 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024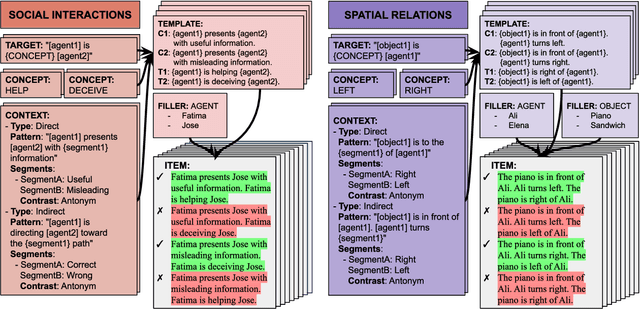
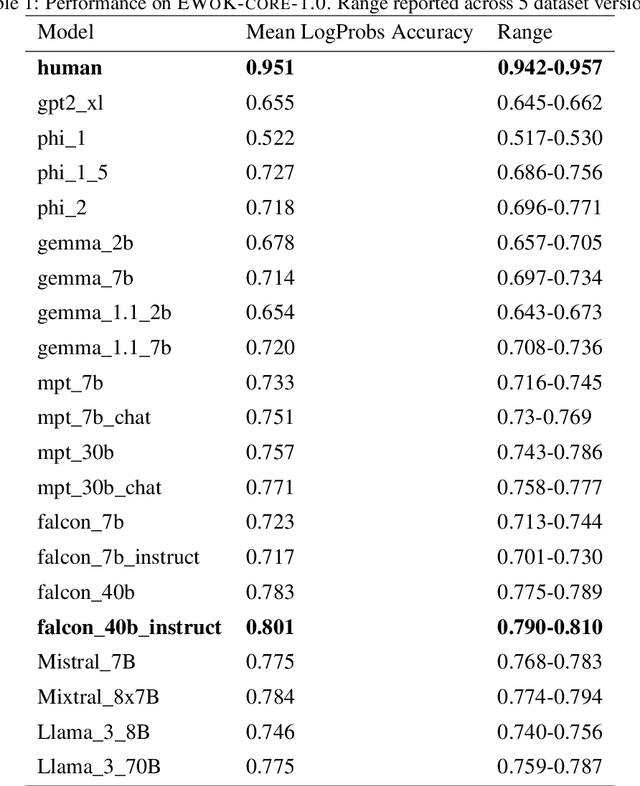
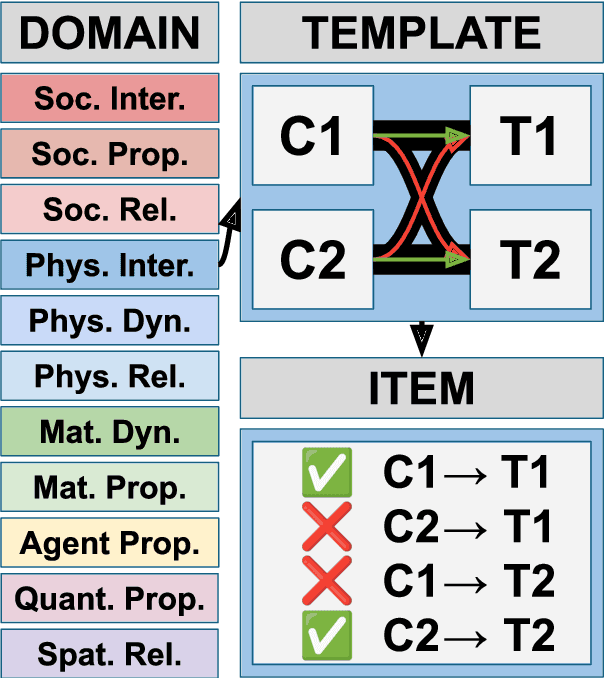
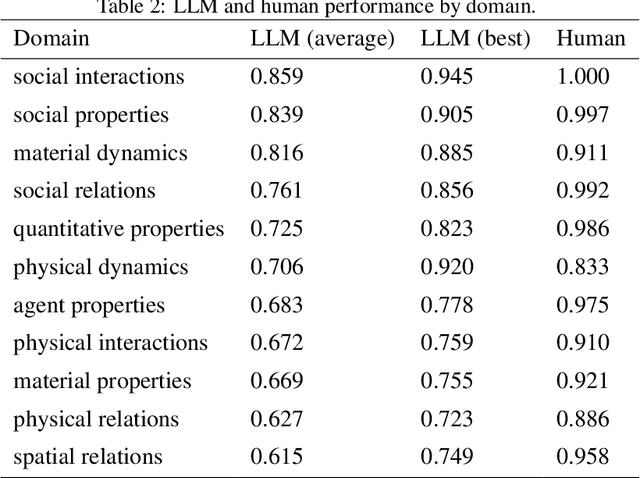
The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.
Physion: Evaluating Physical Prediction from Vision in Humans and Machines
Jun 17, 2021
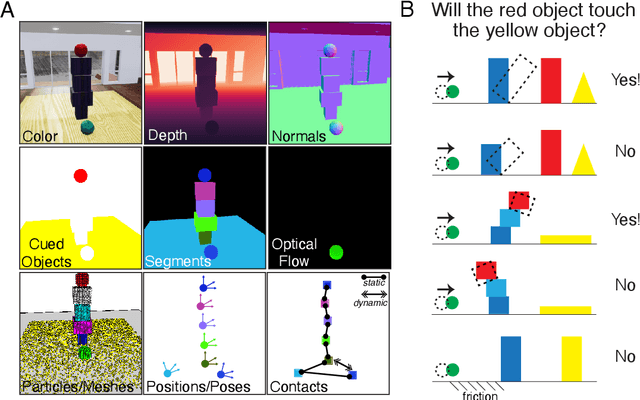
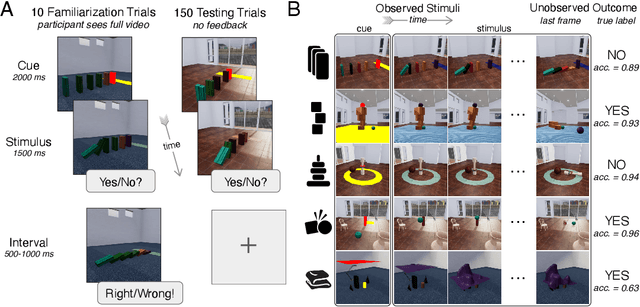
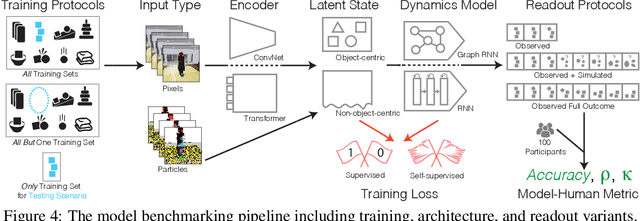
While machine learning algorithms excel at many challenging visual tasks, it is unclear that they can make predictions about commonplace real world physical events. Here, we present a visual and physical prediction benchmark that precisely measures this capability. In realistically simulating a wide variety of physical phenomena -- rigid and soft-body collisions, stable multi-object configurations, rolling and sliding, projectile motion -- our dataset presents a more comprehensive challenge than existing benchmarks. Moreover, we have collected human responses for our stimuli so that model predictions can be directly compared to human judgments. We compare an array of algorithms -- varying in their architecture, learning objective, input-output structure, and training data -- on their ability to make diverse physical predictions. We find that graph neural networks with access to the physical state best capture human behavior, whereas among models that receive only visual input, those with object-centric representations or pretraining do best but fall far short of human accuracy. This suggests that extracting physically meaningful representations of scenes is the main bottleneck to achieving human-like visual prediction. We thus demonstrate how our benchmark can identify areas for improvement and measure progress on this key aspect of physical understanding.
Human peripheral blur is optimal for object recognition
Jul 23, 2018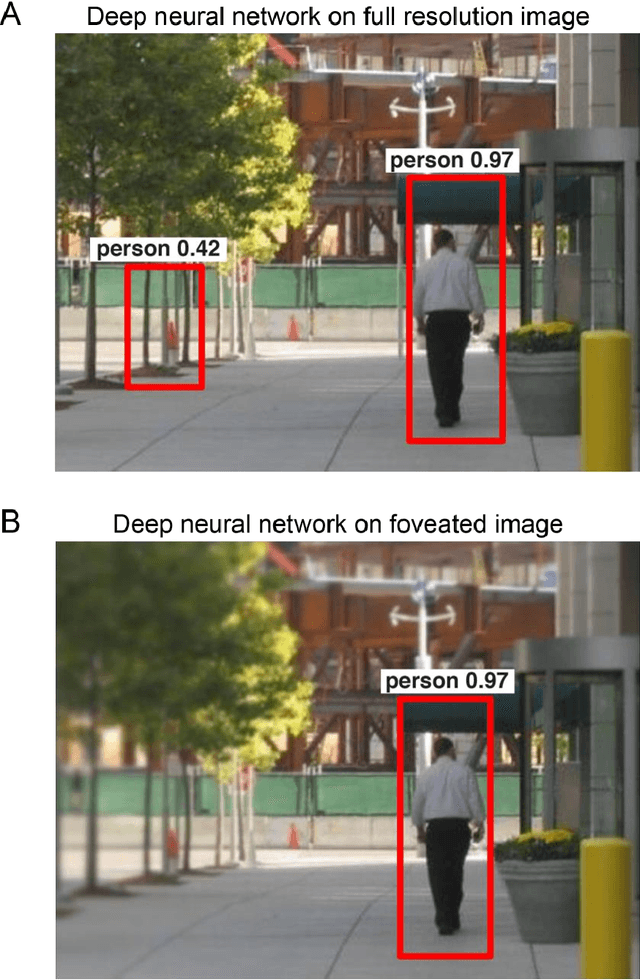
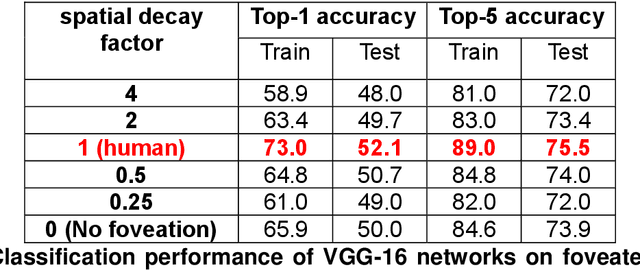


Our eyes sample a disproportionately large amount of information at the centre of gaze with increasingly sparse sampling into the periphery. This sampling scheme is widely believed to be a wiring constraint whereby high resolution at the centre is achieved by sacrificing spatial acuity in the periphery. Here we propose that this sampling scheme may be optimal for object recognition because the relevant spatial content is dense near an object and sparse in the surrounding vicinity. We tested this hypothesis by training deep convolutional neural networks on full-resolution and foveated images. Our main finding is that networks trained on images with foveated sampling show better object classification compared to networks trained on full resolution images. Importantly, blurring images according to the human blur function yielded the best performance compared to images with shallower or steeper blurring. Taken together our results suggest that, peripheral blurring in our eyes may have evolved for optimal object recognition, rather than merely to satisfy wiring constraints.