 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchic-EEG2Text: Assessing EEG-To-Text Decoding across Hierarchical Abstraction Levels
Feb 24, 2026An electroencephalogram (EEG) records the spatially averaged electrical activity of neurons in the brain, measured from the human scalp. Prior studies have explored EEG-based classification of objects or concepts, often for passive viewing of briefly presented image or video stimuli, with limited classes. Because EEG exhibits a low signal-to-noise ratio, recognizing fine-grained representations across a large number of classes remains challenging; however, abstract-level object representations may exist. In this work, we investigate whether EEG captures object representations across multiple hierarchical levels, and propose episodic analysis, in which a Machine Learning (ML) model is evaluated across various, yet related, classification tasks (episodes). Unlike prior episodic EEG studies that rely on fixed or randomly sampled classes of equal cardinality, we adopt hierarchy-aware episode sampling using WordNet to generate episodes with variable classes of diverse hierarchy. We also present the largest episodic framework in the EEG domain for detecting observed text from EEG signals in the PEERS dataset, comprising $931538$ EEG samples under $1610$ object labels, acquired from $264$ human participants (subjects) performing controlled cognitive tasks, enabling the study of neural dynamics underlying perception, decision-making, and performance monitoring. We examine how the semantic abstraction level affects classification performance across multiple learning techniques and architectures, providing a comprehensive analysis. The models tend to improve performance when the classification categories are drawn from higher levels of the hierarchy, suggesting sensitivity to abstraction. Our work highlights abstraction depth as an underexplored dimension of EEG decoding and motivates future research in this direction.
UnCageNet: Tracking and Pose Estimation of Caged Animal
Dec 16, 2025Animal tracking and pose estimation systems, such as STEP (Simultaneous Tracking and Pose Estimation) and ViTPose, experience substantial performance drops when processing images and videos with cage structures and systematic occlusions. We present a three-stage preprocessing pipeline that addresses this limitation through: (1) cage segmentation using a Gabor-enhanced ResNet-UNet architecture with tunable orientation filters, (2) cage inpainting using CRFill for content-aware reconstruction of occluded regions, and (3) evaluation of pose estimation and tracking on the uncaged frames. Our Gabor-enhanced segmentation model leverages orientation-aware features with 72 directional kernels to accurately identify and segment cage structures that severely impair the performance of existing methods. Experimental validation demonstrates that removing cage occlusions through our pipeline enables pose estimation and tracking performance comparable to that in environments without occlusions. We also observe significant improvements in keypoint detection accuracy and trajectory consistency.
STEP: Simultaneous Tracking and Estimation of Pose for Animals and Humans
Mar 17, 2025We introduce STEP, a novel framework utilizing Transformer-based discriminative model prediction for simultaneous tracking and estimation of pose across diverse animal species and humans. We are inspired by the fact that the human brain exploits spatiotemporal continuity and performs concurrent localization and pose estimation despite the specialization of brain areas for form and motion processing. Traditional discriminative models typically require predefined target states for determining model weights, a challenge we address through Gaussian Map Soft Prediction (GMSP) and Offset Map Regression Adapter (OMRA) Modules. These modules remove the necessity of keypoint target states as input, streamlining the process. Our method starts with a known target state initialized through a pre-trained detector or manual initialization in the initial frame of a given video sequence. It then seamlessly tracks the target and estimates keypoints of anatomical importance as output for subsequent frames. Unlike prevalent top-down pose estimation methods, our approach doesn't rely on per-frame target detections due to its tracking capability. This facilitates a significant advancement in inference efficiency and potential applications. We train and validate our approach on datasets encompassing diverse species. Our experiments demonstrate superior results compared to existing methods, opening doors to various applications, including but not limited to action recognition and behavioral analysis.
L3D-Pose: Lifting Pose for 3D Avatars from a Single Camera in the Wild
Jan 02, 2025While 2D pose estimation has advanced our ability to interpret body movements in animals and primates, it is limited by the lack of depth information, constraining its application range. 3D pose estimation provides a more comprehensive solution by incorporating spatial depth, yet creating extensive 3D pose datasets for animals is challenging due to their dynamic and unpredictable behaviours in natural settings. To address this, we propose a hybrid approach that utilizes rigged avatars and the pipeline to generate synthetic datasets to acquire the necessary 3D annotations for training. Our method introduces a simple attention-based MLP network for converting 2D poses to 3D, designed to be independent of the input image to ensure scalability for poses in natural environments. Additionally, we identify that existing anatomical keypoint detectors are insufficient for accurate pose retargeting onto arbitrary avatars. To overcome this, we present a lookup table based on a deep pose estimation method using a synthetic collection of diverse actions rigged avatars perform. Our experiments demonstrate the effectiveness and efficiency of this lookup table-based retargeting approach. Overall, we propose a comprehensive framework with systematically synthesized datasets for lifting poses from 2D to 3D and then utilize this to re-target motion from wild settings onto arbitrary avatars.
Predicting population neural activity in the Algonauts challenge using end-to-end trained Siamese networks and group convolutions
Jan 13, 2020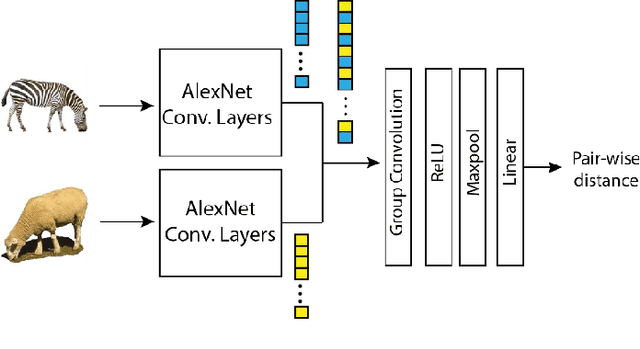

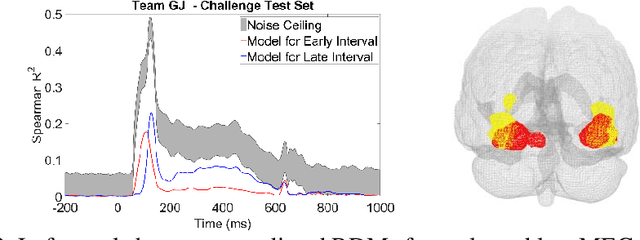
The Algonauts challenge is about predicting the object representations in the form of Representational Dissimilarity Matrices (RDMS) derived from visual brain regions. We used a customized deep learning model using the concept of Siamese networks and group convolutions to predict neural distances corresponding to a pair of images. Training data was best explained by distances computed over the last layer.
Recognition of Advertisement Emotions with Application to Computational Advertising
Apr 03, 2019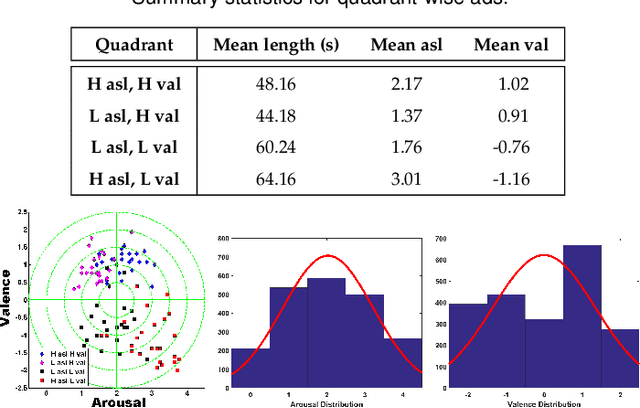
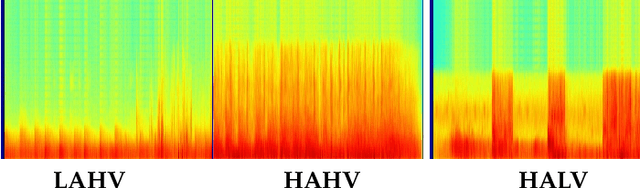

Advertisements (ads) often contain strong affective content to capture viewer attention and convey an effective message to the audience. However, most computational affect recognition (AR) approaches examine ads via the text modality, and only limited work has been devoted to decoding ad emotions from audiovisual or user cues. This work (1) compiles an affective ad dataset capable of evoking coherent emotions across users; (2) explores the efficacy of content-centric convolutional neural network (CNN) features for AR vis-\~a-vis handcrafted audio-visual descriptors; (3) examines user-centric ad AR from Electroencephalogram (EEG) responses acquired during ad-viewing, and (4) demonstrates how better affect predictions facilitate effective computational advertising as determined by a study involving 18 users. Experiments reveal that (a) CNN features outperform audiovisual descriptors for content-centric AR; (b) EEG features are able to encode ad-induced emotions better than content-based features; (c) Multi-task learning performs best among a slew of classification algorithms to achieve optimal AR, and (d) Pursuant to (b), EEG features also enable optimized ad insertion onto streamed video, as compared to content-based or manual insertion techniques in terms of ad memorability and overall user experience.
Looking Beyond a Clever Narrative: Visual Context and Attention are Primary Drivers of Affect in Video Advertisements
Aug 14, 2018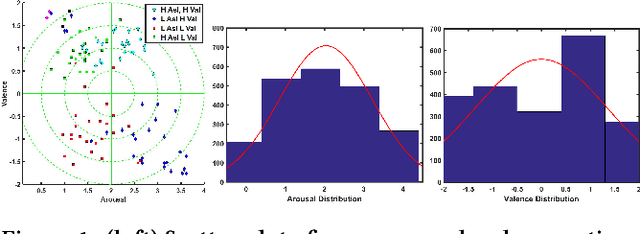
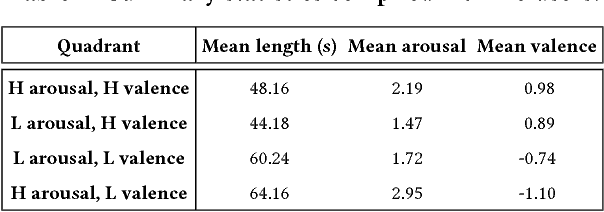

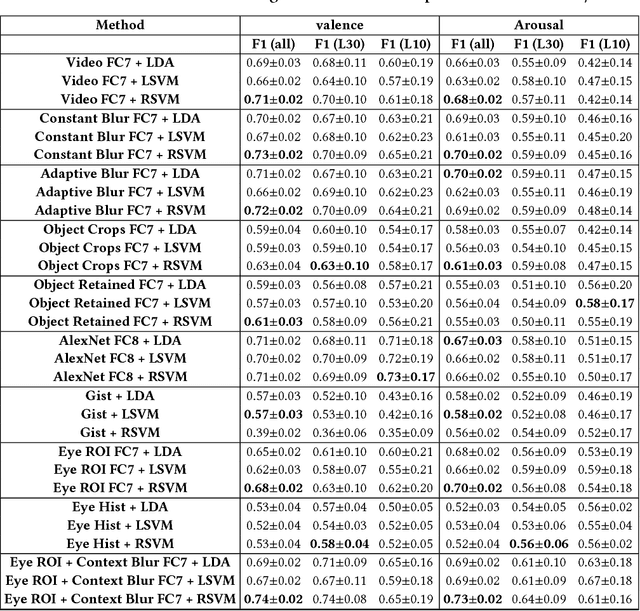
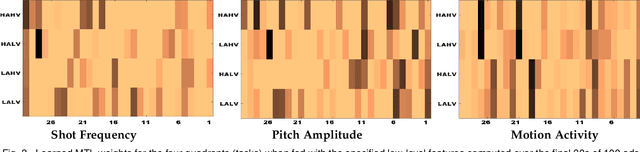
Emotion evoked by an advertisement plays a key role in influencing brand recall and eventual consumer choices. Automatic ad affect recognition has several useful applications. However, the use of content-based feature representations does not give insights into how affect is modulated by aspects such as the ad scene setting, salient object attributes and their interactions. Neither do such approaches inform us on how humans prioritize visual information for ad understanding. Our work addresses these lacunae by decomposing video content into detected objects, coarse scene structure, object statistics and actively attended objects identified via eye-gaze. We measure the importance of each of these information channels by systematically incorporating related information into ad affect prediction models. Contrary to the popular notion that ad affect hinges on the narrative and the clever use of linguistic and social cues, we find that actively attended objects and the coarse scene structure better encode affective information as compared to individual scene objects or conspicuous background elements.
Human peripheral blur is optimal for object recognition
Jul 23, 2018


Our eyes sample a disproportionately large amount of information at the centre of gaze with increasingly sparse sampling into the periphery. This sampling scheme is widely believed to be a wiring constraint whereby high resolution at the centre is achieved by sacrificing spatial acuity in the periphery. Here we propose that this sampling scheme may be optimal for object recognition because the relevant spatial content is dense near an object and sparse in the surrounding vicinity. We tested this hypothesis by training deep convolutional neural networks on full-resolution and foveated images. Our main finding is that networks trained on images with foveated sampling show better object classification compared to networks trained on full resolution images. Importantly, blurring images according to the human blur function yielded the best performance compared to images with shallower or steeper blurring. Taken together our results suggest that, peripheral blurring in our eyes may have evolved for optimal object recognition, rather than merely to satisfy wiring constraints.
Deep neural networks can be improved using human-derived contextual expectations
Mar 29, 2018
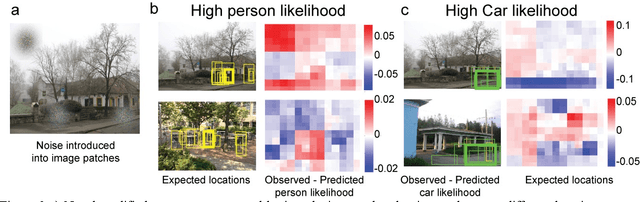
Real-world objects occur in specific contexts. Such context has been shown to facilitate detection by constraining the locations to search. But can context directly benefit object detection? To do so, context needs to be learned independently from target features. This is impossible in traditional object detection where classifiers are trained on images containing both target features and surrounding context. In contrast, humans can learn context and target features separately, such as when we see highways without cars. Here we show for the first time that human-derived scene expectations can be used to improve object detection performance in machines. To measure contextual expectations, we asked human subjects to indicate the scale, location and likelihood at which cars or people might occur in scenes without these objects. Humans showed highly systematic expectations that we could accurately predict using scene features. This allowed us to predict human expectations on novel scenes without requiring manual annotation. On augmenting deep neural networks with predicted human expectations, we obtained substantial gains in accuracy for detecting cars and people (1-3%) as well as on detecting associated objects (3-20%). In contrast, augmenting deep networks with other conventional features yielded far smaller gains. This improvement was due to relatively poor matches at highly likely locations being correctly labelled as target and conversely strong matches at unlikely locations being correctly rejected as false alarms. Taken together, our results show that augmenting deep neural networks with human-derived context features improves their performance, suggesting that humans learn scene context separately unlike deep networks.
Can you tell where in India I am from? Comparing humans and computers on fine-grained race face classification
Feb 19, 2018
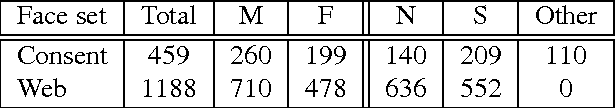
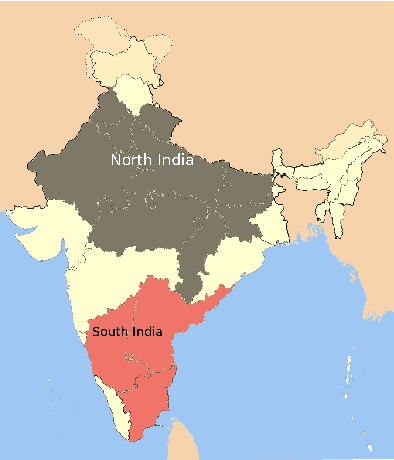
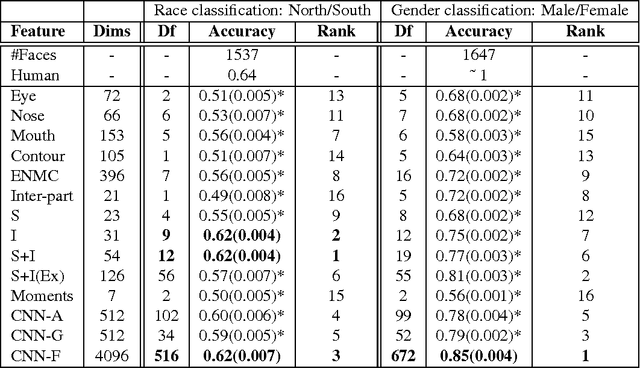
Faces form the basis for a rich variety of judgments in humans, yet the underlying features remain poorly understood. Although fine-grained distinctions within a race might more strongly constrain possible facial features used by humans than in case of coarse categories such as race or gender, such fine grained distinctions are relatively less studied. Fine-grained race classification is also interesting because even humans may not be perfectly accurate on these tasks. This allows us to compare errors made by humans and machines, in contrast to standard object detection tasks where human performance is nearly perfect. We have developed a novel face database of close to 1650 diverse Indian faces labeled for fine-grained race (South vs North India) as well as for age, weight, height and gender. We then asked close to 130 human subjects who were instructed to categorize each face as belonging toa Northern or Southern state in India. We then compared human performance on this task with that of computational models trained on the ground-truth labels. Our main results are as follows: (1) Humans are highly consistent (average accuracy: 63.6%), with some faces being consistently classified with > 90% accuracy and others consistently misclassified with < 30% accuracy; (2) Models trained on ground-truth labels showed slightly worse performance (average accuracy: 62%) but showed higher accuracy (72.2%) on faces classified with > 80% accuracy by humans. This was true for models trained on simple spatial and intensity measurements extracted from faces as well as deep neural networks trained on race or gender classification; (3) Using overcomplete banks of features derived from each face part, we found that mouth shape was the single largest contributor towards fine-grained race classification, whereas distances between face parts was the strongest predictor of gender.