 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrafficSimAgent: A Hierarchical Agent Framework for Autonomous Traffic Simulation with MCP Control
Dec 24, 2025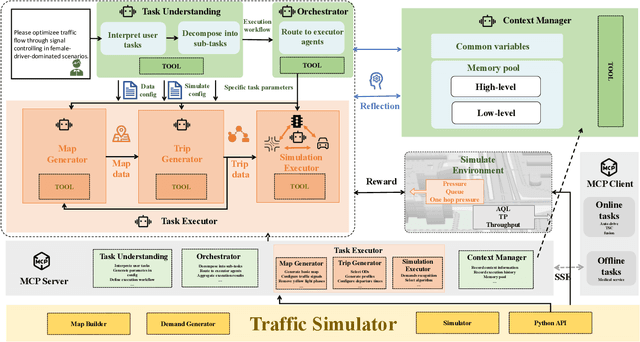

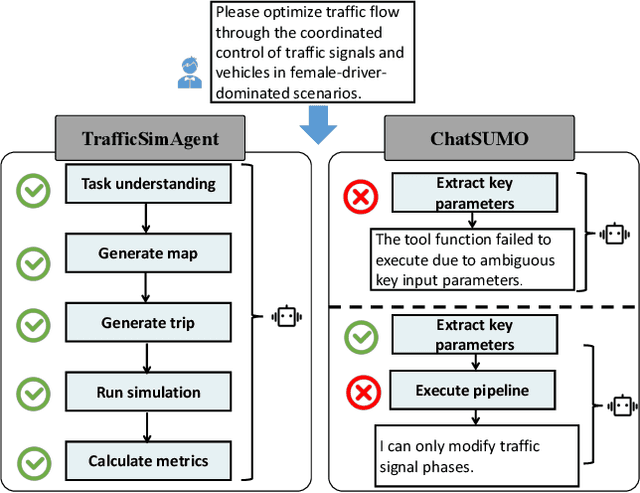
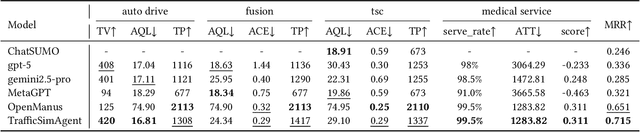
Traffic simulation is important for transportation optimization and policy making. While existing simulators such as SUMO and MATSim offer fully-featured platforms and utilities, users without too much knowledge about these platforms often face significant challenges when conducting experiments from scratch and applying them to their daily work. To solve this challenge, we propose TrafficSimAgent, an LLM-based agent framework that serves as an expert in experiment design and decision optimization for general-purpose traffic simulation tasks. The framework facilitates execution through cross-level collaboration among expert agents: high-level expert agents comprehend natural language instructions with high flexibility, plan the overall experiment workflow, and invoke corresponding MCP-compatible tools on demand; meanwhile, low-level expert agents select optimal action plans for fundamental elements based on real-time traffic conditions. Extensive experiments across multiple scenarios show that TrafficSimAgent effectively executes simulations under various conditions and consistently produces reasonable outcomes even when user instructions are ambiguous. Besides, the carefully designed expert-level autonomous decision-driven optimization in TrafficSimAgent yields superior performance when compared with other systems and SOTA LLM based methods.
CAMS: A CityGPT-Powered Agentic Framework for Urban Human Mobility Simulation
Jun 16, 2025Human mobility simulation plays a crucial role in various real-world applications. Recently, to address the limitations of traditional data-driven approaches, researchers have explored leveraging the commonsense knowledge and reasoning capabilities of large language models (LLMs) to accelerate human mobility simulation. However, these methods suffer from several critical shortcomings, including inadequate modeling of urban spaces and poor integration with both individual mobility patterns and collective mobility distributions. To address these challenges, we propose \textbf{C}ityGPT-Powered \textbf{A}gentic framework for \textbf{M}obility \textbf{S}imulation (\textbf{CAMS}), an agentic framework that leverages the language based urban foundation model to simulate human mobility in urban space. \textbf{CAMS} comprises three core modules, including MobExtractor to extract template mobility patterns and synthesize new ones based on user profiles, GeoGenerator to generate anchor points considering collective knowledge and generate candidate urban geospatial knowledge using an enhanced version of CityGPT, TrajEnhancer to retrieve spatial knowledge based on mobility patterns and generate trajectories with real trajectory preference alignment via DPO. Experiments on real-world datasets show that \textbf{CAMS} achieves superior performance without relying on externally provided geospatial information. Moreover, by holistically modeling both individual mobility patterns and collective mobility constraints, \textbf{CAMS} generates more realistic and plausible trajectories. In general, \textbf{CAMS} establishes a new paradigm that integrates the agentic framework with urban-knowledgeable LLMs for human mobility simulation.
Multiple Weaks Win Single Strong: Large Language Models Ensemble Weak Reinforcement Learning Agents into a Supreme One
May 21, 2025Model ensemble is a useful approach in reinforcement learning (RL) for training effective agents. Despite wide success of RL, training effective agents remains difficult due to the multitude of factors requiring careful tuning, such as algorithm selection, hyperparameter settings, and even random seed choices, all of which can significantly influence an agent's performance. Model ensemble helps overcome this challenge by combining multiple weak agents into a single, more powerful one, enhancing overall performance. However, existing ensemble methods, such as majority voting and Boltzmann addition, are designed as fixed strategies and lack a semantic understanding of specific tasks, limiting their adaptability and effectiveness. To address this, we propose LLM-Ens, a novel approach that enhances RL model ensemble with task-specific semantic understandings driven by large language models (LLMs). Given a task, we first design an LLM to categorize states in this task into distinct 'situations', incorporating high-level descriptions of the task conditions. Then, we statistically analyze the strengths and weaknesses of each individual agent to be used in the ensemble in each situation. During the inference time, LLM-Ens dynamically identifies the changing task situation and switches to the agent that performs best in the current situation, ensuring dynamic model selection in the evolving task condition. Our approach is designed to be compatible with agents trained with different random seeds, hyperparameter settings, and various RL algorithms. Extensive experiments on the Atari benchmark show that LLM-Ens significantly improves the RL model ensemble, surpassing well-known baselines by up to 20.9%. For reproducibility, our code is open-source at https://anonymous.4open.science/r/LLM4RLensemble-F7EE.
LLM-Explorer: A Plug-in Reinforcement Learning Policy Exploration Enhancement Driven by Large Language Models
May 21, 2025Policy exploration is critical in reinforcement learning (RL), where existing approaches include greedy, Gaussian process, etc. However, these approaches utilize preset stochastic processes and are indiscriminately applied in all kinds of RL tasks without considering task-specific features that influence policy exploration. Moreover, during RL training, the evolution of such stochastic processes is rigid, which typically only incorporates a decay in the variance, failing to adjust flexibly according to the agent's real-time learning status. Inspired by the analyzing and reasoning capability of large language models (LLMs), we design LLM-Explorer to adaptively generate task-specific exploration strategies with LLMs, enhancing the policy exploration in RL. In our design, we sample the learning trajectory of the agent during the RL training in a given task and prompt the LLM to analyze the agent's current policy learning status and then generate a probability distribution for future policy exploration. Updating the probability distribution periodically, we derive a stochastic process specialized for the particular task and dynamically adjusted to adapt to the learning process. Our design is a plug-in module compatible with various widely applied RL algorithms, including the DQN series, DDPG, TD3, and any possible variants developed based on them. Through extensive experiments on the Atari and MuJoCo benchmarks, we demonstrate LLM-Explorer's capability to enhance RL policy exploration, achieving an average performance improvement up to 37.27%. Our code is open-source at https://anonymous.4open.science/r/LLM-Explorer-19BE for reproducibility.
RL of Thoughts: Navigating LLM Reasoning with Inference-time Reinforcement Learning
May 20, 2025



Despite rapid advancements in large language models (LLMs), the token-level autoregressive nature constrains their complex reasoning capabilities. To enhance LLM reasoning, inference-time techniques, including Chain/Tree/Graph-of-Thought(s), successfully improve the performance, as they are fairly cost-effective by guiding reasoning through sophisticated logical structures without modifying LLMs' parameters. However, these manually predefined, task-agnostic frameworks are applied uniformly across diverse tasks, lacking adaptability. To improve this, we propose RL-of-Thoughts (RLoT), where we train a lightweight navigator model with reinforcement learning (RL) to adaptively enhance LLM reasoning at inference time. Specifically, we design five basic logic blocks from the perspective of human cognition. During the reasoning process, the trained RL navigator dynamically selects the suitable logic blocks and combines them into task-specific logical structures according to problem characteristics. Experiments across multiple reasoning benchmarks (AIME, MATH, GPQA, etc.) with multiple LLMs (GPT, Llama, Qwen, and DeepSeek) illustrate that RLoT outperforms established inference-time techniques by up to 13.4%. Remarkably, with less than 3K parameters, our RL navigator is able to make sub-10B LLMs comparable to 100B-scale counterparts. Moreover, the RL navigator demonstrates strong transferability: a model trained on one specific LLM-task pair can effectively generalize to unseen LLMs and tasks. Our code is open-source at https://anonymous.4open.science/r/RL-LLM-Reasoning-1A30 for reproducibility.
Learning to Estimate Package Delivery Time in Mixed Imbalanced Delivery and Pickup Logistics Services
May 01, 2025Accurately estimating package delivery time is essential to the logistics industry, which enables reasonable work allocation and on-time service guarantee. This becomes even more necessary in mixed logistics scenarios where couriers handle a high volume of delivery and a smaller number of pickup simultaneously. However, most of the related works treat the pickup and delivery patterns on couriers' decision behavior equally, neglecting that the pickup has a greater impact on couriers' decision-making compared to the delivery due to its tighter time constraints. In such context, we have three main challenges: 1) multiple spatiotemporal factors are intricately interconnected, significantly affecting couriers' delivery behavior; 2) pickups have stricter time requirements but are limited in number, making it challenging to model their effects on couriers' delivery process; 3) couriers' spatial mobility patterns are critical determinants of their delivery behavior, but have been insufficiently explored. To deal with these, we propose TransPDT, a Transformer-based multi-task package delivery time prediction model. We first employ the Transformer encoder architecture to capture the spatio-temporal dependencies of couriers' historical travel routes and pending package sets. Then we design the pattern memory to learn the patterns of pickup in the imbalanced dataset via attention mechanism. We also set the route prediction as an auxiliary task of delivery time prediction, and incorporate the prior courier spatial movement regularities in prediction. Extensive experiments on real industry-scale datasets demonstrate the superiority of our method. A system based on TransPDT is deployed internally in JD Logistics to track more than 2000 couriers handling hundreds of thousands of packages per day in Beijing.
DeepSTA: A Spatial-Temporal Attention Network for Logistics Delivery Timely Rate Prediction in Anomaly Conditions
May 01, 2025



Prediction of couriers' delivery timely rates in advance is essential to the logistics industry, enabling companies to take preemptive measures to ensure the normal operation of delivery services. This becomes even more critical during anomaly conditions like the epidemic outbreak, during which couriers' delivery timely rate will decline markedly and fluctuates significantly. Existing studies pay less attention to the logistics scenario. Moreover, many works focusing on prediction tasks in anomaly scenarios fail to explicitly model abnormal events, e.g., treating external factors equally with other features, resulting in great information loss. Further, since some anomalous events occur infrequently, traditional data-driven methods perform poorly in these scenarios. To deal with them, we propose a deep spatial-temporal attention model, named DeepSTA. To be specific, to avoid information loss, we design an anomaly spatio-temporal learning module that employs a recurrent neural network to model incident information. Additionally, we utilize Node2vec to model correlations between road districts, and adopt graph neural networks and long short-term memory to capture the spatial-temporal dependencies of couriers. To tackle the issue of insufficient training data in abnormal circumstances, we propose an anomaly pattern attention module that adopts a memory network for couriers' anomaly feature patterns storage via attention mechanisms. The experiments on real-world logistics datasets during the COVID-19 outbreak in 2022 show the model outperforms the best baselines by 12.11% in MAE and 13.71% in MSE, demonstrating its superior performance over multiple competitive baselines.
The Art of Tool Interface Design
Mar 26, 2025We present an agentic framework, Thinker, which achieves state of art performance in challenging reasoning tasks for realistic customer service scenarios that involve complex business logic and human interactions via long horizons. On the $\tau$-bench retail dataset, Thinker achieves 82.6\% success rate with GPT-4o (version 2024-06-01) (baseline: 68.3\%), and 81.9\% success rate with Llama-3.1 405B (baseline: 49.6\%), without any fine-tuning. Thinker effectively closes the gap in reasoning capabilities between the base models by introducing proper structure. The key features of the Thinker framework are: (1) State-Machine Augmented Generation (SMAG), which represents business logic as state machines and the LLM uses state machines as tools. (2) Delegation of tasks from the main reasoning loop to LLM-powered tools. (3) Adaptive context management. Our prompting-only solution achieves signficant gains, while still maintaining a standard agentic architecture with a ReAct style reasoning loop. The key is to innovate on the tool interface design, as exemplified by SMAG and the LLM-powered tools.
WeightedKV: Attention Scores Weighted Key-Value Cache Merging for Large Language Models
Mar 03, 2025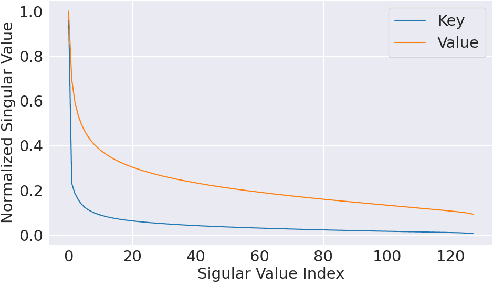
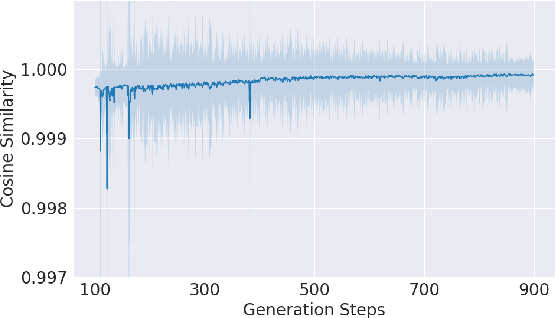
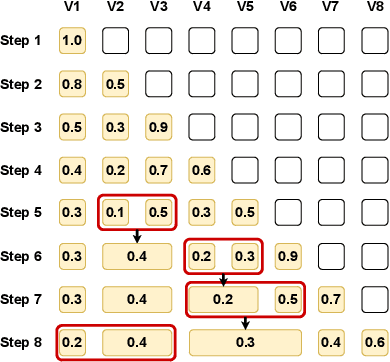
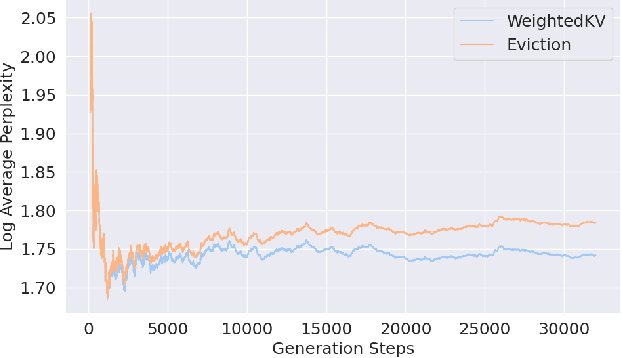
Large Language Models (LLMs) use key-value (KV) cache to reduce redundant computation in autoregressive generation. However, the KV cache size increases linearly during generation, leading to excessive memory usage, especially for long texts. Most KV cache compression methods evict the unimportant KV pairs to maintain a fixed cache size, which leads to the permanent loss of tokens during generation. However, singular value decomposition shows that \textit{values} do not exhibit a strong low-rank property as \textit{keys} do, suggesting that information is distributed more evenly across \textit{values}, in contrast to its more redundant distribution within \textit{keys}. Therefore, methods that evict both \textit{keys} and \textit{values} risk losing crucial information and compromise context integrity, ultimately degrading the output quality. To address this problem, we propose WeightedKV, a novel, training-free approach that discards the \textit{keys} of less important tokens, while merging their \textit{values} into neighboring tokens via a convex combination weighted by their average attention scores. In this way, the retained \textit{keys} serve as anchors that guide the generation process, while the merged \textit{values} provide a rich contextual backdrop. We assess our method on four widely used language modeling datasets, demonstrating superior performance compared to all baseline methods, particularly with a lower budget ratio.
TreeKV: Smooth Key-Value Cache Compression with Tree Structures
Jan 09, 2025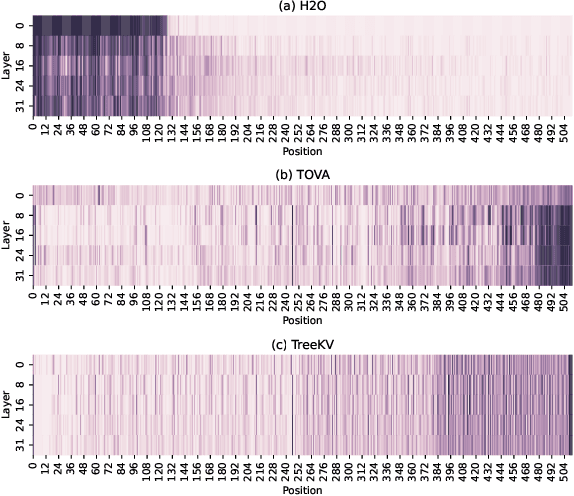
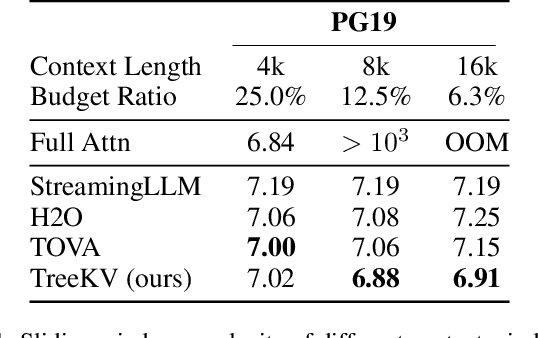
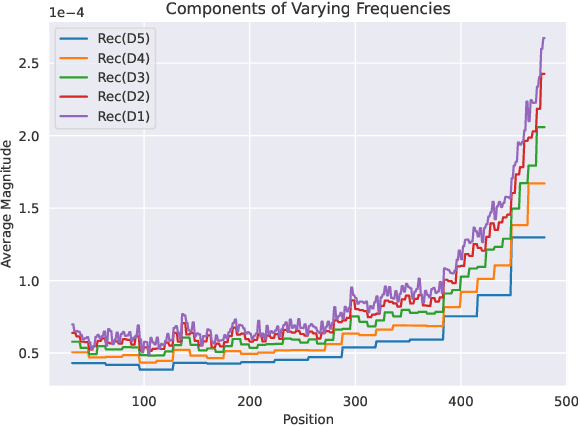
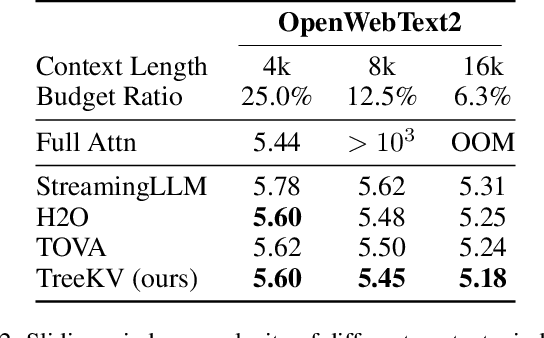
Efficient key-value (KV) cache compression is critical for scaling transformer-based Large Language Models (LLMs) in long sequences and resource-limited settings. Existing methods evict tokens based on their positions or importance scores, but position-based strategies can miss crucial information outside predefined regions, while those relying on global importance scores resulting in strong regional biases, limiting the KV cache's overall context retention and potentially impairing the performance of LLMs on complex tasks. Our wavelet analysis reveals that as tokens approach the end of sequence, their contributions to generation gradually increase and tends to diverge more from neighboring tokens, indicating a smooth transition with increasing complexity and variability from distant to nearby context. Motivated by this observation, we propose TreeKV, an intuitive, training-free method that employs a tree structure for smooth cache compression. TreeKV maintains a fixed cache size, allowing LLMs to deliver high-quality output even in long text scenarios. Unlike most compression methods, TreeKV is applicable to both the generation and prefilling stages. It consistently surpasses all baseline models in language modeling tasks on PG19 and OpenWebText2, allowing LLMs trained with short context window to generalize to longer window with a 16x cache reduction. On the Longbench benchmark, TreeKV achieves the best performance with only 6\% of the budget at optimal efficiency.