 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScholarPeer: A Context-Aware Multi-Agent Framework for Automated Peer Review
Jan 30, 2026Automated peer review has evolved from simple text classification to structured feedback generation. However, current state-of-the-art systems still struggle with "surface-level" critiques: they excel at summarizing content but often fail to accurately assess novelty and significance or identify deep methodological flaws because they evaluate papers in a vacuum, lacking the external context a human expert possesses. In this paper, we introduce ScholarPeer, a search-enabled multi-agent framework designed to emulate the cognitive processes of a senior researcher. ScholarPeer employs a dual-stream process of context acquisition and active verification. It dynamically constructs a domain narrative using a historian agent, identifies missing comparisons via a baseline scout, and verifies claims through a multi-aspect Q&A engine, grounding the critique in live web-scale literature. We evaluate ScholarPeer on DeepReview-13K and the results demonstrate that ScholarPeer achieves significant win-rates against state-of-the-art approaches in side-by-side evaluations and reduces the gap to human-level diversity.
Synapse: Adaptive Arbitration of Complementary Expertise in Time Series Foundational Models
Nov 07, 2025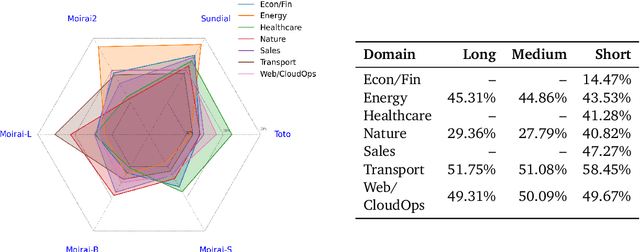
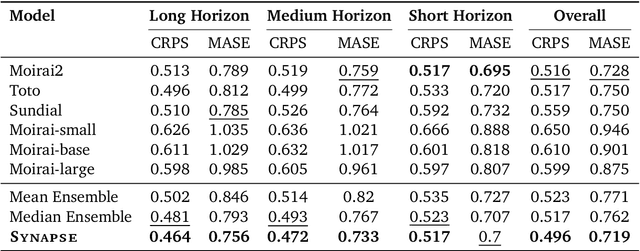
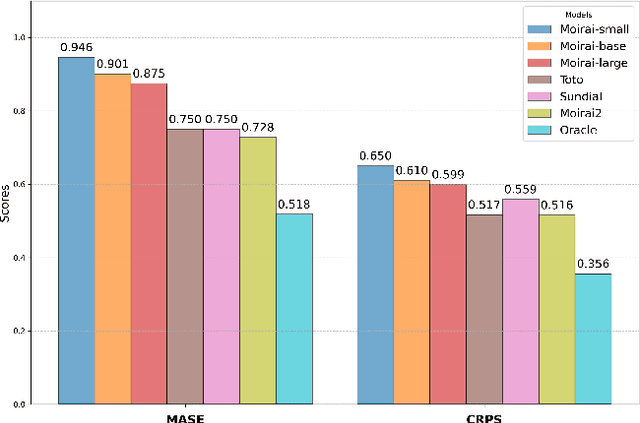

Pre-trained Time Series Foundational Models (TSFMs) represent a significant advance, capable of forecasting diverse time series with complex characteristics, including varied seasonalities, trends, and long-range dependencies. Despite their primary goal of universal time series forecasting, their efficacy is far from uniform; divergent training protocols and data sources cause individual TSFMs to exhibit highly variable performance across different forecasting tasks, domains, and horizons. Leveraging this complementary expertise by arbitrating existing TSFM outputs presents a compelling strategy, yet this remains a largely unexplored area of research. In this paper, we conduct a thorough examination of how different TSFMs exhibit specialized performance profiles across various forecasting settings, and how we can effectively leverage this behavior in arbitration between different time series models. We specifically analyze how factors such as model selection and forecast horizon distribution can influence the efficacy of arbitration strategies. Based on this analysis, we propose Synapse, a novel arbitration framework for TSFMs. Synapse is designed to dynamically leverage a pool of TSFMs, assign and adjust predictive weights based on their relative, context-dependent performance, and construct a robust forecast distribution by adaptively sampling from the output quantiles of constituent models. Experimental results demonstrate that Synapse consistently outperforms other popular ensembling techniques as well as individual TSFMs, demonstrating Synapse's efficacy in time series forecasting.
Watch and Learn: Learning to Use Computers from Online Videos
Oct 06, 2025Computer use agents (CUAs) need to plan task workflows grounded in diverse, ever-changing applications and environments, but learning is hindered by the scarcity of large-scale, high-quality training data in the target application. Existing datasets are domain-specific, static, and costly to annotate, while current synthetic data generation methods often yield simplistic or misaligned task demonstrations. To address these limitations, we introduce Watch & Learn (W&L), a framework that converts human demonstration videos readily available on the Internet into executable UI trajectories at scale. Instead of directly generating trajectories or relying on ad hoc reasoning heuristics, we cast the problem as an inverse dynamics objective: predicting the user's action from consecutive screen states. This formulation reduces manual engineering, is easier to learn, and generalizes more robustly across applications. Concretely, we develop an inverse dynamics labeling pipeline with task-aware video retrieval, generate over 53k high-quality trajectories from raw web videos, and demonstrate that these trajectories improve CUAs both as in-context demonstrations and as supervised training data. On the challenging OSWorld benchmark, UI trajectories extracted with W&L consistently enhance both general-purpose and state-of-the-art frameworks in-context, and deliver stronger gains for open-source models under supervised training. These results highlight web-scale human demonstration videos as a practical and scalable foundation for advancing CUAs towards real-world deployment.
PLAN-TUNING: Post-Training Language Models to Learn Step-by-Step Planning for Complex Problem Solving
Jul 10, 2025Recently, decomposing complex problems into simple subtasks--a crucial part of human-like natural planning--to solve the given problem has significantly boosted the performance of large language models (LLMs). However, leveraging such planning structures during post-training to boost the performance of smaller open-source LLMs remains underexplored. Motivated by this, we introduce PLAN-TUNING, a unified post-training framework that (i) distills synthetic task decompositions (termed "planning trajectories") from large-scale LLMs and (ii) fine-tunes smaller models via supervised and reinforcement-learning objectives designed to mimic these planning processes to improve complex reasoning. On GSM8k and the MATH benchmarks, plan-tuned models outperform strong baselines by an average $\sim7\%$. Furthermore, plan-tuned models show better generalization capabilities on out-of-domain datasets, with average $\sim10\%$ and $\sim12\%$ performance improvements on OlympiadBench and AIME 2024, respectively. Our detailed analysis demonstrates how planning trajectories improves complex reasoning capabilities, showing that PLAN-TUNING is an effective strategy for improving task-specific performance of smaller LLMs.
LLM-Explorer: A Plug-in Reinforcement Learning Policy Exploration Enhancement Driven by Large Language Models
May 21, 2025Policy exploration is critical in reinforcement learning (RL), where existing approaches include greedy, Gaussian process, etc. However, these approaches utilize preset stochastic processes and are indiscriminately applied in all kinds of RL tasks without considering task-specific features that influence policy exploration. Moreover, during RL training, the evolution of such stochastic processes is rigid, which typically only incorporates a decay in the variance, failing to adjust flexibly according to the agent's real-time learning status. Inspired by the analyzing and reasoning capability of large language models (LLMs), we design LLM-Explorer to adaptively generate task-specific exploration strategies with LLMs, enhancing the policy exploration in RL. In our design, we sample the learning trajectory of the agent during the RL training in a given task and prompt the LLM to analyze the agent's current policy learning status and then generate a probability distribution for future policy exploration. Updating the probability distribution periodically, we derive a stochastic process specialized for the particular task and dynamically adjusted to adapt to the learning process. Our design is a plug-in module compatible with various widely applied RL algorithms, including the DQN series, DDPG, TD3, and any possible variants developed based on them. Through extensive experiments on the Atari and MuJoCo benchmarks, we demonstrate LLM-Explorer's capability to enhance RL policy exploration, achieving an average performance improvement up to 37.27%. Our code is open-source at https://anonymous.4open.science/r/LLM-Explorer-19BE for reproducibility.
Multiple Weaks Win Single Strong: Large Language Models Ensemble Weak Reinforcement Learning Agents into a Supreme One
May 21, 2025Model ensemble is a useful approach in reinforcement learning (RL) for training effective agents. Despite wide success of RL, training effective agents remains difficult due to the multitude of factors requiring careful tuning, such as algorithm selection, hyperparameter settings, and even random seed choices, all of which can significantly influence an agent's performance. Model ensemble helps overcome this challenge by combining multiple weak agents into a single, more powerful one, enhancing overall performance. However, existing ensemble methods, such as majority voting and Boltzmann addition, are designed as fixed strategies and lack a semantic understanding of specific tasks, limiting their adaptability and effectiveness. To address this, we propose LLM-Ens, a novel approach that enhances RL model ensemble with task-specific semantic understandings driven by large language models (LLMs). Given a task, we first design an LLM to categorize states in this task into distinct 'situations', incorporating high-level descriptions of the task conditions. Then, we statistically analyze the strengths and weaknesses of each individual agent to be used in the ensemble in each situation. During the inference time, LLM-Ens dynamically identifies the changing task situation and switches to the agent that performs best in the current situation, ensuring dynamic model selection in the evolving task condition. Our approach is designed to be compatible with agents trained with different random seeds, hyperparameter settings, and various RL algorithms. Extensive experiments on the Atari benchmark show that LLM-Ens significantly improves the RL model ensemble, surpassing well-known baselines by up to 20.9%. For reproducibility, our code is open-source at https://anonymous.4open.science/r/LLM4RLensemble-F7EE.
Review, Refine, Repeat: Understanding Iterative Decoding of AI Agents with Dynamic Evaluation and Selection
Apr 02, 2025While AI agents have shown remarkable performance at various tasks, they still struggle with complex multi-modal applications, structured generation and strategic planning. Improvements via standard fine-tuning is often impractical, as solving agentic tasks usually relies on black box API access without control over model parameters. Inference-time methods such as Best-of-N (BON) sampling offer a simple yet effective alternative to improve performance. However, BON lacks iterative feedback integration mechanism. Hence, we propose Iterative Agent Decoding (IAD) which combines iterative refinement with dynamic candidate evaluation and selection guided by a verifier. IAD differs in how feedback is designed and integrated, specifically optimized to extract maximal signal from reward scores. We conduct a detailed comparison of baselines across key metrics on Sketch2Code, Text2SQL, and Webshop where IAD consistently outperforms baselines, achieving 3--6% absolute gains on Sketch2Code and Text2SQL (with and without LLM judges) and 8--10% gains on Webshop across multiple metrics. To better understand the source of IAD's gains, we perform controlled experiments to disentangle the effect of adaptive feedback from stochastic sampling, and find that IAD's improvements are primarily driven by verifier-guided refinement, not merely sampling diversity. We also show that both IAD and BON exhibit inference-time scaling with increased compute when guided by an optimal verifier. Our analysis highlights the critical role of verifier quality in effective inference-time optimization and examines the impact of noisy and sparse rewards on scaling behavior. Together, these findings offer key insights into the trade-offs and principles of effective inference-time optimization.
ShieldGemma 2: Robust and Tractable Image Content Moderation
Apr 01, 2025We introduce ShieldGemma 2, a 4B parameter image content moderation model built on Gemma 3. This model provides robust safety risk predictions across the following key harm categories: Sexually Explicit, Violence \& Gore, and Dangerous Content for synthetic images (e.g. output of any image generation model) and natural images (e.g. any image input to a Vision-Language Model). We evaluated on both internal and external benchmarks to demonstrate state-of-the-art performance compared to LlavaGuard \citep{helff2024llavaguard}, GPT-4o mini \citep{hurst2024gpt}, and the base Gemma 3 model \citep{gemma_2025} based on our policies. Additionally, we present a novel adversarial data generation pipeline which enables a controlled, diverse, and robust image generation. ShieldGemma 2 provides an open image moderation tool to advance multimodal safety and responsible AI development.
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents
Mar 11, 2025Large Language Models (LLMs) have made significant progress in open-ended dialogue, yet their inability to retain and retrieve relevant information from long-term interactions limits their effectiveness in applications requiring sustained personalization. External memory mechanisms have been proposed to address this limitation, enabling LLMs to maintain conversational continuity. However, existing approaches struggle with two key challenges. First, rigid memory granularity fails to capture the natural semantic structure of conversations, leading to fragmented and incomplete representations. Second, fixed retrieval mechanisms cannot adapt to diverse dialogue contexts and user interaction patterns. In this work, we propose Reflective Memory Management (RMM), a novel mechanism for long-term dialogue agents, integrating forward- and backward-looking reflections: (1) Prospective Reflection, which dynamically summarizes interactions across granularities-utterances, turns, and sessions-into a personalized memory bank for effective future retrieval, and (2) Retrospective Reflection, which iteratively refines the retrieval in an online reinforcement learning (RL) manner based on LLMs' cited evidence. Experiments show that RMM demonstrates consistent improvement across various metrics and benchmarks. For example, RMM shows more than 10% accuracy improvement over the baseline without memory management on the LongMemEval dataset.
Towards Large Reasoning Models: A Survey on Scaling LLM Reasoning Capabilities
Jan 17, 2025



Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.