 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Collective Welfare in Multi-Agent Reinforcement Learning via Suggestion Sharing
Dec 16, 2024In human society, the conflict between self-interest and collective well-being often obstructs efforts to achieve shared welfare. Related concepts like the Tragedy of the Commons and Social Dilemmas frequently manifest in our daily lives. As artificial agents increasingly serve as autonomous proxies for humans, we propose using multi-agent reinforcement learning (MARL) to address this issue - learning policies to maximise collective returns even when individual agents' interests conflict with the collective one. Traditional MARL solutions involve sharing rewards, values, and policies or designing intrinsic rewards to encourage agents to learn collectively optimal policies. We introduce a novel MARL approach based on Suggestion Sharing (SS), where agents exchange only action suggestions. This method enables effective cooperation without the need to design intrinsic rewards, achieving strong performance while revealing less private information compared to sharing rewards, values, or policies. Our theoretical analysis establishes a bound on the discrepancy between collective and individual objectives, demonstrating how sharing suggestions can align agents' behaviours with the collective objective. Experimental results demonstrate that SS performs competitively with baselines that rely on value or policy sharing or intrinsic rewards.
Optimizing Privacy and Utility Tradeoffs for Group Interests Through Harmonization
Apr 07, 2024We propose a novel problem formulation to address the privacy-utility tradeoff, specifically when dealing with two distinct user groups characterized by unique sets of private and utility attributes. Unlike previous studies that primarily focus on scenarios where all users share identical private and utility attributes and often rely on auxiliary datasets or manual annotations, we introduce a collaborative data-sharing mechanism between two user groups through a trusted third party. This third party uses adversarial privacy techniques with our proposed data-sharing mechanism to internally sanitize data for both groups and eliminates the need for manual annotation or auxiliary datasets. Our methodology ensures that private attributes cannot be accurately inferred while enabling highly accurate predictions of utility features. Importantly, even if analysts or adversaries possess auxiliary datasets containing raw data, they are unable to accurately deduce private features. Additionally, our data-sharing mechanism is compatible with various existing adversarially trained privacy techniques. We empirically demonstrate the effectiveness of our approach using synthetic and real-world datasets, showcasing its ability to balance the conflicting goals of privacy and utility.
Initial Exploration of Zero-Shot Privacy Utility Tradeoffs in Tabular Data Using GPT-4
Apr 07, 2024We investigate the application of large language models (LLMs), specifically GPT-4, to scenarios involving the tradeoff between privacy and utility in tabular data. Our approach entails prompting GPT-4 by transforming tabular data points into textual format, followed by the inclusion of precise sanitization instructions in a zero-shot manner. The primary objective is to sanitize the tabular data in such a way that it hinders existing machine learning models from accurately inferring private features while allowing models to accurately infer utility-related attributes. We explore various sanitization instructions. Notably, we discover that this relatively simple approach yields performance comparable to more complex adversarial optimization methods used for managing privacy-utility tradeoffs. Furthermore, while the prompts successfully obscure private features from the detection capabilities of existing machine learning models, we observe that this obscuration alone does not necessarily meet a range of fairness metrics. Nevertheless, our research indicates the potential effectiveness of LLMs in adhering to these fairness metrics, with some of our experimental results aligning with those achieved by well-established adversarial optimization techniques.
Learning to Advise and Learning from Advice in Cooperative Multi-Agent Reinforcement Learning
May 23, 2022



Learning to coordinate is a daunting problem in multi-agent reinforcement learning (MARL). Previous works have explored it from many facets, including cognition between agents, credit assignment, communication, expert demonstration, etc. However, less attention were paid to agents' decision structure and the hierarchy of coordination. In this paper, we explore the spatiotemporal structure of agents' decisions and consider the hierarchy of coordination from the perspective of multilevel emergence dynamics, based on which a novel approach, Learning to Advise and Learning from Advice (LALA), is proposed to improve MARL. Specifically, by distinguishing the hierarchy of coordination, we propose to enhance decision coordination at meso level with an advisor and leverage a policy discriminator to advise agents' learning at micro level. The advisor learns to aggregate decision information in both spatial and temporal domains and generates coordinated decisions by employing a spatiotemporal dual graph convolutional neural network with a task-oriented objective function. Each agent learns from the advice via a policy generative adversarial learning method where a discriminator distinguishes between the policies of the agent and the advisor and boosts both of them based on its judgement. Experimental results indicate the advantage of LALA over baseline approaches in terms of both learning efficiency and coordination capability. Coordination mechanism is investigated from the perspective of multilevel emergence dynamics and mutual information point of view, which provides a novel perspective and method to analyze and improve MARL algorithms.
Uncertainty-Autoencoder-Based Privacy and Utility Preserving Data Type Conscious Transformation
May 04, 2022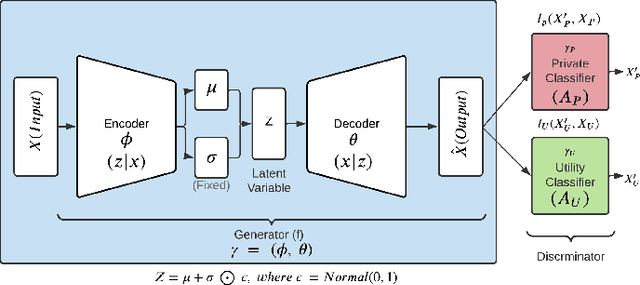
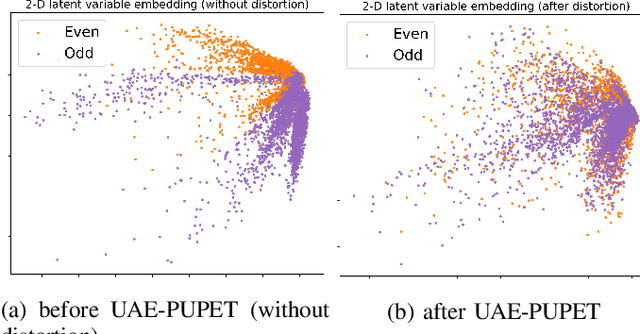
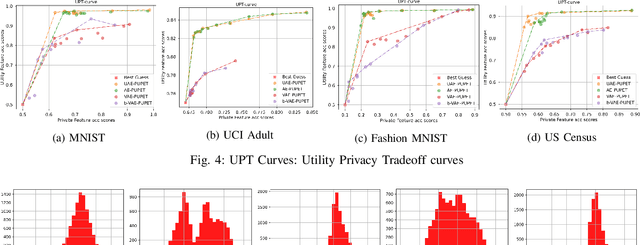

We propose an adversarial learning framework that deals with the privacy-utility tradeoff problem under two types of conditions: data-type ignorant, and data-type aware. Under data-type aware conditions, the privacy mechanism provides a one-hot encoding of categorical features, representing exactly one class, while under data-type ignorant conditions the categorical variables are represented by a collection of scores, one for each class. We use a neural network architecture consisting of a generator and a discriminator, where the generator consists of an encoder-decoder pair, and the discriminator consists of an adversary and a utility provider. Unlike previous research considering this kind of architecture, which leverages autoencoders (AEs) without introducing any randomness, or variational autoencoders (VAEs) based on learning latent representations which are then forced into a Gaussian assumption, our proposed technique introduces randomness and removes the Gaussian assumption restriction on the latent variables, only focusing on the end-to-end stochastic mapping of the input to privatized data. We test our framework on different datasets: MNIST, FashionMNIST, UCI Adult, and US Census Demographic Data, providing a wide range of possible private and utility attributes. We use multiple adversaries simultaneously to test our privacy mechanism -- some trained from the ground truth data and some trained from the perturbed data generated by our privacy mechanism. Through comparative analysis, our results demonstrate better privacy and utility guarantees than the existing works under similar, data-type ignorant conditions, even when the latter are considered under their original restrictive single-adversary model.
Information-Bottleneck-Based Behavior Representation Learning for Multi-agent Reinforcement learning
Sep 29, 2021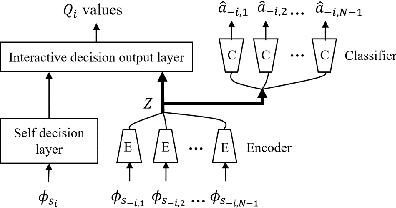
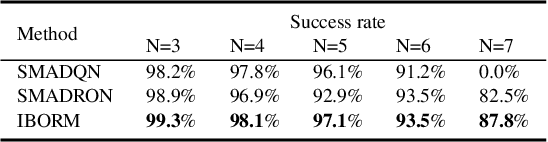
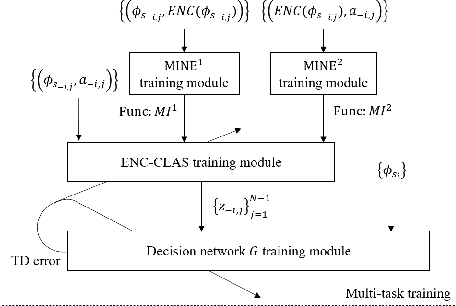
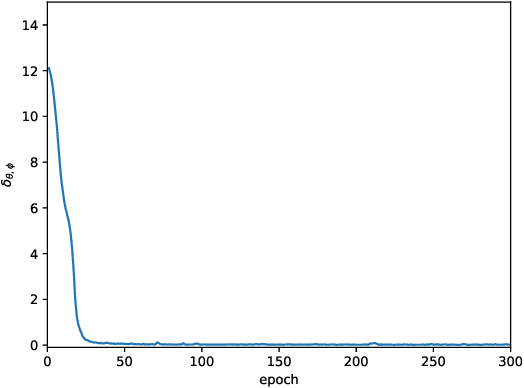
In multi-agent deep reinforcement learning, extracting sufficient and compact information of other agents is critical to attain efficient convergence and scalability of an algorithm. In canonical frameworks, distilling of such information is often done in an implicit and uninterpretable manner, or explicitly with cost functions not able to reflect the relationship between information compression and utility in representation. In this paper, we present Information-Bottleneck-based Other agents' behavior Representation learning for Multi-agent reinforcement learning (IBORM) to explicitly seek low-dimensional mapping encoder through which a compact and informative representation relevant to other agents' behaviors is established. IBORM leverages the information bottleneck principle to compress observation information, while retaining sufficient information relevant to other agents' behaviors used for cooperation decision. Empirical results have demonstrated that IBORM delivers the fastest convergence rate and the best performance of the learned policies, as compared with implicit behavior representation learning and explicit behavior representation learning without explicitly considering information compression and utility.
VAE-KRnet and its applications to variational Bayes
Jun 29, 2020


In this work, we have proposed a generative model for density estimation, called VAE-KRnet, which combines the canonical variational autoencoder (VAE) with our recently developed flow-based generative model, called KRnet. VAE is used as a dimension reduction technique to capture the latent space, and KRnet is used to model the distribution of the latent variables. Using a linear model between the data and the latent variables, we show that VAE-KRnet can be more effective and robust than the canonical VAE. As an application, we apply VAE-KRnet to variational Bayes to approximate the posterior. The variational Bayes approaches are usually based on the minimization of the Kullback-Leibler (KL) divergence between the model and the posterior, which often underestimates the variance if the model capability is not sufficiently strong. However, for high-dimensional distributions, it is very challenging to construct an accurate model since extra assumptions are often needed for efficiency, e.g., the mean-field approach assumes mutual independence between dimensions. When the number of dimensions is relatively small, KRnet can be used to approximate the posterior effectively with respect to the original random variable. For high-dimensional cases, we consider VAE-KRnet to incorporate with the dimension reduction. To alleviate the underestimation of the variance, we include the maximization of the mutual information between the latent random variable and the original one when seeking an approximate distribution with respect to the KL divergence. Numerical experiments have been presented to demonstrate the effectiveness of our model.
Efficient, Effective and Well Justified Estimation of Active Nodes within a Cluster
Jan 26, 2020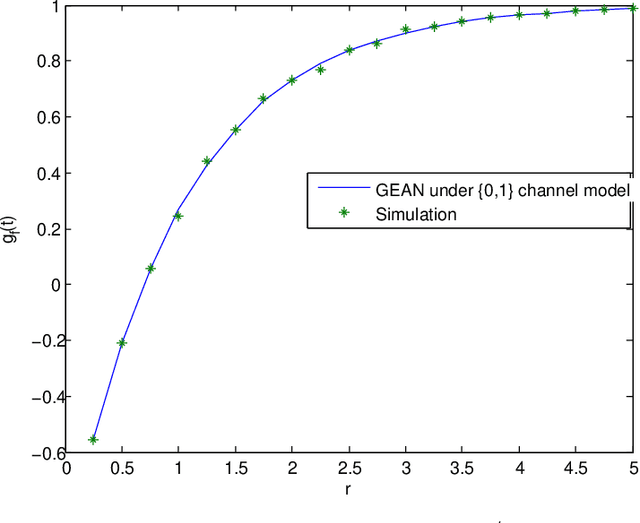
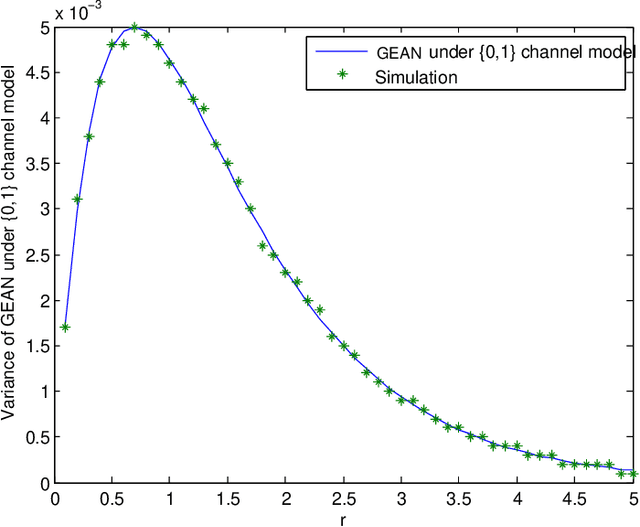
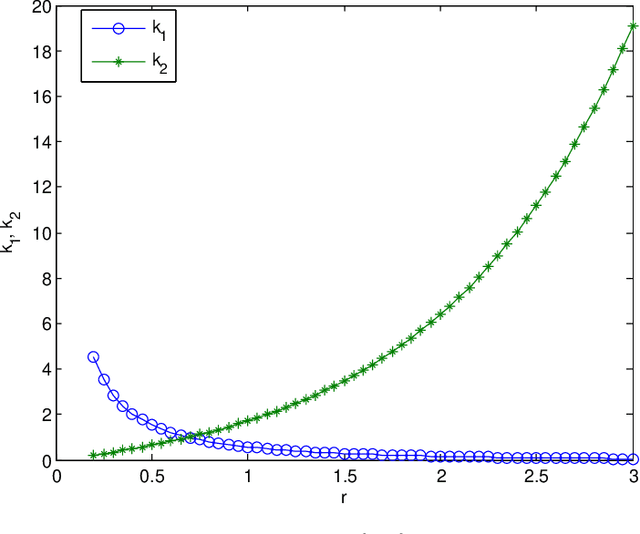
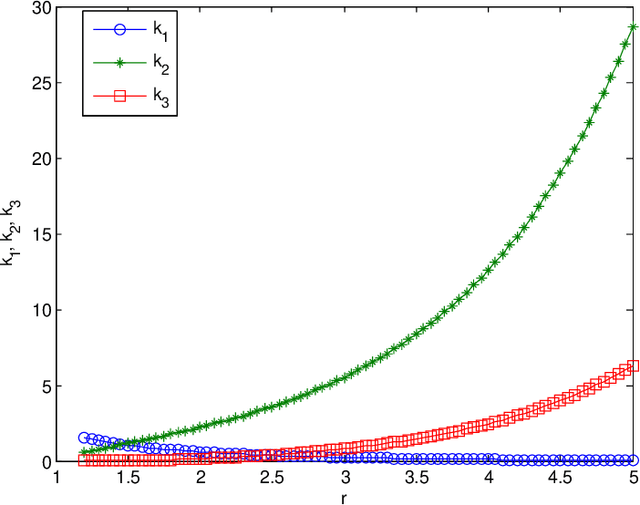
Reliable and efficient estimation of the size of a dynamically changing cluster in an IoT network is critical in its nominal operation. Most previous estimation schemes worked with relatively smaller frame size and large number of rounds. Here we propose a new estimator named \textquotedblleft Gaussian Estimator of Active Nodes,\textquotedblright (GEAN), that works with large enough frame size under which testing statistics is well approximated as a Gaussian variable, thereby requiring less number of frames, and thus less total number of channel slots to attain a desired accuracy in estimation. More specifically, the selection of the frame size is done according to Triangular Array Central Limit Theorem which also enables us to quantify the approximation error. Larger frame size helps the statistical average to converge faster to the ensemble mean of the estimator and the quantification of the approximation error helps to determine the number of rounds to keep up with the accuracy requirements. We present the analysis of our scheme under two different channel models i.e. $ \{0,1 \} $ and $ \{0,1,e \} $, whereas all previous schemes worked only under $ \{0,1 \} $ channel model. The overall performance of GEAN is better than the previously proposed schemes considering the number of slots required for estimation to achieve a given level of estimation accuracy.
Latent Factor Analysis of Gaussian Distributions under Graphical Constraints
Jan 11, 2020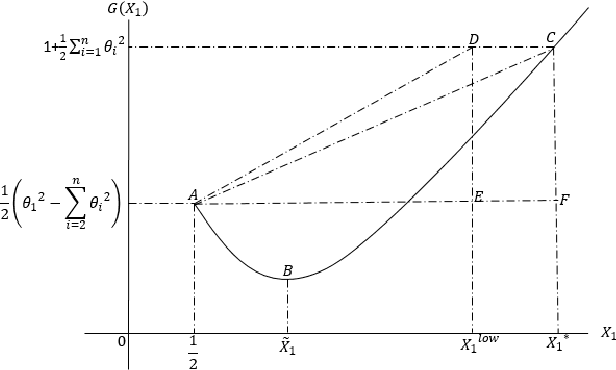
We explore the algebraic structure of the solution space of convex optimization problem Constrained Minimum Trace Factor Analysis (CMTFA), when the population covariance matrix $\Sigma_x$ has an additional latent graphical constraint, namely, a latent star topology. In particular, we have shown that CMTFA can have either a rank $ 1 $ or a rank $ n-1 $ solution and nothing in between. The special case of a rank $ 1 $ solution, corresponds to the case where just one latent variable captures all the dependencies among the observables, giving rise to a star topology. We found explicit conditions for both rank $ 1 $ and rank $n- 1$ solutions for CMTFA solution of $\Sigma_x$. As a basic attempt towards building a more general Gaussian tree, we have found a necessary and a sufficient condition for multiple clusters, each having rank $ 1 $ CMTFA solution, to satisfy a minimum probability to combine together to build a Gaussian tree. To support our analytical findings we have presented some numerical demonstrating the usefulness of the contributions of our work.
Coupling the reduced-order model and the generative model for an importance sampling estimator
Jan 23, 2019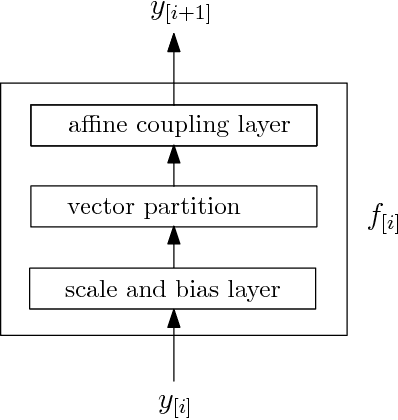
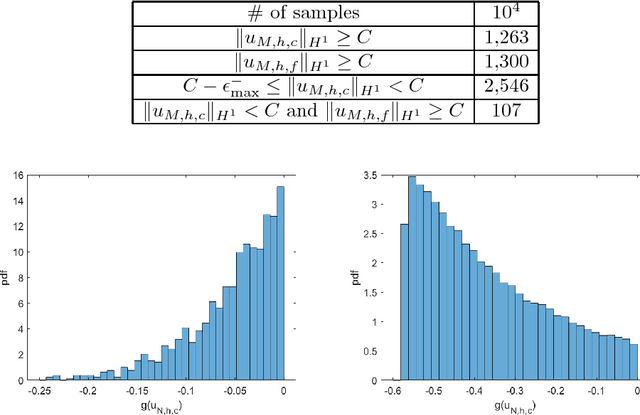


In this work, we develop an importance sampling estimator by coupling the reduced-order model and the generative model in a problem setting of uncertainty quantification. The target is to estimate the probability that the quantity of interest (QoI) in a complex system is beyond a given threshold. To avoid the prohibitive cost of sampling a large scale system, the reduced-order model is usually considered for a trade-off between efficiency and accuracy. However, the Monte Carlo estimator given by the reduced-order model is biased due to the error from dimension reduction. To correct the bias, we still need to sample the fine model. An effective technique to reduce the variance reduction is importance sampling, where we employ the generative model to estimate the distribution of the data from the reduced-order model and use it for the change of measure in the importance sampling estimator. To compensate the approximation errors of the reduced-order model, more data that induce a slightly smaller QoI than the threshold need to be included into the training set. Although the amount of these data can be controlled by a posterior error estimate, redundant data, which may outnumber the effective data, will be kept due to the epistemic uncertainty. To deal with this issue, we introduce a weighted empirical distribution to process the data from the reduced-order model. The generative model is then trained by minimizing the cross entropy between it and the weighted empirical distribution. We also introduce a penalty term into the objective function to deal with the overfitting for more robustness. Numerical results are presented to demonstrate the effectiveness of the proposed methodology.