 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Privacy and Utility Tradeoffs for Group Interests Through Harmonization
Apr 07, 2024We propose a novel problem formulation to address the privacy-utility tradeoff, specifically when dealing with two distinct user groups characterized by unique sets of private and utility attributes. Unlike previous studies that primarily focus on scenarios where all users share identical private and utility attributes and often rely on auxiliary datasets or manual annotations, we introduce a collaborative data-sharing mechanism between two user groups through a trusted third party. This third party uses adversarial privacy techniques with our proposed data-sharing mechanism to internally sanitize data for both groups and eliminates the need for manual annotation or auxiliary datasets. Our methodology ensures that private attributes cannot be accurately inferred while enabling highly accurate predictions of utility features. Importantly, even if analysts or adversaries possess auxiliary datasets containing raw data, they are unable to accurately deduce private features. Additionally, our data-sharing mechanism is compatible with various existing adversarially trained privacy techniques. We empirically demonstrate the effectiveness of our approach using synthetic and real-world datasets, showcasing its ability to balance the conflicting goals of privacy and utility.
Initial Exploration of Zero-Shot Privacy Utility Tradeoffs in Tabular Data Using GPT-4
Apr 07, 2024We investigate the application of large language models (LLMs), specifically GPT-4, to scenarios involving the tradeoff between privacy and utility in tabular data. Our approach entails prompting GPT-4 by transforming tabular data points into textual format, followed by the inclusion of precise sanitization instructions in a zero-shot manner. The primary objective is to sanitize the tabular data in such a way that it hinders existing machine learning models from accurately inferring private features while allowing models to accurately infer utility-related attributes. We explore various sanitization instructions. Notably, we discover that this relatively simple approach yields performance comparable to more complex adversarial optimization methods used for managing privacy-utility tradeoffs. Furthermore, while the prompts successfully obscure private features from the detection capabilities of existing machine learning models, we observe that this obscuration alone does not necessarily meet a range of fairness metrics. Nevertheless, our research indicates the potential effectiveness of LLMs in adhering to these fairness metrics, with some of our experimental results aligning with those achieved by well-established adversarial optimization techniques.
A Comprehensive and Reliable Feature Attribution Method: Double-sided Remove and Reconstruct (DoRaR)
Oct 27, 2023



The limited transparency of the inner decision-making mechanism in deep neural networks (DNN) and other machine learning (ML) models has hindered their application in several domains. In order to tackle this issue, feature attribution methods have been developed to identify the crucial features that heavily influence decisions made by these black box models. However, many feature attribution methods have inherent downsides. For example, one category of feature attribution methods suffers from the artifacts problem, which feeds out-of-distribution masked inputs directly through the classifier that was originally trained on natural data points. Another category of feature attribution method finds explanations by using jointly trained feature selectors and predictors. While avoiding the artifacts problem, this new category suffers from the Encoding Prediction in the Explanation (EPITE) problem, in which the predictor's decisions rely not on the features, but on the masks that selects those features. As a result, the credibility of attribution results is undermined by these downsides. In this research, we introduce the Double-sided Remove and Reconstruct (DoRaR) feature attribution method based on several improvement methods that addresses these issues. By conducting thorough testing on MNIST, CIFAR10 and our own synthetic dataset, we demonstrate that the DoRaR feature attribution method can effectively bypass the above issues and can aid in training a feature selector that outperforms other state-of-the-art feature attribution methods. Our code is available at https://github.com/dxq21/DoRaR.
Uncertainty-Autoencoder-Based Privacy and Utility Preserving Data Type Conscious Transformation
May 04, 2022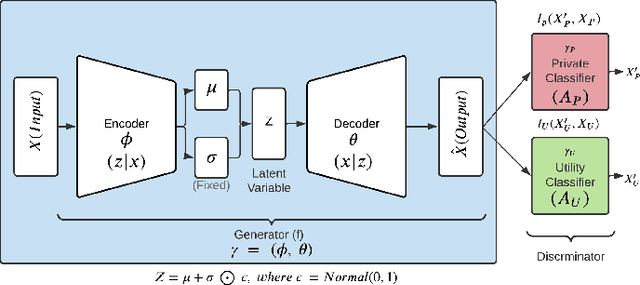
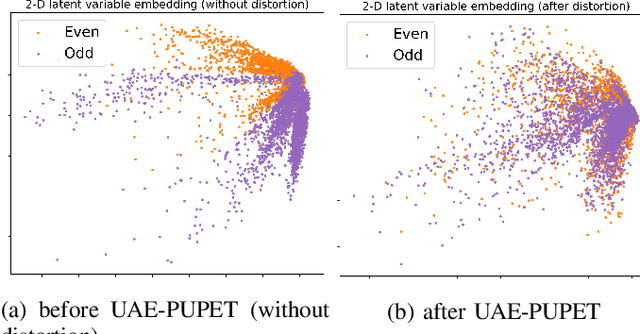
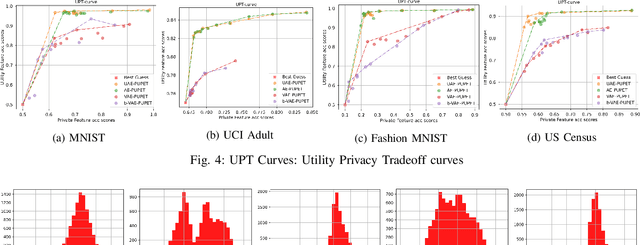

We propose an adversarial learning framework that deals with the privacy-utility tradeoff problem under two types of conditions: data-type ignorant, and data-type aware. Under data-type aware conditions, the privacy mechanism provides a one-hot encoding of categorical features, representing exactly one class, while under data-type ignorant conditions the categorical variables are represented by a collection of scores, one for each class. We use a neural network architecture consisting of a generator and a discriminator, where the generator consists of an encoder-decoder pair, and the discriminator consists of an adversary and a utility provider. Unlike previous research considering this kind of architecture, which leverages autoencoders (AEs) without introducing any randomness, or variational autoencoders (VAEs) based on learning latent representations which are then forced into a Gaussian assumption, our proposed technique introduces randomness and removes the Gaussian assumption restriction on the latent variables, only focusing on the end-to-end stochastic mapping of the input to privatized data. We test our framework on different datasets: MNIST, FashionMNIST, UCI Adult, and US Census Demographic Data, providing a wide range of possible private and utility attributes. We use multiple adversaries simultaneously to test our privacy mechanism -- some trained from the ground truth data and some trained from the perturbed data generated by our privacy mechanism. Through comparative analysis, our results demonstrate better privacy and utility guarantees than the existing works under similar, data-type ignorant conditions, even when the latter are considered under their original restrictive single-adversary model.
An Information Diffusion Approach to Rumor Propagation and Identification on Twitter
Feb 24, 2020

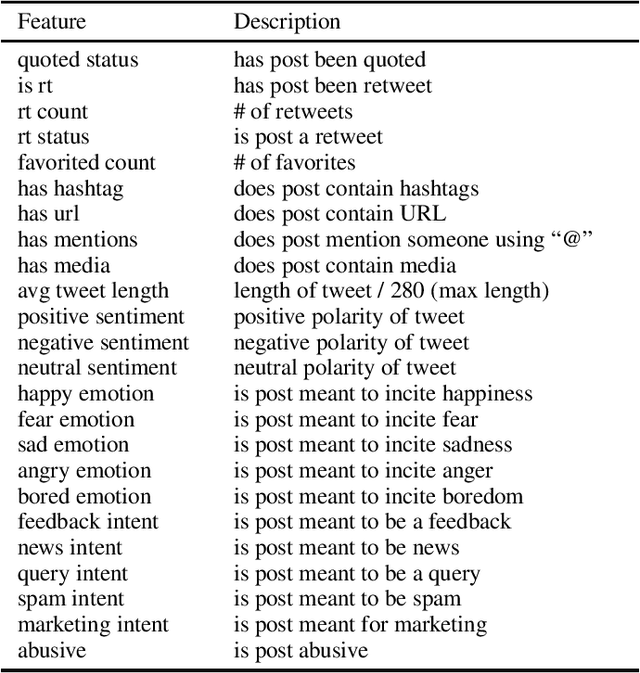
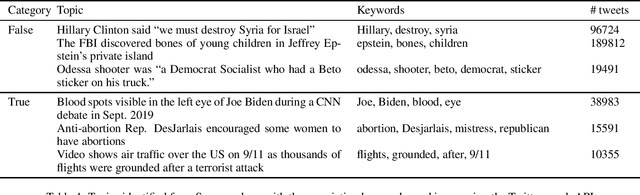
With the increasing use of online social networks as a source of news and information, the propensity for a rumor to disseminate widely and quickly poses a great concern, especially in disaster situations where users do not have enough time to fact-check posts before making the informed decision to react to a post that appears to be credible. In this study, we explore the propagation pattern of rumors on Twitter by exploring the dynamics of microscopic-level misinformation spread, based on the latent message and user interaction attributes. We perform supervised learning for feature selection and prediction. Experimental results with real-world data sets give the models' prediction accuracy at about 90\% for the diffusion of both True and False topics. Our findings confirm that rumor cascades run deeper and that rumor masked as news, and messages that incite fear, will diffuse faster than other messages. We show that the models for True and False message propagation differ significantly, both in the prediction parameters and in the message features that govern the diffusion. Finally, we show that the diffusion pattern is an important metric in identifying the credibility of a tweet.