 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stitch in Time Saves Nine: A Train-Time Regularizing Loss for Improved Neural Network Calibration
Mar 25, 2022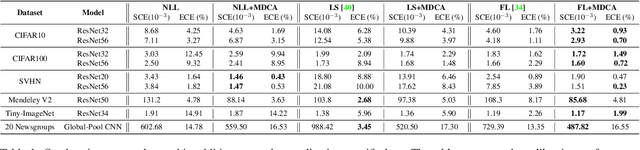
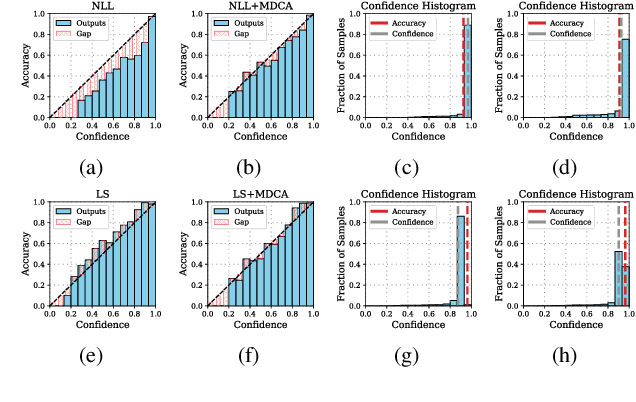
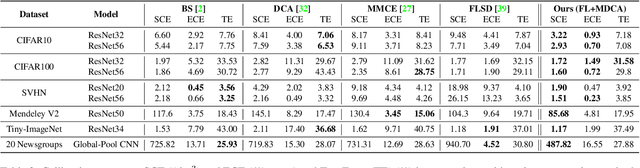
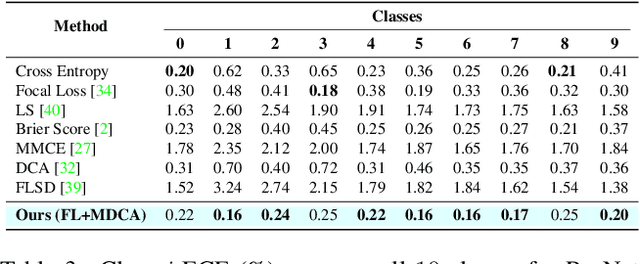
Deep Neural Networks ( DNN s) are known to make overconfident mistakes, which makes their use problematic in safety-critical applications. State-of-the-art ( SOTA ) calibration techniques improve on the confidence of predicted labels alone and leave the confidence of non-max classes (e.g. top-2, top-5) uncalibrated. Such calibration is not suitable for label refinement using post-processing. Further, most SOTA techniques learn a few hyper-parameters post-hoc, leaving out the scope for image, or pixel specific calibration. This makes them unsuitable for calibration under domain shift, or for dense prediction tasks like semantic segmentation. In this paper, we argue for intervening at the train time itself, so as to directly produce calibrated DNN models. We propose a novel auxiliary loss function: Multi-class Difference in Confidence and Accuracy ( MDCA ), to achieve the same MDCA can be used in conjunction with other application/task-specific loss functions. We show that training with MDCA leads to better-calibrated models in terms of Expected Calibration Error ( ECE ), and Static Calibration Error ( SCE ) on image classification, and segmentation tasks. We report ECE ( SCE ) score of 0.72 (1.60) on the CIFAR 100 dataset, in comparison to 1.90 (1.71) by the SOTA. Under domain shift, a ResNet-18 model trained on PACS dataset using MDCA gives an average ECE ( SCE ) score of 19.7 (9.7) across all domains, compared to 24.2 (11.8) by the SOTA. For the segmentation task, we report a 2X reduction in calibration error on PASCAL - VOC dataset in comparison to Focal Loss. Finally, MDCA training improves calibration even on imbalanced data, and for natural language classification tasks. We have released the code here: code is available at https://github.com/mdca-loss