 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning for Label-Efficient Cancer Image Classification in Oncology
May 08, 2025The application of AI in oncology has been limited by its reliance on large, annotated datasets and the need for retraining models for domain-specific diagnostic tasks. Taking heed of these limitations, we investigated in-context learning as a pragmatic alternative to model retraining by allowing models to adapt to new diagnostic tasks using only a few labeled examples at inference, without the need for retraining. Using four vision-language models (VLMs)-Paligemma, CLIP, ALIGN and GPT-4o, we evaluated the performance across three oncology datasets: MHIST, PatchCamelyon and HAM10000. To the best of our knowledge, this is the first study to compare the performance of multiple VLMs on different oncology classification tasks. Without any parameter updates, all models showed significant gains with few-shot prompting, with GPT-4o reaching an F1 score of 0.81 in binary classification and 0.60 in multi-class classification settings. While these results remain below the ceiling of fully fine-tuned systems, they highlight the potential of ICL to approximate task-specific behavior using only a handful of examples, reflecting how clinicians often reason from prior cases. Notably, open-source models like Paligemma and CLIP demonstrated competitive gains despite their smaller size, suggesting feasibility for deployment in computing constrained clinical environments. Overall, these findings highlight the potential of ICL as a practical solution in oncology, particularly for rare cancers and resource-limited contexts where fine-tuning is infeasible and annotated data is difficult to obtain.
Optimizing Privacy and Utility Tradeoffs for Group Interests Through Harmonization
Apr 07, 2024We propose a novel problem formulation to address the privacy-utility tradeoff, specifically when dealing with two distinct user groups characterized by unique sets of private and utility attributes. Unlike previous studies that primarily focus on scenarios where all users share identical private and utility attributes and often rely on auxiliary datasets or manual annotations, we introduce a collaborative data-sharing mechanism between two user groups through a trusted third party. This third party uses adversarial privacy techniques with our proposed data-sharing mechanism to internally sanitize data for both groups and eliminates the need for manual annotation or auxiliary datasets. Our methodology ensures that private attributes cannot be accurately inferred while enabling highly accurate predictions of utility features. Importantly, even if analysts or adversaries possess auxiliary datasets containing raw data, they are unable to accurately deduce private features. Additionally, our data-sharing mechanism is compatible with various existing adversarially trained privacy techniques. We empirically demonstrate the effectiveness of our approach using synthetic and real-world datasets, showcasing its ability to balance the conflicting goals of privacy and utility.
Initial Exploration of Zero-Shot Privacy Utility Tradeoffs in Tabular Data Using GPT-4
Apr 07, 2024We investigate the application of large language models (LLMs), specifically GPT-4, to scenarios involving the tradeoff between privacy and utility in tabular data. Our approach entails prompting GPT-4 by transforming tabular data points into textual format, followed by the inclusion of precise sanitization instructions in a zero-shot manner. The primary objective is to sanitize the tabular data in such a way that it hinders existing machine learning models from accurately inferring private features while allowing models to accurately infer utility-related attributes. We explore various sanitization instructions. Notably, we discover that this relatively simple approach yields performance comparable to more complex adversarial optimization methods used for managing privacy-utility tradeoffs. Furthermore, while the prompts successfully obscure private features from the detection capabilities of existing machine learning models, we observe that this obscuration alone does not necessarily meet a range of fairness metrics. Nevertheless, our research indicates the potential effectiveness of LLMs in adhering to these fairness metrics, with some of our experimental results aligning with those achieved by well-established adversarial optimization techniques.
Uncertainty-Autoencoder-Based Privacy and Utility Preserving Data Type Conscious Transformation
May 04, 2022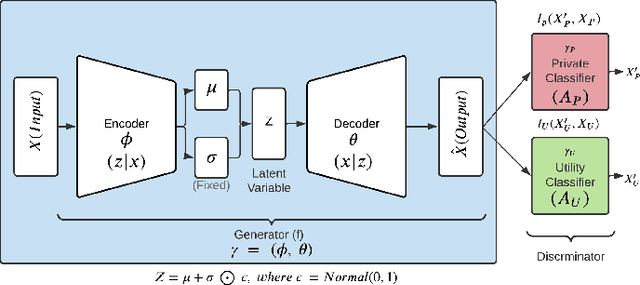
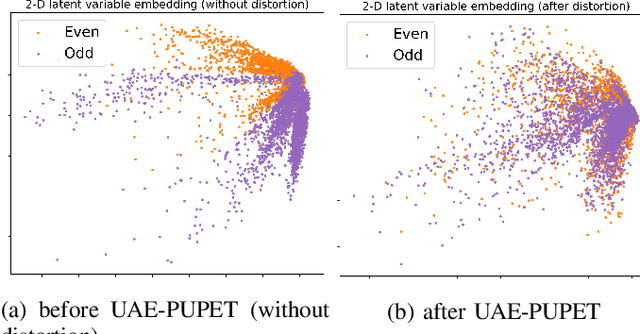
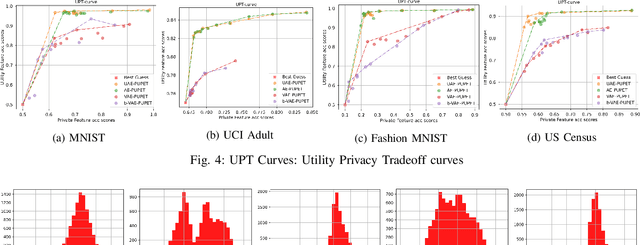

We propose an adversarial learning framework that deals with the privacy-utility tradeoff problem under two types of conditions: data-type ignorant, and data-type aware. Under data-type aware conditions, the privacy mechanism provides a one-hot encoding of categorical features, representing exactly one class, while under data-type ignorant conditions the categorical variables are represented by a collection of scores, one for each class. We use a neural network architecture consisting of a generator and a discriminator, where the generator consists of an encoder-decoder pair, and the discriminator consists of an adversary and a utility provider. Unlike previous research considering this kind of architecture, which leverages autoencoders (AEs) without introducing any randomness, or variational autoencoders (VAEs) based on learning latent representations which are then forced into a Gaussian assumption, our proposed technique introduces randomness and removes the Gaussian assumption restriction on the latent variables, only focusing on the end-to-end stochastic mapping of the input to privatized data. We test our framework on different datasets: MNIST, FashionMNIST, UCI Adult, and US Census Demographic Data, providing a wide range of possible private and utility attributes. We use multiple adversaries simultaneously to test our privacy mechanism -- some trained from the ground truth data and some trained from the perturbed data generated by our privacy mechanism. Through comparative analysis, our results demonstrate better privacy and utility guarantees than the existing works under similar, data-type ignorant conditions, even when the latter are considered under their original restrictive single-adversary model.
Masked Face Recognition using ResNet-50
Apr 19, 2021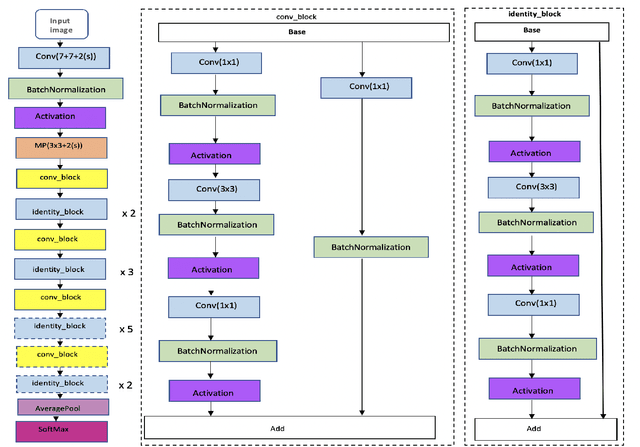
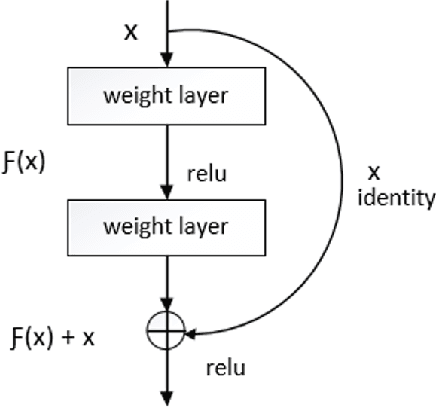

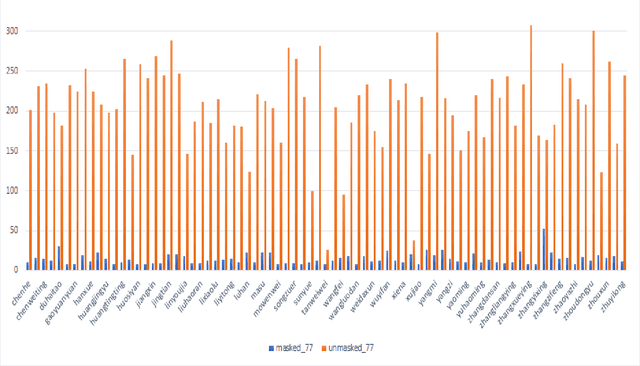
Over the last twenty years, there have seen several outbreaks of different coronavirus diseases across the world. These outbreaks often led to respiratory tract diseases and have proved to be fatal sometimes. Currently, we are facing an elusive health crisis with the emergence of COVID-19 disease of the coronavirus family. One of the modes of transmission of COVID- 19 is airborne transmission. This transmission occurs as humans breathe in the droplets released by an infected person through breathing, speaking, singing, coughing, or sneezing. Hence, public health officials have mandated the use of face masks which can reduce disease transmission by 65%. For face recognition programs, commonly used for security verification purposes, the use of face mask presents an arduous challenge since these programs were typically trained with human faces devoid of masks but now due to the onset of Covid-19 pandemic, they are forced to identify faces with masks. Hence, this paper investigates the same problem by developing a deep learning based model capable of accurately identifying people with face-masks. In this paper, the authors train a ResNet-50 based architecture that performs well at recognizing masked faces. The outcome of this study could be seamlessly integrated into existing face recognition programs that are designed to detect faces for security verification purposes.