 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Student: Learning Compact and Sparser Networks in Knowledge Distillation Framework
Oct 26, 2019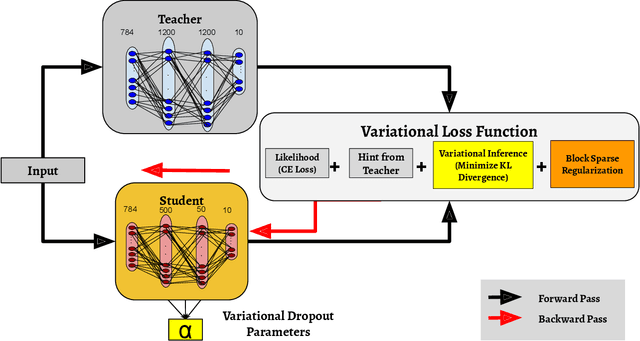
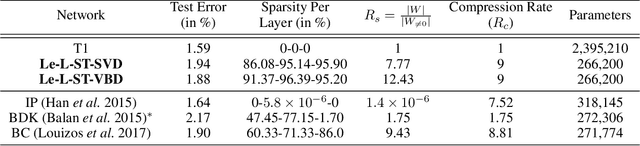
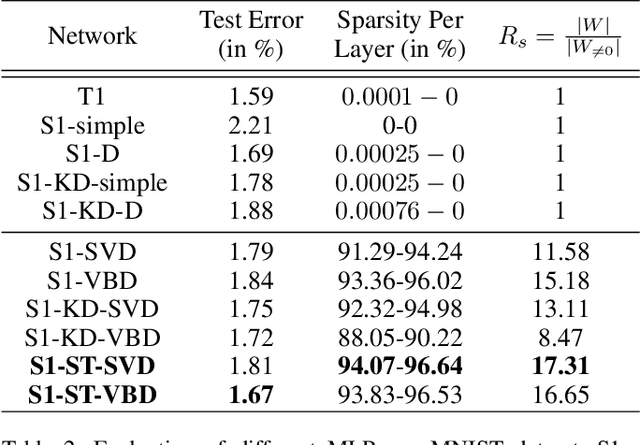
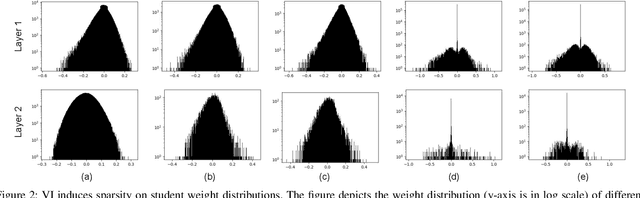
The holy grail in deep neural network research is porting the memory- and computation-intensive network models on embedded platforms with a minimal compromise in model accuracy. To this end, we propose a novel approach, termed as Variational Student, where we reap the benefits of compressibility of the knowledge distillation (KD) framework, and sparsity inducing abilities of variational inference (VI) techniques. Essentially, we build a sparse student network, whose sparsity is induced by the variational parameters found via optimizing a loss function based on VI, leveraging the knowledge learnt by an accurate but complex pre-trained teacher network. Further, for sparsity enhancement, we also employ a Block Sparse Regularizer on a concatenated tensor of teacher and student network weights. We demonstrate that the marriage of KD and the VI techniques inherits compression properties from the KD framework, and enhances levels of sparsity from the VI approach, with minimal compromise in the model accuracy. We benchmark our results on LeNet MLP and VGGNet (CNN) and illustrate a memory footprint reduction of 64x and 213x on these MLP and CNN variants, respectively, without a need to retrain the teacher network. Furthermore, in the low data regime, we observed that our method outperforms state-of-the-art Bayesian techniques in terms of accuracy.