediction Models
May 01, 2020

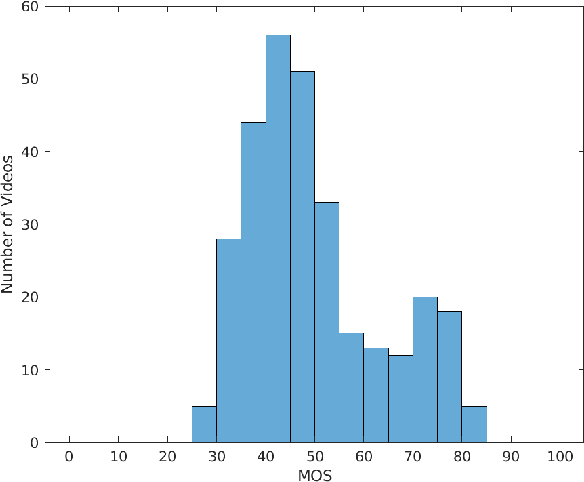
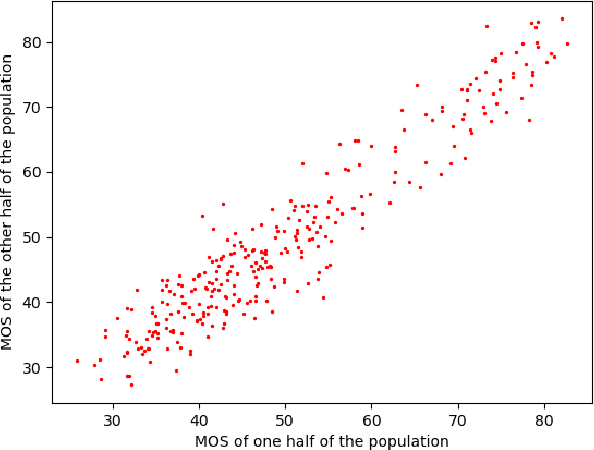
The study of video prediction models is believed to be a fundamental approach to representation learning for videos. While a plethora of generative models for predicting the future frame pixel values given the past few frames exist, the quantitative evaluation of the predicted frames has been found to be extremely challenging. In this context, we introduce the problem of naturalness evaluation, which refers to how natural or realistic a predicted video looks. We create the Indian Institute of Science Video Naturalness Evaluation (IISc VINE) Database consisting of 300 videos, obtained by applying different prediction models on different datasets, and accompanying human opinion scores. 50 human subjects participated in our study yielding around 6000 human ratings of naturalness. Our subjective study reveals that human observers show a highly consistent judgement of naturalness. We benchmark several popularly used measures for evaluating video prediction and show that they do not adequately correlate with the subjective scores. We introduce two new features to help effectively capture naturalness. In particular, we show that motion compensated cosine similarities of deep features of predicted frames with past frames and deep features extracted from rescaled frame differences lead to state of the art naturalness prediction in accordance with human judgements. The database and code will be made publicly available at our project website: https://sites.google.com/site/nagabhushansn95/publications/vine.
Human peripheral blur is optimal for object recognition
Jul 23, 2018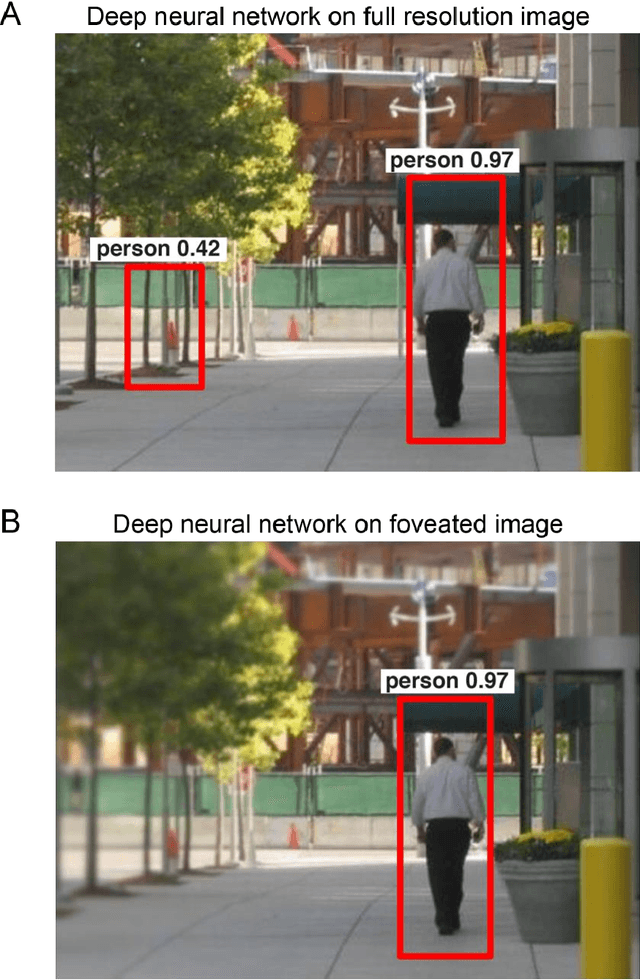
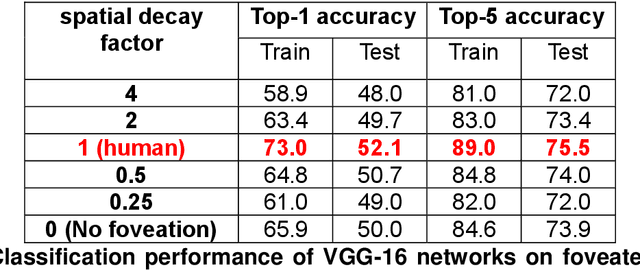


Our eyes sample a disproportionately large amount of information at the centre of gaze with increasingly sparse sampling into the periphery. This sampling scheme is widely believed to be a wiring constraint whereby high resolution at the centre is achieved by sacrificing spatial acuity in the periphery. Here we propose that this sampling scheme may be optimal for object recognition because the relevant spatial content is dense near an object and sparse in the surrounding vicinity. We tested this hypothesis by training deep convolutional neural networks on full-resolution and foveated images. Our main finding is that networks trained on images with foveated sampling show better object classification compared to networks trained on full resolution images. Importantly, blurring images according to the human blur function yielded the best performance compared to images with shallower or steeper blurring. Taken together our results suggest that, peripheral blurring in our eyes may have evolved for optimal object recognition, rather than merely to satisfy wiring constraints.
Deep neural networks can be improved using human-derived contextual expectations
Mar 29, 2018
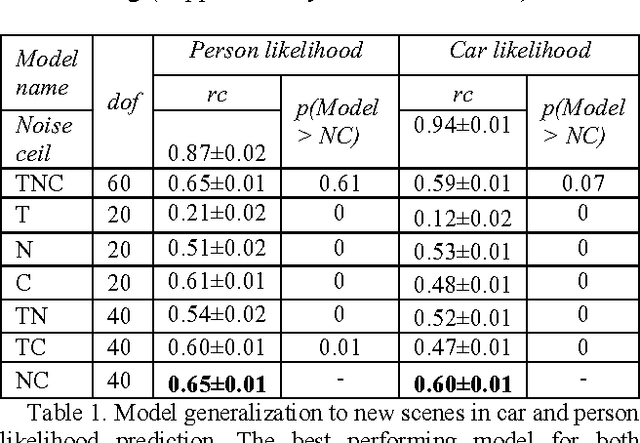
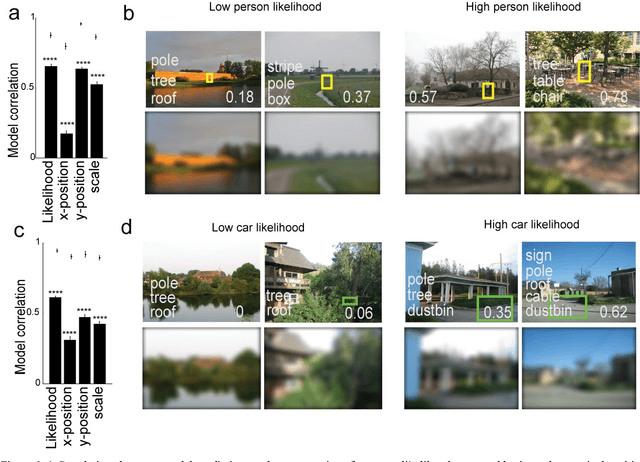
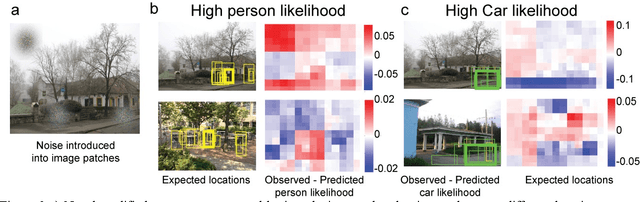
Real-world objects occur in specific contexts. Such context has been shown to facilitate detection by constraining the locations to search. But can context directly benefit object detection? To do so, context needs to be learned independently from target features. This is impossible in traditional object detection where classifiers are trained on images containing both target features and surrounding context. In contrast, humans can learn context and target features separately, such as when we see highways without cars. Here we show for the first time that human-derived scene expectations can be used to improve object detection performance in machines. To measure contextual expectations, we asked human subjects to indicate the scale, location and likelihood at which cars or people might occur in scenes without these objects. Humans showed highly systematic expectations that we could accurately predict using scene features. This allowed us to predict human expectations on novel scenes without requiring manual annotation. On augmenting deep neural networks with predicted human expectations, we obtained substantial gains in accuracy for detecting cars and people (1-3%) as well as on detecting associated objects (3-20%). In contrast, augmenting deep networks with other conventional features yielded far smaller gains. This improvement was due to relatively poor matches at highly likely locations being correctly labelled as target and conversely strong matches at unlikely locations being correctly rejected as false alarms. Taken together, our results show that augmenting deep neural networks with human-derived context features improves their performance, suggesting that humans learn scene context separately unlike deep networks.
Can you tell where in India I am from? Comparing humans and computers on fine-grained race face classification
Feb 19, 2018
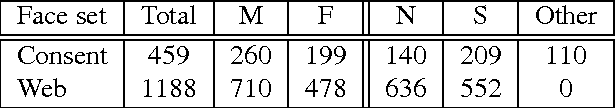
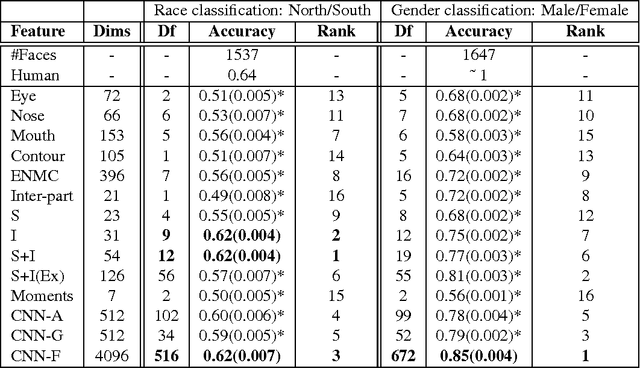
Faces form the basis for a rich variety of judgments in humans, yet the underlying features remain poorly understood. Although fine-grained distinctions within a race might more strongly constrain possible facial features used by humans than in case of coarse categories such as race or gender, such fine grained distinctions are relatively less studied. Fine-grained race classification is also interesting because even humans may not be perfectly accurate on these tasks. This allows us to compare errors made by humans and machines, in contrast to standard object detection tasks where human performance is nearly perfect. We have developed a novel face database of close to 1650 diverse Indian faces labeled for fine-grained race (South vs North India) as well as for age, weight, height and gender. We then asked close to 130 human subjects who were instructed to categorize each face as belonging toa Northern or Southern state in India. We then compared human performance on this task with that of computational models trained on the ground-truth labels. Our main results are as follows: (1) Humans are highly consistent (average accuracy: 63.6%), with some faces being consistently classified with > 90% accuracy and others consistently misclassified with < 30% accuracy; (2) Models trained on ground-truth labels showed slightly worse performance (average accuracy: 62%) but showed higher accuracy (72.2%) on faces classified with > 80% accuracy by humans. This was true for models trained on simple spatial and intensity measurements extracted from faces as well as deep neural networks trained on race or gender classification; (3) Using overcomplete banks of features derived from each face part, we found that mouth shape was the single largest contributor towards fine-grained race classification, whereas distances between face parts was the strongest predictor of gender.