 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWGCN: Synergy Weighted Graph Convolutional Network for Multi-Behavior Recommendation
Jan 31, 2026Multi-behavior recommendation paradigms have emerged to capture diverse user activities, forecasting primary conversions (e.g., purchases) by leveraging secondary signals like browsing history. However, current graph-based methods often overlook cross-behavioral synergistic signals and fine-grained intensity of individual actions. Motivated by the need to overcome these shortcomings, we introduce Synergy Weighted Graph Convolutional Network (SWGCN). SWGCN introduces two novel components: a Target Preference Weigher, which adaptively assigns weights to user-item interactions within each behavior, and a Synergy Alignment Task, which guides its training by leveraging an Auxiliary Preference Valuator. This task prioritizes interactions from synergistic signals that more accurately reflect user preferences. The performance of our model is rigorously evaluated through comprehensive tests on three open-source datasets, specifically Taobao, IJCAI, and Beibei. On the Taobao dataset, SWGCN yields relative gains of 112.49% and 156.36% in terms of Hit Ratio (HR) and Normalized Discounted Cumulative Gain (NDCG), respectively. It also yields consistent gains on IJCAI and Beibei, confirming its robustness and generalizability across various datasets. Our implementation is open-sourced and can be accessed via https://github.com/FangdChen/SWGCN.
HE-SNR: Uncovering Latent Logic via Entropy for Guiding Mid-Training on SWE-BENCH
Jan 28, 2026SWE-bench has emerged as the premier benchmark for evaluating Large Language Models on complex software engineering tasks. While these capabilities are fundamentally acquired during the mid-training phase and subsequently elicited during Supervised Fine-Tuning (SFT), there remains a critical deficit in metrics capable of guiding mid-training effectively. Standard metrics such as Perplexity (PPL) are compromised by the "Long-Context Tax" and exhibit weak correlation with downstream SWE performance. In this paper, we bridge this gap by first introducing a rigorous data filtering strategy. Crucially, we propose the Entropy Compression Hypothesis, redefining intelligence not by scalar Top-1 compression, but by the capacity to structure uncertainty into Entropy-Compressed States of low orders ("reasonable hesitation"). Grounded in this fine-grained entropy analysis, we formulate a novel metric, HE-SNR (High-Entropy Signal-to-Noise Ratio). Validated on industrial-scale Mixture-of-Experts (MoE) models across varying context windows (32K/128K), our approach demonstrates superior robustness and predictive power. This work provides both the theoretical foundation and practical tools for optimizing the latent potential of LLMs in complex engineering domains.
Realistic adversarial scenario generation via human-like pedestrian model for autonomous vehicle control parameter optimisation
Jan 05, 2026Autonomous vehicles (AVs) are rapidly advancing and are expected to play a central role in future mobility. Ensuring their safe deployment requires reliable interaction with other road users, not least pedestrians. Direct testing on public roads is costly and unsafe for rare but critical interactions, making simulation a practical alternative. Within simulation-based testing, adversarial scenarios are widely used to probe safety limits, but many prioritise difficulty over realism, producing exaggerated behaviours which may result in AV controllers that are overly conservative. We propose an alternative method, instead using a cognitively inspired pedestrian model featuring both inter-individual and intra-individual variability to generate behaviourally plausible adversarial scenarios. We provide a proof of concept demonstration of this method's potential for AV control optimisation, in closed-loop testing and tuning of an AV controller. Our results show that replacing the rule-based CARLA pedestrian with the human-like model yields more realistic gap acceptance patterns and smoother vehicle decelerations. Unsafe interactions occur only for certain pedestrian individuals and conditions, underscoring the importance of human variability in AV testing. Adversarial scenarios generated by this model can be used to optimise AV control towards safer and more efficient behaviour. Overall, this work illustrates how incorporating human-like road user models into simulation-based adversarial testing can enhance the credibility of AV evaluation and provide a practical basis to behaviourally informed controller optimisation.
Realistic pedestrian-driver interaction modelling using multi-agent RL with human perceptual-motor constraints
Oct 31, 2025Modelling pedestrian-driver interactions is critical for understanding human road user behaviour and developing safe autonomous vehicle systems. Existing approaches often rely on rule-based logic, game-theoretic models, or 'black-box' machine learning methods. However, these models typically lack flexibility or overlook the underlying mechanisms, such as sensory and motor constraints, which shape how pedestrians and drivers perceive and act in interactive scenarios. In this study, we propose a multi-agent reinforcement learning (RL) framework that integrates both visual and motor constraints of pedestrian and driver agents. Using a real-world dataset from an unsignalised pedestrian crossing, we evaluate four model variants, one without constraints, two with either motor or visual constraints, and one with both, across behavioural metrics of interaction realism. Results show that the combined model with both visual and motor constraints performs best. Motor constraints lead to smoother movements that resemble human speed adjustments during crossing interactions. The addition of visual constraints introduces perceptual uncertainty and field-of-view limitations, leading the agents to exhibit more cautious and variable behaviour, such as less abrupt deceleration. In this data-limited setting, our model outperforms a supervised behavioural cloning model, demonstrating that our approach can be effective without large training datasets. Finally, our framework accounts for individual differences by modelling parameters controlling the human constraints as population-level distributions, a perspective that has not been explored in previous work on pedestrian-vehicle interaction modelling. Overall, our work demonstrates that multi-agent RL with human constraints is a promising modelling approach for simulating realistic road user interactions.
Estimating Committor Functions via Deep Adaptive Sampling on Rare Transition Paths
Jan 26, 2025The committor functions are central to investigating rare but important events in molecular simulations. It is known that computing the committor function suffers from the curse of dimensionality. Recently, using neural networks to estimate the committor function has gained attention due to its potential for high-dimensional problems. Training neural networks to approximate the committor function needs to sample transition data from straightforward simulations of rare events, which is very inefficient. The scarcity of transition data makes it challenging to approximate the committor function. To address this problem, we propose an efficient framework to generate data points in the transition state region that helps train neural networks to approximate the committor function. We design a Deep Adaptive Sampling method for TRansition paths (DASTR), where deep generative models are employed to generate samples to capture the information of transitions effectively. In particular, we treat a non-negative function in the integrand of the loss functional as an unnormalized probability density function and approximate it with the deep generative model. The new samples from the deep generative model are located in the transition state region and fewer samples are located in the other region. This distribution provides effective samples for approximating the committor function and significantly improves the accuracy. We demonstrate the effectiveness of the proposed method through both simulations and realistic examples.
Discovering Invariant Neighborhood Patterns for Heterophilic Graphs
Mar 15, 2024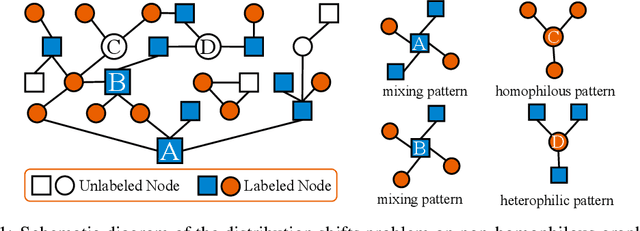
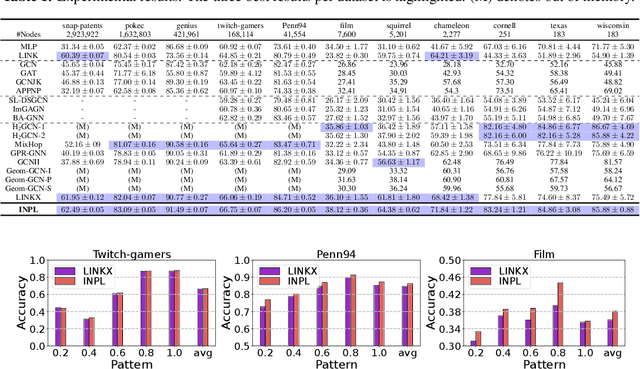
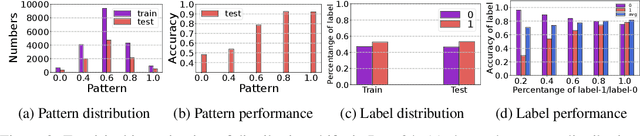
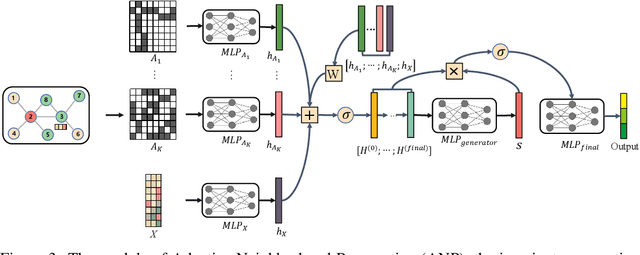
This paper studies the problem of distribution shifts on non-homophilous graphs Mosting existing graph neural network methods rely on the homophilous assumption that nodes from the same class are more likely to be linked. However, such assumptions of homophily do not always hold in real-world graphs, which leads to more complex distribution shifts unaccounted for in previous methods. The distribution shifts of neighborhood patterns are much more diverse on non-homophilous graphs. We propose a novel Invariant Neighborhood Pattern Learning (INPL) to alleviate the distribution shifts problem on non-homophilous graphs. Specifically, we propose the Adaptive Neighborhood Propagation (ANP) module to capture the adaptive neighborhood information, which could alleviate the neighborhood pattern distribution shifts problem on non-homophilous graphs. We propose Invariant Non-Homophilous Graph Learning (INHGL) module to constrain the ANP and learn invariant graph representation on non-homophilous graphs. Extensive experimental results on real-world non-homophilous graphs show that INPL could achieve state-of-the-art performance for learning on large non-homophilous graphs.
Pedestrian crossing decisions can be explained by bounded optimal decision-making under noisy visual perception
Feb 06, 2024This paper presents a model of pedestrian crossing decisions, based on the theory of computational rationality. It is assumed that crossing decisions are boundedly optimal, with bounds on optimality arising from human cognitive limitations. While previous models of pedestrian behaviour have been either 'black-box' machine learning models or mechanistic models with explicit assumptions about cognitive factors, we combine both approaches. Specifically, we model mechanistically noisy human visual perception and assumed rewards in crossing, but we use reinforcement learning to learn bounded optimal behaviour policy. The model reproduces a larger number of known empirical phenomena than previous models, in particular: (1) the effect of the time to arrival of an approaching vehicle on whether the pedestrian accepts the gap, the effect of the vehicle's speed on both (2) gap acceptance and (3) pedestrian timing of crossing in front of yielding vehicles, and (4) the effect on this crossing timing of the stopping distance of the yielding vehicle. Notably, our findings suggest that behaviours previously framed as 'biases' in decision-making, such as speed-dependent gap acceptance, might instead be a product of rational adaptation to the constraints of visual perception. Our approach also permits fitting the parameters of cognitive constraints and rewards per individual, to better account for individual differences. To conclude, by leveraging both RL and mechanistic modelling, our model offers novel insights about pedestrian behaviour, and may provide a useful foundation for more accurate and scalable pedestrian models.
Modeling human road crossing decisions as reward maximization with visual perception limitations
Jan 27, 2023
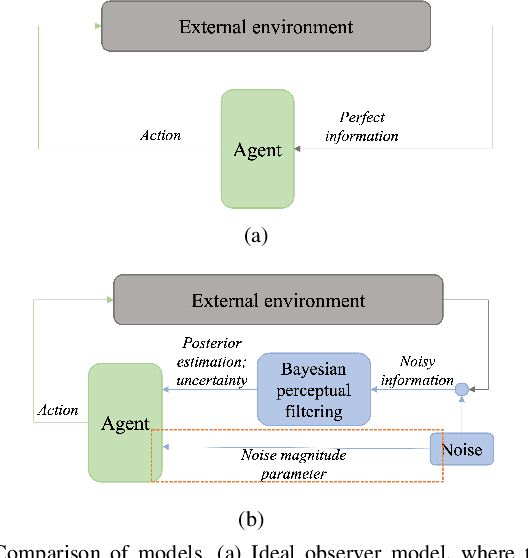
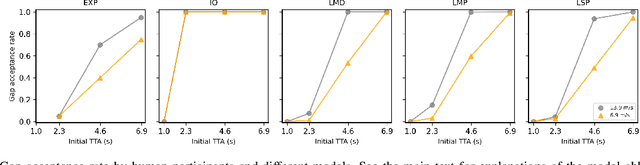
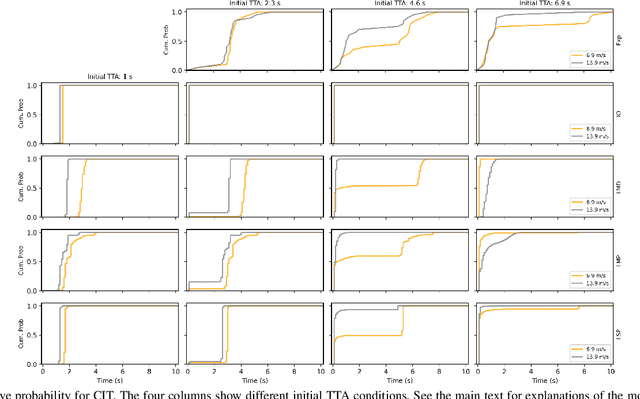
Understanding the interaction between different road users is critical for road safety and automated vehicles (AVs). Existing mathematical models on this topic have been proposed based mostly on either cognitive or machine learning (ML) approaches. However, current cognitive models are incapable of simulating road user trajectories in general scenarios, and ML models lack a focus on the mechanisms generating the behavior and take a high-level perspective which can cause failures to capture important human-like behaviors. Here, we develop a model of human pedestrian crossing decisions based on computational rationality, an approach using deep reinforcement learning (RL) to learn boundedly optimal behavior policies given human constraints, in our case a model of the limited human visual system. We show that the proposed combined cognitive-RL model captures human-like patterns of gap acceptance and crossing initiation time. Interestingly, our model's decisions are sensitive to not only the time gap, but also the speed of the approaching vehicle, something which has been described as a "bias" in human gap acceptance behavior. However, our results suggest that this is instead a rational adaption to human perceptual limitations. Moreover, we demonstrate an approach to accounting for individual differences in computational rationality models, by conditioning the RL policy on the parameters of the human constraints. Our results demonstrate the feasibility of generating more human-like road user behavior by combining RL with cognitive models.
Multivariate Time Series Classification with Hierarchical Variational Graph Pooling
Oct 12, 2020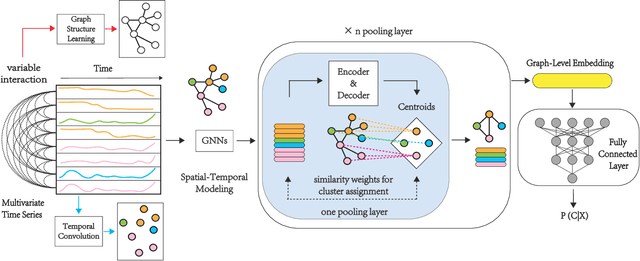
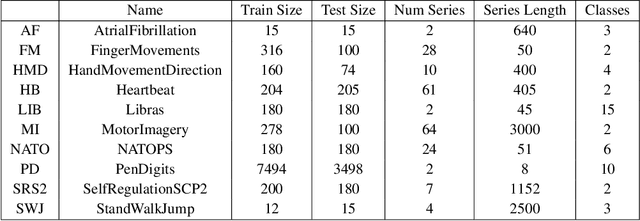
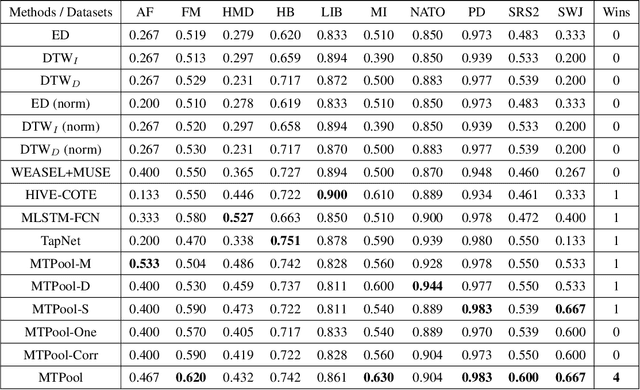
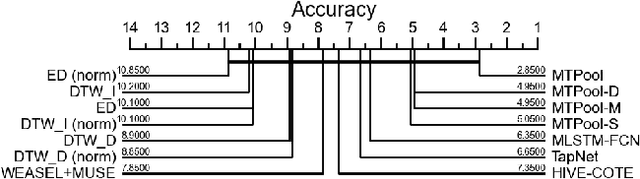
Over the past decade, multivariate time series classification (MTSC) has received great attention with the advance of sensing techniques. Current deep learning methods for MTSC are based on convolutional and recurrent neural network, with the assumption that time series variables have the same effect to each other. Thus they cannot model the pairwise dependencies among variables explicitly. What's more, current spatial-temporal modeling methods based on GNNs are inherently flat and lack the capability of aggregating node information in a hierarchical manner. To address this limitation and attain expressive global representation of MTS, we propose a graph pooling based framework MTPool and view MTSC task as graph classification task. With graph structure learning and temporal convolution, MTS slices are converted to graphs and spatial-temporal features are extracted. Then, we propose a novel graph pooling method, which uses an ``encoder-decoder'' mechanism to generate adaptive centroids for cluster assignments. GNNs and graph pooling layers are used for joint graph representation learning and graph coarsening. With multiple graph pooling layers, the input graphs are hierachically coarsened to one node. Finally, differentiable classifier takes this coarsened one-node graph as input to get the final predicted class. Experiments on 10 benchmark datasets demonstrate MTPool outperforms state-of-the-art methods in MTSC tasks.
Graph Partitioning and Graph Neural Network based Hierarchical Graph Matching for Graph Similarity Computation
May 16, 2020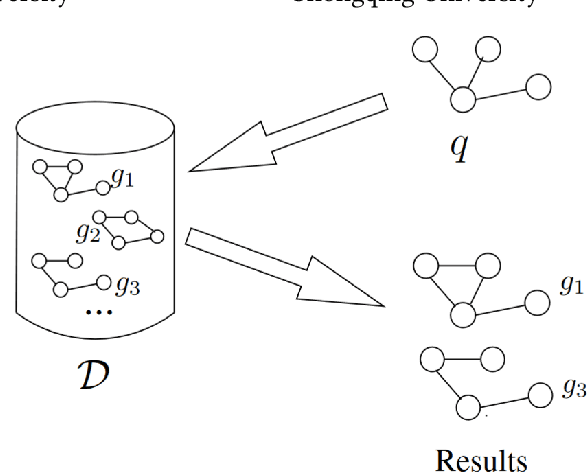
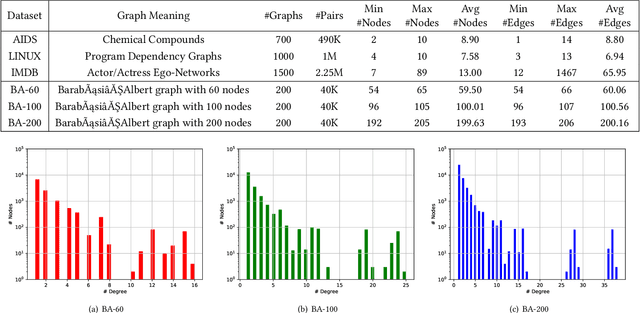
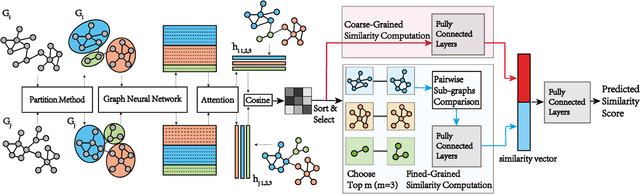
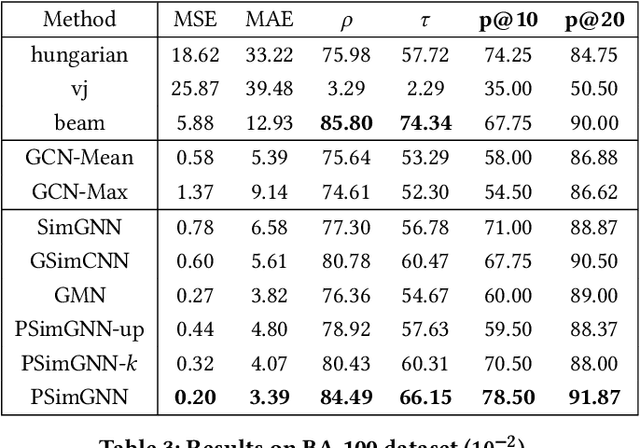
Graph similarity computation aims to predict a similarity score between one pair of graphs so as to facilitate downstream applications, such as finding the chemical compounds that are most similar to a query compound or Fewshot 3D Action Recognition, \textit{etc}. Recently, some graph similarity computation models based on neural networks have been proposed, which are either based on graph-level interaction or node-level comparison. However, when the number of nodes in the graph increases, it will inevitably bring about the problem of reduced representation ability or excessive time complexity. Motivated by this observation, we propose a graph partitioning and graph neural network based model, called PSimGNN, to effectively resolve this issue. Specifically, each of the input graphs is partitioned into a set of subgraphs to directly extract the local structural features firstly. Next, a learnable embedding function is used to map each subgraph into an embedding vector. Then, some of these subgraph pairs are selected for node-level comparison to supplement the subgraph-level embedding with fine-grained information. Finally, coarse-grained interaction information among subgraphs and fine-grained comparison information among nodes in different subgraphs are integrated to predict the final similarity score. Using approximate Graph Edit Distance (GED) as graph similarity metric, experimental results on graph data sets of different graph size demonstrate PSimGNN outperforms state-of-the-art methods in graph similarity computation tasks. The codes will release when this paper is published.