 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMOVE: A Reference-free Metric for Object Erasure
Sep 01, 2024



We introduce $\texttt{ReMOVE}$, a novel reference-free metric for assessing object erasure efficacy in diffusion-based image editing models post-generation. Unlike existing measures such as LPIPS and CLIPScore, $\texttt{ReMOVE}$ addresses the challenge of evaluating inpainting without a reference image, common in practical scenarios. It effectively distinguishes between object removal and replacement. This is a key issue in diffusion models due to stochastic nature of image generation. Traditional metrics fail to align with the intuitive definition of inpainting, which aims for (1) seamless object removal within masked regions (2) while preserving the background continuity. $\texttt{ReMOVE}$ not only correlates with state-of-the-art metrics and aligns with human perception but also captures the nuanced aspects of the inpainting process, providing a finer-grained evaluation of the generated outputs.
LoMOE: Localized Multi-Object Editing via Multi-Diffusion
Mar 01, 2024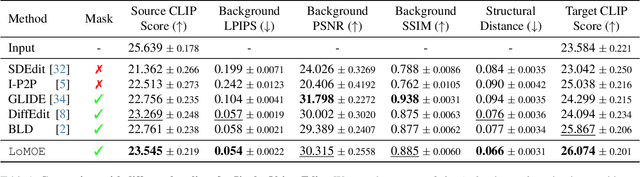
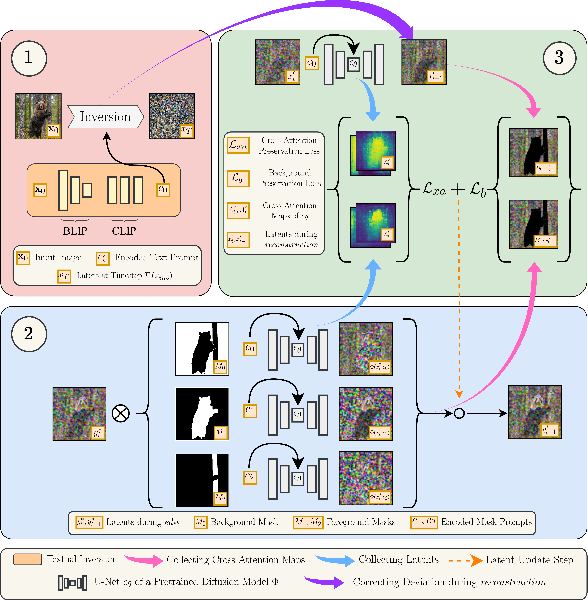
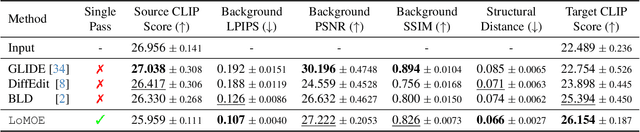

Recent developments in the field of diffusion models have demonstrated an exceptional capacity to generate high-quality prompt-conditioned image edits. Nevertheless, previous approaches have primarily relied on textual prompts for image editing, which tend to be less effective when making precise edits to specific objects or fine-grained regions within a scene containing single/multiple objects. We introduce a novel framework for zero-shot localized multi-object editing through a multi-diffusion process to overcome this challenge. This framework empowers users to perform various operations on objects within an image, such as adding, replacing, or editing $\textbf{many}$ objects in a complex scene $\textbf{in one pass}$. Our approach leverages foreground masks and corresponding simple text prompts that exert localized influences on the target regions resulting in high-fidelity image editing. A combination of cross-attention and background preservation losses within the latent space ensures that the characteristics of the object being edited are preserved while simultaneously achieving a high-quality, seamless reconstruction of the background with fewer artifacts compared to the current methods. We also curate and release a dataset dedicated to multi-object editing, named $\texttt{LoMOE}$-Bench. Our experiments against existing state-of-the-art methods demonstrate the improved effectiveness of our approach in terms of both image editing quality and inference speed.
pSTarC: Pseudo Source Guided Target Clustering for Fully Test-Time Adaptation
Sep 02, 2023



Test Time Adaptation (TTA) is a pivotal concept in machine learning, enabling models to perform well in real-world scenarios, where test data distribution differs from training. In this work, we propose a novel approach called pseudo Source guided Target Clustering (pSTarC) addressing the relatively unexplored area of TTA under real-world domain shifts. This method draws inspiration from target clustering techniques and exploits the source classifier for generating pseudo-source samples. The test samples are strategically aligned with these pseudo-source samples, facilitating their clustering and thereby enhancing TTA performance. pSTarC operates solely within the fully test-time adaptation protocol, removing the need for actual source data. Experimental validation on a variety of domain shift datasets, namely VisDA, Office-Home, DomainNet-126, CIFAR-100C verifies pSTarC's effectiveness. This method exhibits significant improvements in prediction accuracy along with efficient computational requirements. Furthermore, we also demonstrate the universality of the pSTarC framework by showing its effectiveness for the continuous TTA framework.
SATA: Source Anchoring and Target Alignment Network for Continual Test Time Adaptation
Apr 20, 2023



Adapting a trained model to perform satisfactorily on continually changing testing domains/environments is an important and challenging task. In this work, we propose a novel framework, SATA, which aims to satisfy the following characteristics required for online adaptation: 1) can work seamlessly with different (preferably small) batch sizes to reduce latency; 2) should continue to work well for the source domain; 3) should have minimal tunable hyper-parameters and storage requirements. Given a pre-trained network trained on source domain data, the proposed SATA framework modifies the batch-norm affine parameters using source anchoring based self-distillation. This ensures that the model incorporates the knowledge of the newly encountered domains, without catastrophically forgetting about the previously seen ones. We also propose a source-prototype driven contrastive alignment to ensure natural grouping of the target samples, while maintaining the already learnt semantic information. Extensive evaluation on three benchmark datasets under challenging settings justify the effectiveness of SATA for real-world applications.