 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperator learning for solving Fokker-Planck equations with various initial conditions
Jun 08, 2026The Fokker-Planck equation (FPE) plays a pivotal role in describing the time evolution of probability density functions (PDFs) for systems governed by stochastic dynamics. In this work, we propose a conditional normalizing flow-based physics-informed neural network (PINN) framework for efficiently approximating the solution operator of the FPE for a whole range of initial conditions. Leveraging the Chapman-Kolmogorov equation for Markovian stochastic processes, the problem is reformulated into approximating a transition PDF starting at initial time from a Dirac mass centered at an arbitrary point. The PDF of an associated linearized stochastic differential equation (SDE) is employed as the base distribution for the normalizing flow, providing a good approximation of the target PDF, especially for small times, and thereby avoiding the singularity of the map associated with the Dirac delta initial distribution. Furthermore, a time-weighted loss function is introduced to mitigate numerical instabilities arising at small times, achieving a balance between causality and training difficulty as time progresses. A variety of numerical experiments are presented to illustrate the effectiveness and robustness of the proposed method.
Deep Adaptive Dimension Reduction for Bayesian Inference in Inverse Problems
May 28, 2026Solving high-dimensional PDE-governed inverse problems is often challenging due to complex non-Gaussian posterior distributions, expensive forward model evaluations, and misspecified prior information. To address these issues, we propose a deep adaptive dimension-reduction Bayesian inference framework based on the Variational Flow (VF) model. Since standard normalizing flows are restricted by bijective mappings and cannot directly reduce dimensions, VF overcomes this limitation by integrating VAE-based nonlinear dimension reduction with dual normalizing flows for the latent prior and encoder. This design provides a strictly higher evidence lower bound than VAE and allows more flexible approximation of complex posterior distributions. We further introduce an iterative prior updating strategy that gradually moves the prior mean toward high-probability posterior regions, avoiding manual prior tuning. These components form a closed adaptive loop together with an adaptively fine-tuned Fourier Neural Operator (FNO) surrogate: VF generates posterior-concentrated samples to refine the surrogate, while the updated surrogate further improves posterior inference. Numerical experiments on a 100-dimensional Rosenbrock problem and three standard PDE-governed inverse problems show that our method delivers competitive or superior accuracy compared with MCMC, UKI, and SVGD baselines across all tested configurations, with the most pronounced advantages emerging in challenging scenarios such as high-noise observations and high-dimensional parameter spaces.
Amortized Filtering and Smoothing with Conditional Normalizing Flows
Apr 08, 2026Bayesian filtering and smoothing for high-dimensional nonlinear dynamical systems are fundamental yet challenging problems in many areas of science and engineering. In this work, we propose AFSF, a unified amortized framework for filtering and smoothing with conditional normalizing flows. The core idea is to encode each observation history into a fixed-dimensional summary statistic and use this shared representation to learn both a forward flow for the filtering distribution and a backward flow for the backward transition kernel. Specifically, a recurrent encoder maps each observation history to a fixed-dimensional summary statistic whose dimension does not depend on the length of the time series. Conditioned on this shared summary statistic, the forward flow approximates the filtering distribution, while the backward flow approximates the backward transition kernel. The smoothing distribution over an entire trajectory is then recovered by combining the terminal filtering distribution with the learned backward flow through the standard backward recursion. By learning the underlying temporal evolution structure, AFSF also supports extrapolation beyond the training horizon. Moreover, by coupling the two flows through shared summary statistics, AFSF induces an implicit regularization across latent state trajectories and improves trajectory-level smoothing. In addition, we develop a flow-based particle filtering variant that provides an alternative filtering procedure and enables ESS-based diagnostics when explicit model factors are available. Numerical experiments demonstrate that AFSF provides accurate approximations of both filtering distributions and smoothing paths.
Mutual Information Collapse Explains Disentanglement Failure in $β$-VAEs
Feb 09, 2026The $β$-VAE is a foundational framework for unsupervised disentanglement, using $β$ to regulate the trade-off between latent factorization and reconstruction fidelity. Empirically, however, disentanglement performance exhibits a pervasive non-monotonic trend: benchmarks such as MIG and SAP typically peak at intermediate $β$ and collapse as regularization increases. We demonstrate that this collapse is a fundamental information-theoretic failure, where strong Kullback-Leibler pressure promotes marginal independence at the expense of the latent channel's semantic informativeness. By formalizing this mechanism in a linear-Gaussian setting, we prove that for $β> 1$, stationarity-induced dynamics trigger a spectral contraction of the encoder gain, driving latent-factor mutual information to zero. To resolve this, we introduce the $λβ$-VAE, which decouples regularization pressure from informational collapse via an auxiliary $L_2$ reconstruction penalty $λ$. Extensive experiments on dSprites, Shapes3D, and MPI3D-real confirm that $λ> 0$ stabilizes disentanglement and restores latent informativeness over a significantly broader range of $β$, providing a principled theoretical justification for dual-parameter regularization in variational inference backbones.
LVM-GP: Uncertainty-Aware PDE Solver via coupling latent variable model and Gaussian process
Jul 30, 2025We propose a novel probabilistic framework, termed LVM-GP, for uncertainty quantification in solving forward and inverse partial differential equations (PDEs) with noisy data. The core idea is to construct a stochastic mapping from the input to a high-dimensional latent representation, enabling uncertainty-aware prediction of the solution. Specifically, the architecture consists of a confidence-aware encoder and a probabilistic decoder. The encoder implements a high-dimensional latent variable model based on a Gaussian process (LVM-GP), where the latent representation is constructed by interpolating between a learnable deterministic feature and a Gaussian process prior, with the interpolation strength adaptively controlled by a confidence function learned from data. The decoder defines a conditional Gaussian distribution over the solution field, where the mean is predicted by a neural operator applied to the latent representation, allowing the model to learn flexible function-to-function mapping. Moreover, physical laws are enforced as soft constraints in the loss function to ensure consistency with the underlying PDE structure. Compared to existing approaches such as Bayesian physics-informed neural networks (B-PINNs) and deep ensembles, the proposed framework can efficiently capture functional dependencies via merging a latent Gaussian process and neural operator, resulting in competitive predictive accuracy and robust uncertainty quantification. Numerical experiments demonstrate the effectiveness and reliability of the method.
Integral regularization PINNs for evolution equations
Mar 31, 2025Evolution equations, including both ordinary differential equations (ODEs) and partial differential equations (PDEs), play a pivotal role in modeling dynamic systems. However, achieving accurate long-time integration for these equations remains a significant challenge. While physics-informed neural networks (PINNs) provide a mesh-free framework for solving PDEs, they often suffer from temporal error accumulation, which limits their effectiveness in capturing long-time behaviors. To alleviate this issue, we propose integral regularization PINNs (IR-PINNs), a novel approach that enhances temporal accuracy by incorporating an integral-based residual term into the loss function. This method divides the entire time interval into smaller sub-intervals and enforces constraints over these sub-intervals, thereby improving the resolution and correlation of temporal dynamics. Furthermore, IR-PINNs leverage adaptive sampling to dynamically refine the distribution of collocation points based on the evolving solution, ensuring higher accuracy in regions with sharp gradients or rapid variations. Numerical experiments on benchmark problems demonstrate that IR-PINNs outperform original PINNs and other state-of-the-art methods in capturing long-time behaviors, offering a robust and accurate solution for evolution equations.
Estimating Committor Functions via Deep Adaptive Sampling on Rare Transition Paths
Jan 26, 2025The committor functions are central to investigating rare but important events in molecular simulations. It is known that computing the committor function suffers from the curse of dimensionality. Recently, using neural networks to estimate the committor function has gained attention due to its potential for high-dimensional problems. Training neural networks to approximate the committor function needs to sample transition data from straightforward simulations of rare events, which is very inefficient. The scarcity of transition data makes it challenging to approximate the committor function. To address this problem, we propose an efficient framework to generate data points in the transition state region that helps train neural networks to approximate the committor function. We design a Deep Adaptive Sampling method for TRansition paths (DASTR), where deep generative models are employed to generate samples to capture the information of transitions effectively. In particular, we treat a non-negative function in the integrand of the loss functional as an unnormalized probability density function and approximate it with the deep generative model. The new samples from the deep generative model are located in the transition state region and fewer samples are located in the other region. This distribution provides effective samples for approximating the committor function and significantly improves the accuracy. We demonstrate the effectiveness of the proposed method through both simulations and realistic examples.
A hybrid FEM-PINN method for time-dependent partial differential equations
Sep 04, 2024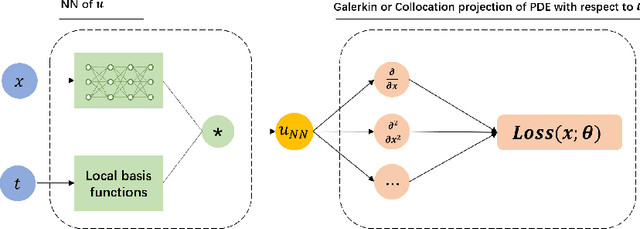

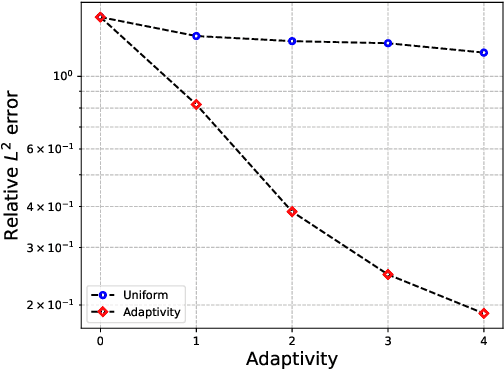
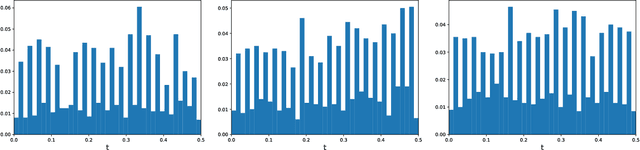
In this work, we present a hybrid numerical method for solving evolution partial differential equations (PDEs) by merging the time finite element method with deep neural networks. In contrast to the conventional deep learning-based formulation where the neural network is defined on a spatiotemporal domain, our methodology utilizes finite element basis functions in the time direction where the space-dependent coefficients are defined as the output of a neural network. We then apply the Galerkin or collocation projection in the time direction to obtain a system of PDEs for the space-dependent coefficients which is approximated in the framework of PINN. The advantages of such a hybrid formulation are twofold: statistical errors are avoided for the integral in the time direction, and the neural network's output can be regarded as a set of reduced spatial basis functions. To further alleviate the difficulties from high dimensionality and low regularity, we have developed an adaptive sampling strategy that refines the training set. More specifically, we use an explicit density model to approximate the distribution induced by the PDE residual and then augment the training set with new time-dependent random samples given by the learned density model. The effectiveness and efficiency of our proposed method have been demonstrated through a series of numerical experiments.
Deep adaptive sampling for surrogate modeling without labeled data
Feb 17, 2024Surrogate modeling is of great practical significance for parametric differential equation systems. In contrast to classical numerical methods, using physics-informed deep learning methods to construct simulators for such systems is a promising direction due to its potential to handle high dimensionality, which requires minimizing a loss over a training set of random samples. However, the random samples introduce statistical errors, which may become the dominant errors for the approximation of low-regularity and high-dimensional problems. In this work, we present a deep adaptive sampling method for surrogate modeling ($\text{DAS}^2$), where we generalize the deep adaptive sampling (DAS) method [62] [Tang, Wan and Yang, 2023] to build surrogate models for low-regularity parametric differential equations. In the parametric setting, the residual loss function can be regarded as an unnormalized probability density function (PDF) of the spatial and parametric variables. This PDF is approximated by a deep generative model, from which new samples are generated and added to the training set. Since the new samples match the residual-induced distribution, the refined training set can further reduce the statistical error in the current approximate solution. We demonstrate the effectiveness of $\text{DAS}^2$ with a series of numerical experiments, including the parametric lid-driven 2D cavity flow problem with a continuous range of Reynolds numbers from 100 to 1000.
Adaptive importance sampling for Deep Ritz
Oct 30, 2023We introduce an adaptive sampling method for the Deep Ritz method aimed at solving partial differential equations (PDEs). Two deep neural networks are used. One network is employed to approximate the solution of PDEs, while the other one is a deep generative model used to generate new collocation points to refine the training set. The adaptive sampling procedure consists of two main steps. The first step is solving the PDEs using the Deep Ritz method by minimizing an associated variational loss discretized by the collocation points in the training set. The second step involves generating a new training set, which is then used in subsequent computations to further improve the accuracy of the current approximate solution. We treat the integrand in the variational loss as an unnormalized probability density function (PDF) and approximate it using a deep generative model called bounded KRnet. The new samples and their associated PDF values are obtained from the bounded KRnet. With these new samples and their associated PDF values, the variational loss can be approximated more accurately by importance sampling. Compared to the original Deep Ritz method, the proposed adaptive method improves accuracy, especially for problems characterized by low regularity and high dimensionality. We demonstrate the effectiveness of our new method through a series of numerical experiments.