 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability-Inspired Layer-Wise Pruning of Deep Neural Networks for Efficient Object Detection
Feb 15, 2026Deep neural networks (DNNs) have achieved remarkable success in object detection tasks, but their increasing complexity poses significant challenges for deployment on resource-constrained platforms. While model compression techniques such as pruning have emerged as essential tools, traditional magnitude-based pruning methods do not necessarily align with the true functional contribution of network components to task-specific performance. In this work, we present an explainability-inspired, layer-wise pruning framework tailored for efficient object detection. Our approach leverages a SHAP-inspired gradient--activation attribution to estimate layer importance, providing a data-driven proxy for functional contribution rather than relying solely on static weight magnitudes. We conduct comprehensive experiments across diverse object detection architectures, including ResNet-50, MobileNetV2, ShuffleNetV2, Faster R-CNN, RetinaNet, and YOLOv8, evaluating performance on the Microsoft COCO 2017 validation set. The results show that the proposed attribution-inspired pruning consistently identifies different layers as least important compared to L1-norm-based methods, leading to improved accuracy--efficiency trade-offs. Notably, for ShuffleNetV2, our method yields a 10\% empirical increase in inference speed, whereas L1-pruning degrades performance by 13.7\%. For RetinaNet, the proposed approach preserves the baseline mAP (0.151) with negligible impact on inference speed, while L1-pruning incurs a 1.3\% mAP drop for a 6.2\% speed increase. These findings highlight the importance of data-driven layer importance assessment and demonstrate that explainability-inspired compression offers a principled direction for deploying deep neural networks on edge and resource-constrained platforms while preserving both performance and interpretability.
MatMamba: A Matryoshka State Space Model
Oct 09, 2024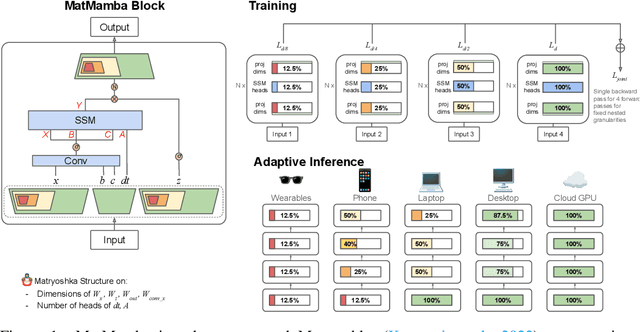



State Space Models (SSMs) like Mamba2 are a promising alternative to Transformers, with faster theoretical training and inference times -- especially for long context lengths. Recent work on Matryoshka Representation Learning -- and its application to Transformer backbones in works like MatFormer -- showed how to introduce nested granularities of smaller submodels in one universal elastic model. In this work, we present MatMamba: a state space model which combines Matryoshka-style learning with Mamba2, by modifying the block to contain nested dimensions to enable joint training and adaptive inference. MatMamba allows for efficient and adaptive deployment across various model sizes. We train a single large MatMamba model and are able to get a number of smaller nested models for free -- while maintaining or improving upon the performance of a baseline smaller model trained from scratch. We train language and image models at a variety of parameter sizes from 35M to 1.4B. Our results on ImageNet and FineWeb show that MatMamba models scale comparably to Transformers, while having more efficient inference characteristics. This makes MatMamba a practically viable option for deploying large-scale models in an elastic way based on the available inference compute. Code and models are open sourced at \url{https://github.com/ScaledFoundations/MatMamba}
GRID: A Platform for General Robot Intelligence Development
Oct 07, 2023



Developing machine intelligence abilities in robots and autonomous systems is an expensive and time consuming process. Existing solutions are tailored to specific applications and are harder to generalize. Furthermore, scarcity of training data adds a layer of complexity in deploying deep machine learning models. We present a new platform for General Robot Intelligence Development (GRID) to address both of these issues. The platform enables robots to learn, compose and adapt skills to their physical capabilities, environmental constraints and goals. The platform addresses AI problems in robotics via foundation models that know the physical world. GRID is designed from the ground up to be extensible to accommodate new types of robots, vehicles, hardware platforms and software protocols. In addition, the modular design enables various deep ML components and existing foundation models to be easily usable in a wider variety of robot-centric problems. We demonstrate the platform in various aerial robotics scenarios and demonstrate how the platform dramatically accelerates development of machine intelligent robots.
Egocentric Auditory Attention Localization in Conversations
Mar 28, 2023


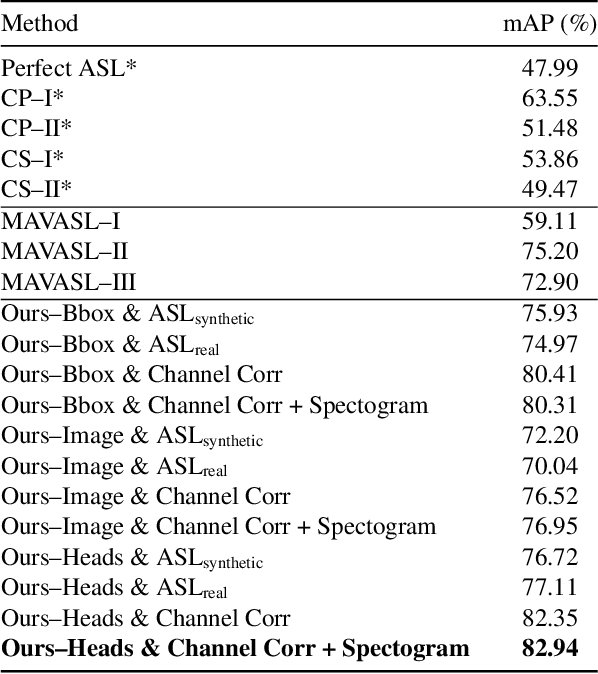
In a noisy conversation environment such as a dinner party, people often exhibit selective auditory attention, or the ability to focus on a particular speaker while tuning out others. Recognizing who somebody is listening to in a conversation is essential for developing technologies that can understand social behavior and devices that can augment human hearing by amplifying particular sound sources. The computer vision and audio research communities have made great strides towards recognizing sound sources and speakers in scenes. In this work, we take a step further by focusing on the problem of localizing auditory attention targets in egocentric video, or detecting who in a camera wearer's field of view they are listening to. To tackle the new and challenging Selective Auditory Attention Localization problem, we propose an end-to-end deep learning approach that uses egocentric video and multichannel audio to predict the heatmap of the camera wearer's auditory attention. Our approach leverages spatiotemporal audiovisual features and holistic reasoning about the scene to make predictions, and outperforms a set of baselines on a challenging multi-speaker conversation dataset. Project page: https://fkryan.github.io/saal
Learning Speech Representations from Raw Audio by Joint Audiovisual Self-Supervision
Jul 08, 2020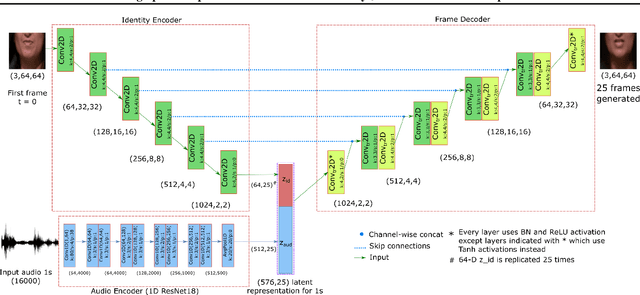
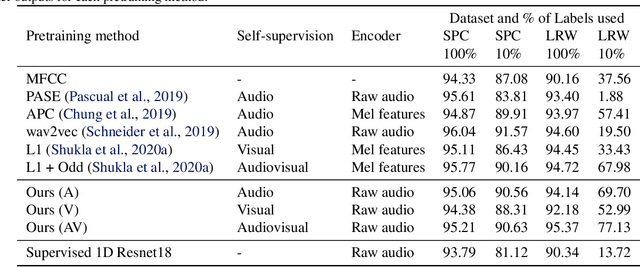
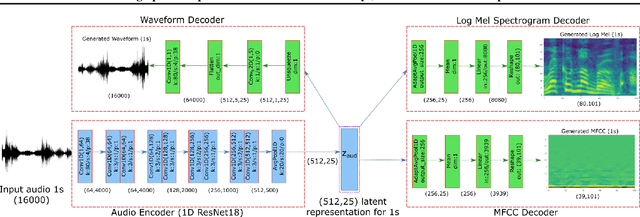
The intuitive interaction between the audio and visual modalities is valuable for cross-modal self-supervised learning. This concept has been demonstrated for generic audiovisual tasks like video action recognition and acoustic scene classification. However, self-supervision remains under-explored for audiovisual speech. We propose a method to learn self-supervised speech representations from the raw audio waveform. We train a raw audio encoder by combining audio-only self-supervision (by predicting informative audio attributes) with visual self-supervision (by generating talking faces from audio). The visual pretext task drives the audio representations to capture information related to lip movements. This enriches the audio encoder with visual information and the encoder can be used for evaluation without the visual modality. Our method attains competitive performance with respect to existing self-supervised audio features on established isolated word classification benchmarks, and significantly outperforms other methods at learning from fewer labels. Notably, our method also outperforms fully supervised training, thus providing a strong initialization for speech related tasks. Our results demonstrate the potential of multimodal self-supervision in audiovisual speech for learning good audio representations.
Does Visual Self-Supervision Improve Learning of Speech Representations?
May 04, 2020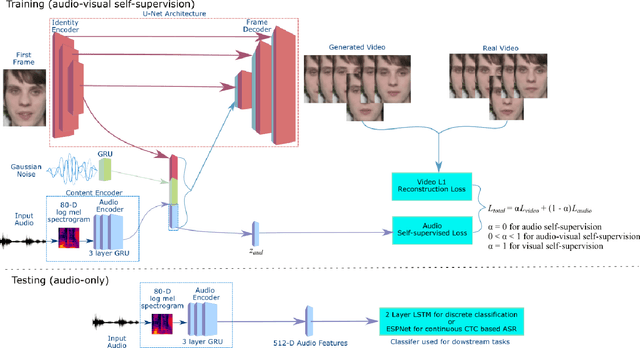
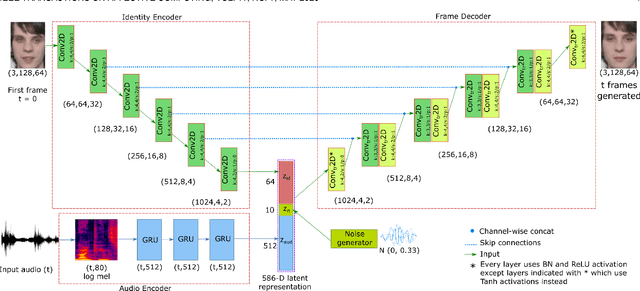
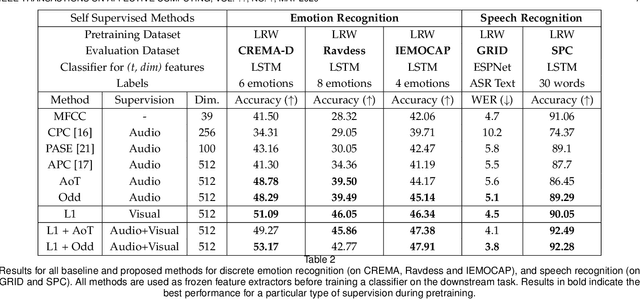
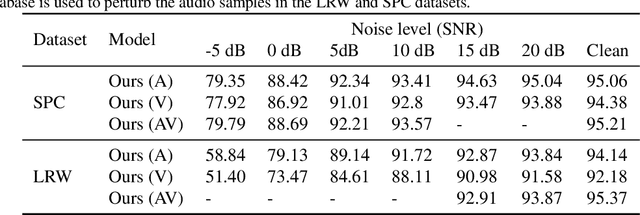
Self-supervised learning has attracted plenty of recent research interest. However, most works are typically unimodal and there has been limited work that studies the interaction between audio and visual modalities for self-supervised learning. This work (1) investigates visual self-supervision via face reconstruction to guide the learning of audio representations; (2) proposes two audio-only self-supervision approaches for speech representation learning; (3) shows that a multi-task combination of the proposed visual and audio self-supervision is beneficial for learning richer features that are more robust in noisy conditions; (4) shows that self-supervised pretraining leads to a superior weight initialization, which is especially useful to prevent overfitting and lead to faster model convergence on smaller sized datasets. We evaluate our audio representations for emotion and speech recognition, achieving state of the art performance for both problems. Our results demonstrate the potential of visual self-supervision for audio feature learning and suggest that joint visual and audio self-supervision leads to more informative speech representations.
Visually Guided Self Supervised Learning of Speech Representations
Feb 20, 2020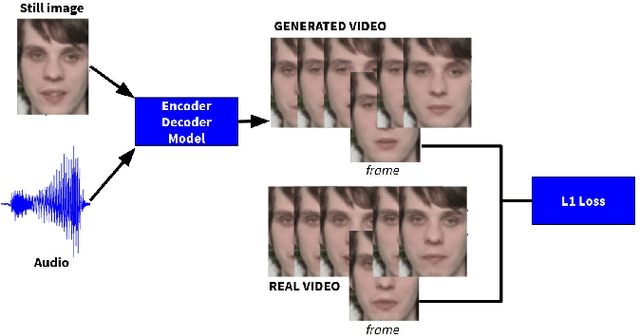
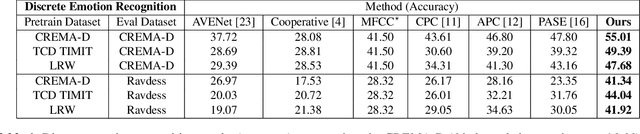
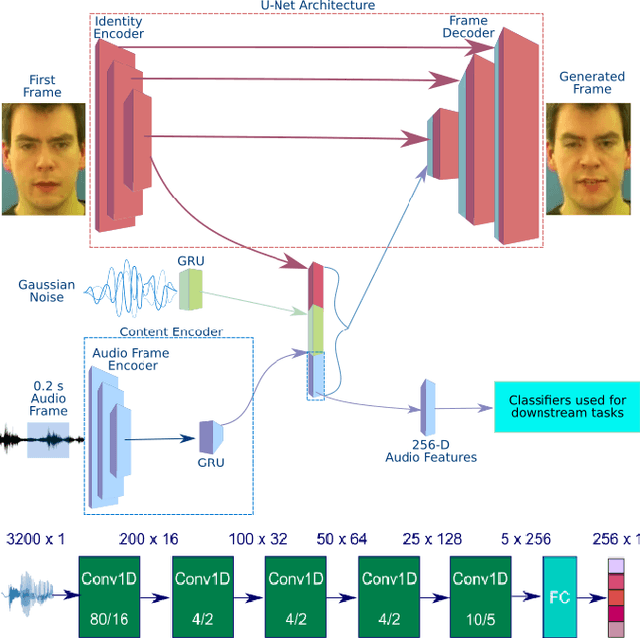
Self supervised representation learning has recently attracted a lot of research interest for both the audio and visual modalities. However, most works typically focus on a particular modality or feature alone and there has been very limited work that studies the interaction between the two modalities for learning self supervised representations. We propose a framework for learning audio representations guided by the visual modality in the context of audiovisual speech. We employ a generative audio-to-video training scheme in which we animate a still image corresponding to a given audio clip and optimize the generated video to be as close as possible to the real video of the speech segment. Through this process, the audio encoder network learns useful speech representations that we evaluate on emotion recognition and speech recognition. We achieve state of the art results for emotion recognition and competitive results for speech recognition. This demonstrates the potential of visual supervision for learning audio representations as a novel way for self-supervised learning which has not been explored in the past. The proposed unsupervised audio features can leverage a virtually unlimited amount of training data of unlabelled audiovisual speech and have a large number of potentially promising applications.
Recognition of Advertisement Emotions with Application to Computational Advertising
Apr 03, 2019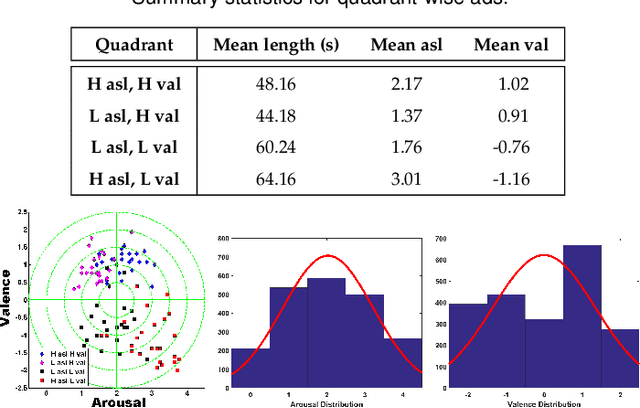
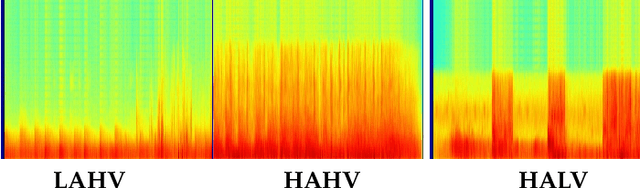

Advertisements (ads) often contain strong affective content to capture viewer attention and convey an effective message to the audience. However, most computational affect recognition (AR) approaches examine ads via the text modality, and only limited work has been devoted to decoding ad emotions from audiovisual or user cues. This work (1) compiles an affective ad dataset capable of evoking coherent emotions across users; (2) explores the efficacy of content-centric convolutional neural network (CNN) features for AR vis-\~a-vis handcrafted audio-visual descriptors; (3) examines user-centric ad AR from Electroencephalogram (EEG) responses acquired during ad-viewing, and (4) demonstrates how better affect predictions facilitate effective computational advertising as determined by a study involving 18 users. Experiments reveal that (a) CNN features outperform audiovisual descriptors for content-centric AR; (b) EEG features are able to encode ad-induced emotions better than content-based features; (c) Multi-task learning performs best among a slew of classification algorithms to achieve optimal AR, and (d) Pursuant to (b), EEG features also enable optimized ad insertion onto streamed video, as compared to content-based or manual insertion techniques in terms of ad memorability and overall user experience.
Looking Beyond a Clever Narrative: Visual Context and Attention are Primary Drivers of Affect in Video Advertisements
Aug 14, 2018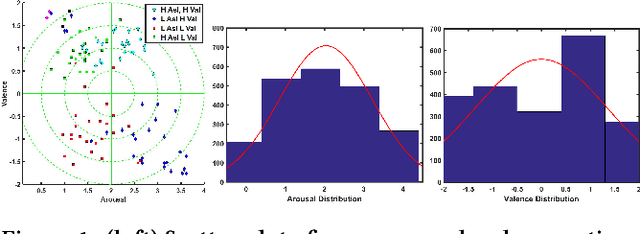
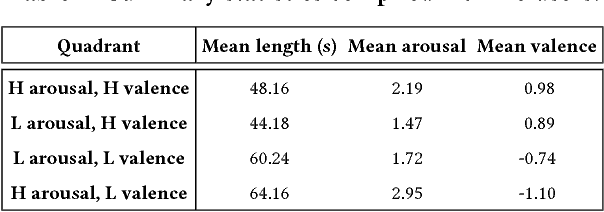

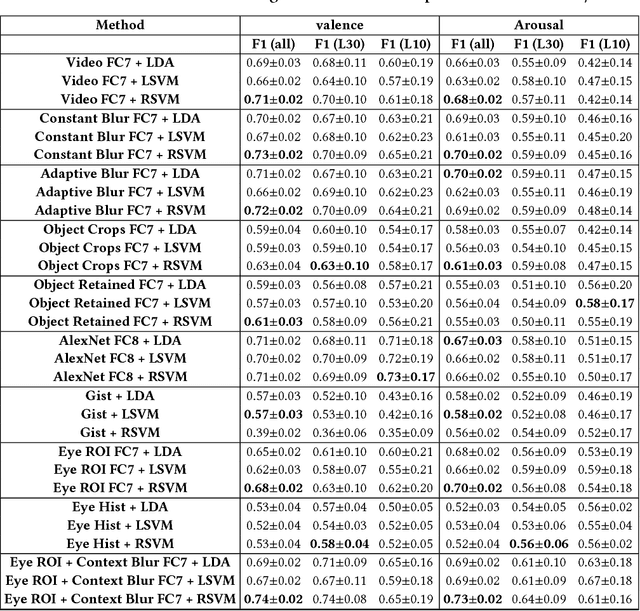
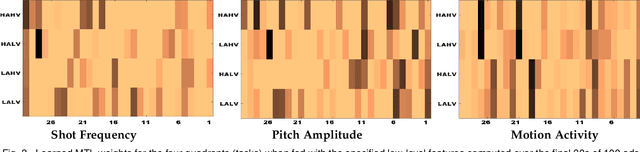
Emotion evoked by an advertisement plays a key role in influencing brand recall and eventual consumer choices. Automatic ad affect recognition has several useful applications. However, the use of content-based feature representations does not give insights into how affect is modulated by aspects such as the ad scene setting, salient object attributes and their interactions. Neither do such approaches inform us on how humans prioritize visual information for ad understanding. Our work addresses these lacunae by decomposing video content into detected objects, coarse scene structure, object statistics and actively attended objects identified via eye-gaze. We measure the importance of each of these information channels by systematically incorporating related information into ad affect prediction models. Contrary to the popular notion that ad affect hinges on the narrative and the clever use of linguistic and social cues, we find that actively attended objects and the coarse scene structure better encode affective information as compared to individual scene objects or conspicuous background elements.