 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModulation of early visual processing alleviates capacity limits in solving multiple tasks
Jul 30, 2019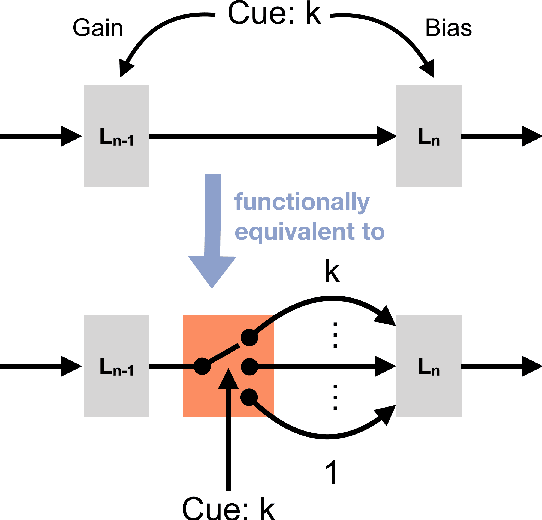
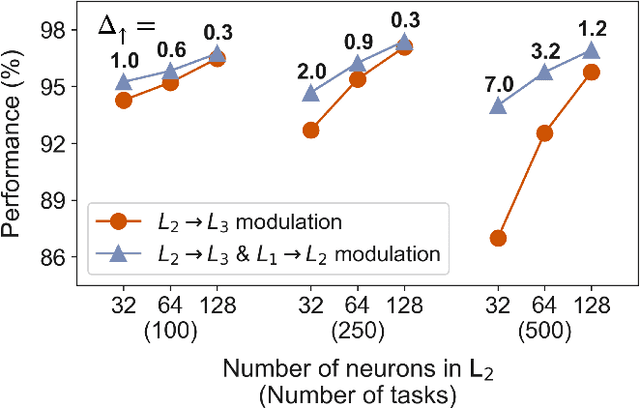
In daily life situations, we have to perform multiple tasks given a visual stimulus, which requires task-relevant information to be transmitted through our visual system. When it is not possible to transmit all the possibly relevant information to higher layers, due to a bottleneck, task-based modulation of early visual processing might be necessary. In this work, we report how the effectiveness of modulating the early processing stage of an artificial neural network depends on the information bottleneck faced by the network. The bottleneck is quantified by the number of tasks the network has to perform and the neural capacity of the later stage of the network. The effectiveness is gauged by the performance on multiple object detection tasks, where the network is trained with a recent multi-task optimization scheme. By associating neural modulations with task-based switching of the state of the network and characterizing when such switching is helpful in early processing, our results provide a functional perspective towards understanding why task-based modulation of early neural processes might be observed in the primate visual cortex
Deep neural networks can be improved using human-derived contextual expectations
Mar 29, 2018
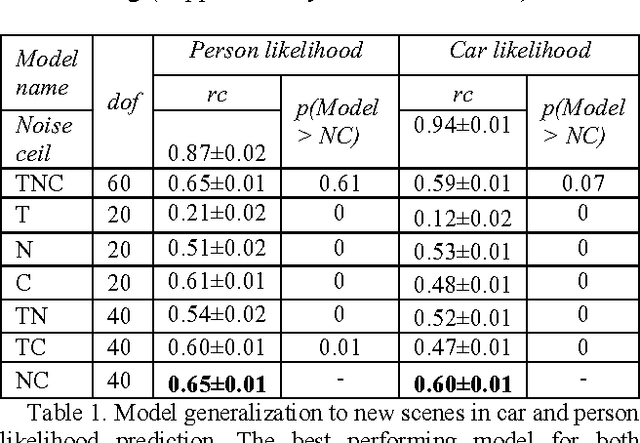
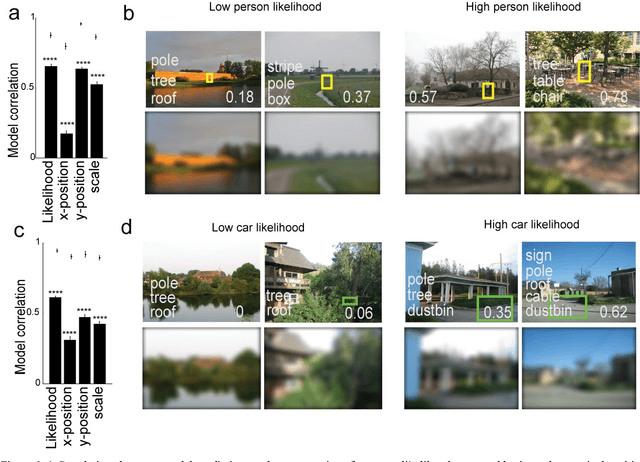
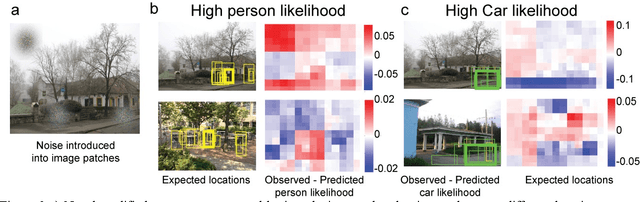
Real-world objects occur in specific contexts. Such context has been shown to facilitate detection by constraining the locations to search. But can context directly benefit object detection? To do so, context needs to be learned independently from target features. This is impossible in traditional object detection where classifiers are trained on images containing both target features and surrounding context. In contrast, humans can learn context and target features separately, such as when we see highways without cars. Here we show for the first time that human-derived scene expectations can be used to improve object detection performance in machines. To measure contextual expectations, we asked human subjects to indicate the scale, location and likelihood at which cars or people might occur in scenes without these objects. Humans showed highly systematic expectations that we could accurately predict using scene features. This allowed us to predict human expectations on novel scenes without requiring manual annotation. On augmenting deep neural networks with predicted human expectations, we obtained substantial gains in accuracy for detecting cars and people (1-3%) as well as on detecting associated objects (3-20%). In contrast, augmenting deep networks with other conventional features yielded far smaller gains. This improvement was due to relatively poor matches at highly likely locations being correctly labelled as target and conversely strong matches at unlikely locations being correctly rejected as false alarms. Taken together, our results show that augmenting deep neural networks with human-derived context features improves their performance, suggesting that humans learn scene context separately unlike deep networks.