 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACO: Parts and Attributes of Common Objects
Jan 04, 2023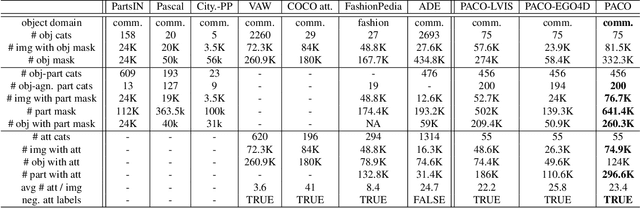
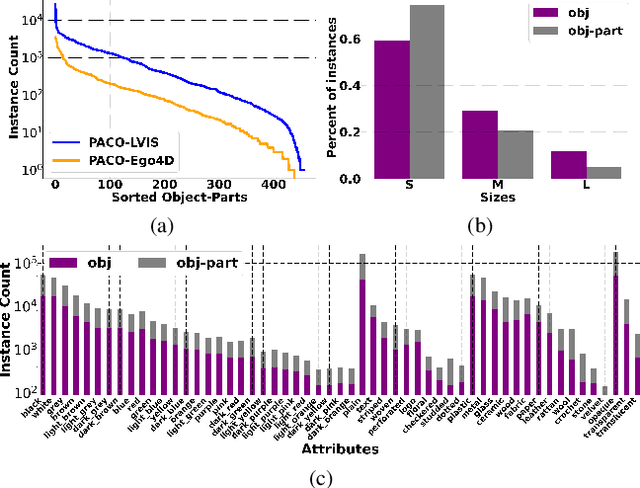
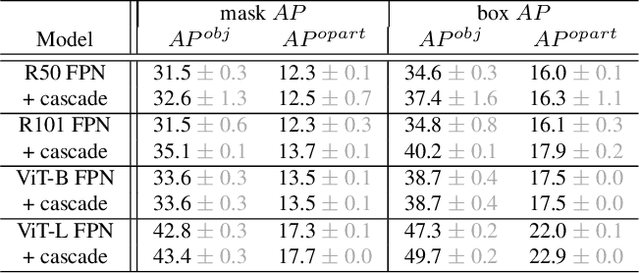

Object models are gradually progressing from predicting just category labels to providing detailed descriptions of object instances. This motivates the need for large datasets which go beyond traditional object masks and provide richer annotations such as part masks and attributes. Hence, we introduce PACO: Parts and Attributes of Common Objects. It spans 75 object categories, 456 object-part categories and 55 attributes across image (LVIS) and video (Ego4D) datasets. We provide 641K part masks annotated across 260K object boxes, with roughly half of them exhaustively annotated with attributes as well. We design evaluation metrics and provide benchmark results for three tasks on the dataset: part mask segmentation, object and part attribute prediction and zero-shot instance detection. Dataset, models, and code are open-sourced at https://github.com/facebookresearch/paco.
Task Grouping for Multilingual Text Recognition
Oct 13, 2022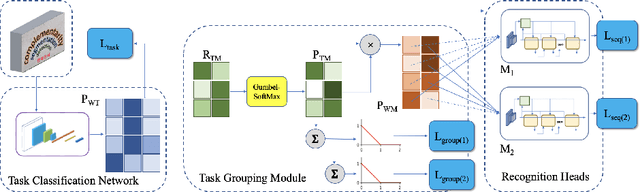
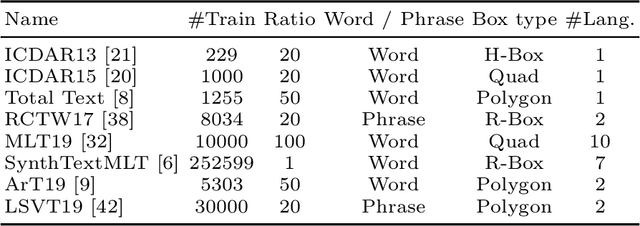
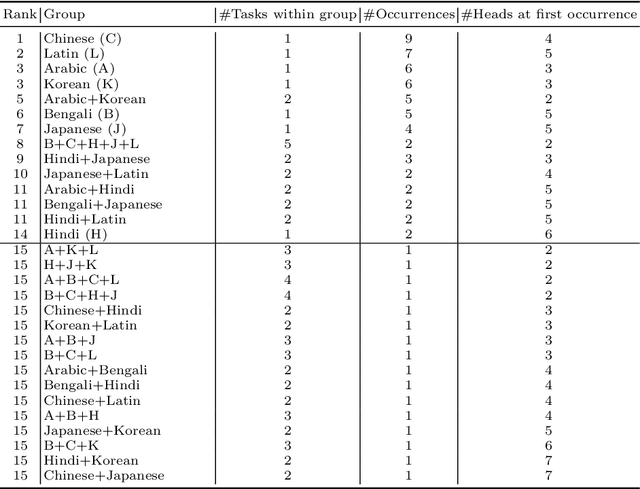

Most existing OCR methods focus on alphanumeric characters due to the popularity of English and numbers, as well as their corresponding datasets. On extending the characters to more languages, recent methods have shown that training different scripts with different recognition heads can greatly improve the end-to-end recognition accuracy compared to combining characters from all languages in the same recognition head. However, we postulate that similarities between some languages could allow sharing of model parameters and benefit from joint training. Determining language groupings, however, is not immediately obvious. To this end, we propose an automatic method for multilingual text recognition with a task grouping and assignment module using Gumbel-Softmax, introducing a task grouping loss and weighted recognition loss to allow for simultaneous training of the models and grouping modules. Experiments on MLT19 lend evidence to our hypothesis that there is a middle ground between combining every task together and separating every task that achieves a better configuration of task grouping/separation.
TextStyleBrush: Transfer of Text Aesthetics from a Single Example
Jun 15, 2021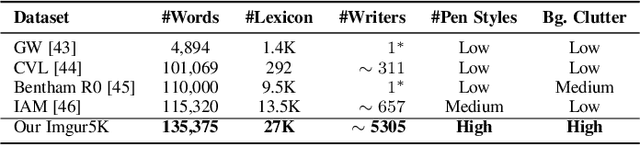

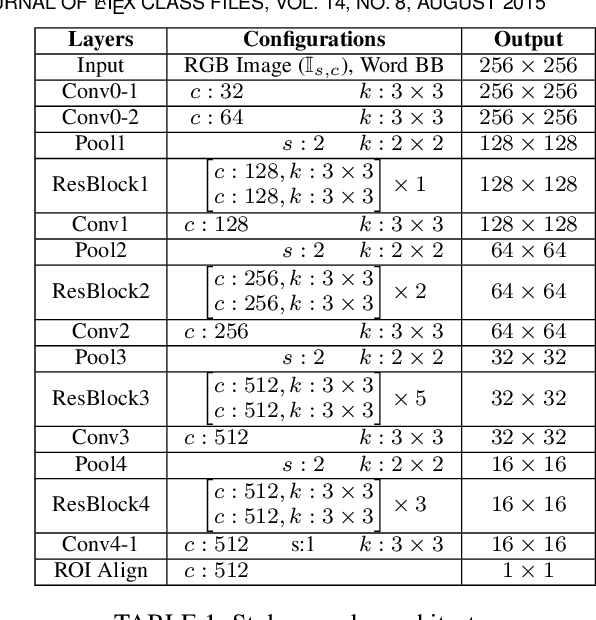
We present a novel approach for disentangling the content of a text image from all aspects of its appearance. The appearance representation we derive can then be applied to new content, for one-shot transfer of the source style to new content. We learn this disentanglement in a self-supervised manner. Our method processes entire word boxes, without requiring segmentation of text from background, per-character processing, or making assumptions on string lengths. We show results in different text domains which were previously handled by specialized methods, e.g., scene text, handwritten text. To these ends, we make a number of technical contributions: (1) We disentangle the style and content of a textual image into a non-parametric, fixed-dimensional vector. (2) We propose a novel approach inspired by StyleGAN but conditioned over the example style at different resolution and content. (3) We present novel self-supervised training criteria which preserve both source style and target content using a pre-trained font classifier and text recognizer. Finally, (4) we also introduce Imgur5K, a new challenging dataset for handwritten word images. We offer numerous qualitative photo-realistic results of our method. We further show that our method surpasses previous work in quantitative tests on scene text and handwriting datasets, as well as in a user study.
A Multiplexed Network for End-to-End, Multilingual OCR
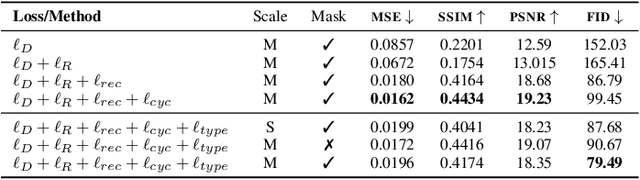
Mar 29, 2021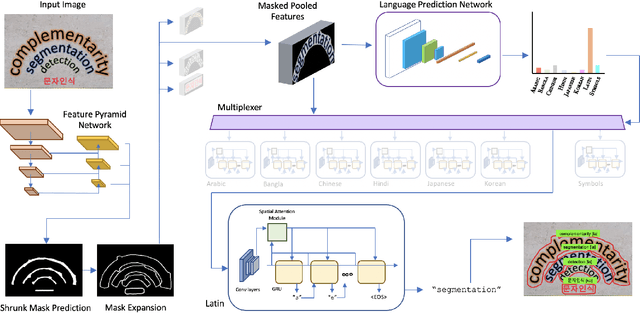
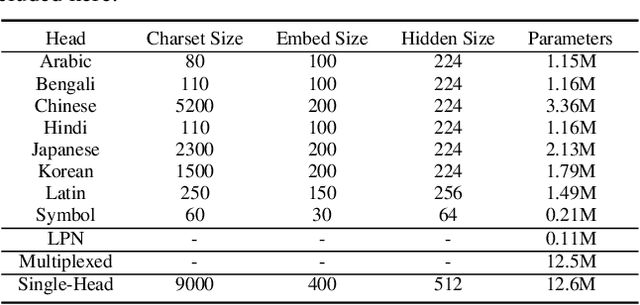
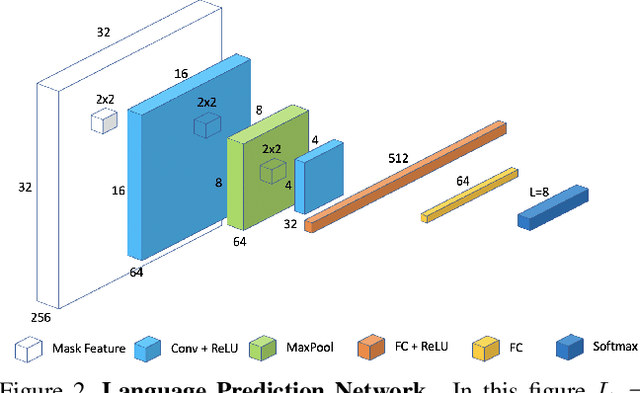
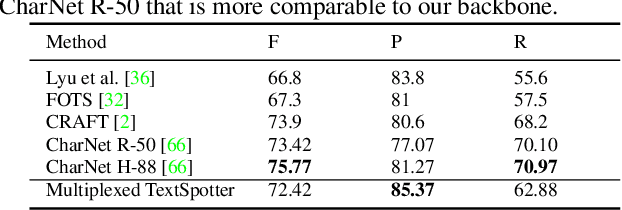
Recent advances in OCR have shown that an end-to-end (E2E) training pipeline that includes both detection and recognition leads to the best results. However, many existing methods focus primarily on Latin-alphabet languages, often even only case-insensitive English characters. In this paper, we propose an E2E approach, Multiplexed Multilingual Mask TextSpotter, that performs script identification at the word level and handles different scripts with different recognition heads, all while maintaining a unified loss that simultaneously optimizes script identification and multiple recognition heads. Experiments show that our method outperforms the single-head model with similar number of parameters in end-to-end recognition tasks, and achieves state-of-the-art results on MLT17 and MLT19 joint text detection and script identification benchmarks. We believe that our work is a step towards the end-to-end trainable and scalable multilingual multi-purpose OCR system. Our code and model will be released.
PIRC Net : Using Proposal Indexing, Relationships and Context for Phrase Grounding
Dec 07, 2018
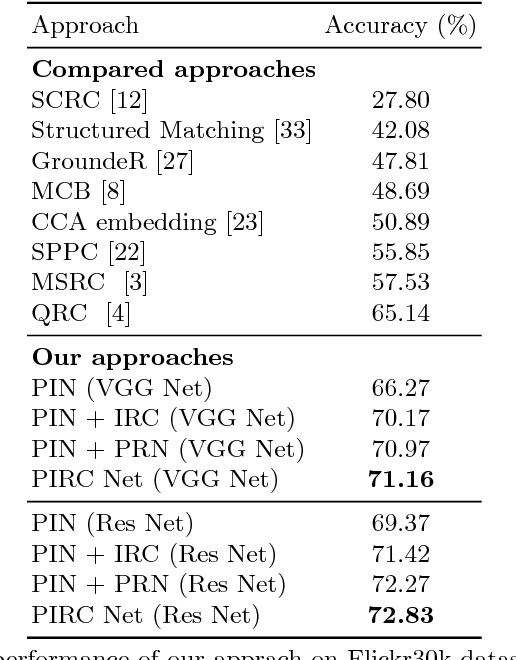
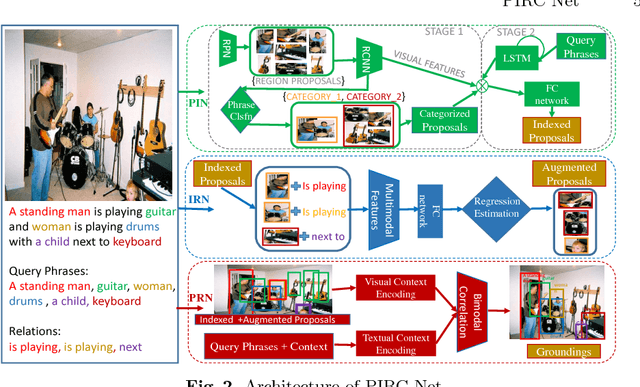

Phrase Grounding aims to detect and localize objects in images that are referred to and are queried by natural language phrases. Phrase grounding finds applications in tasks such as Visual Dialog, Visual Search and Image-text co-reference resolution. In this paper, we present a framework that leverages information such as phrase category, relationships among neighboring phrases in a sentence and context to improve the performance of phrase grounding systems. We propose three modules: Proposal Indexing Network(PIN); Inter-phrase Regression Network(IRN) and Proposal Ranking Network(PRN) each of which analyze the region proposals of an image at increasing levels of detail by incorporating the above information. Also, in the absence of ground-truth spatial locations of the phrases(weakly-supervised), we propose knowledge transfer mechanisms that leverages the framework of PIN module. We demonstrate the effectiveness of our approach on the Flickr 30k Entities and ReferItGame datasets, for which we achieve improvements over state-of-the-art approaches in both supervised and weakly-supervised variants.
Query-guided Regression Network with Context Policy for Phrase Grounding
Aug 04, 2017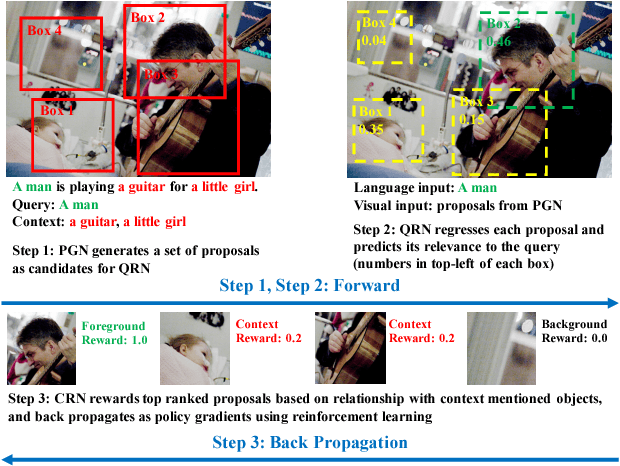
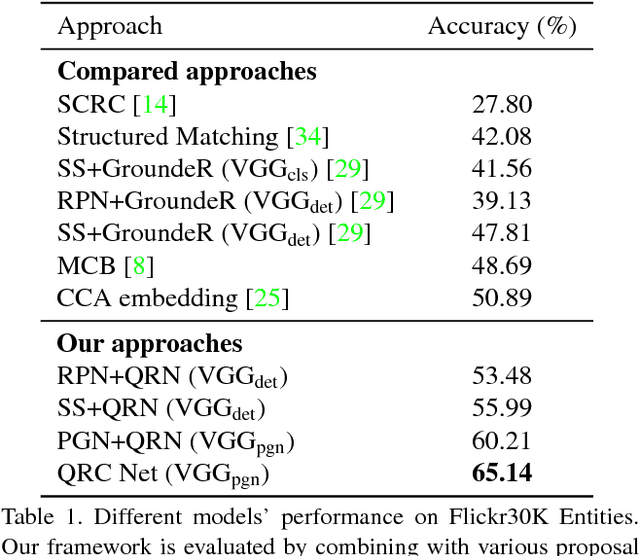
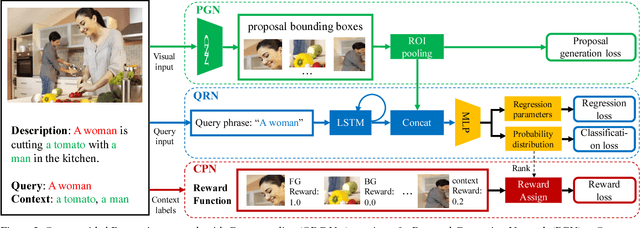
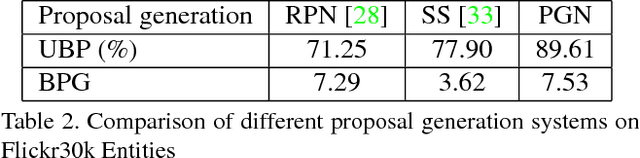
Given a textual description of an image, phrase grounding localizes objects in the image referred by query phrases in the description. State-of-the-art methods address the problem by ranking a set of proposals based on the relevance to each query, which are limited by the performance of independent proposal generation systems and ignore useful cues from context in the description. In this paper, we adopt a spatial regression method to break the performance limit, and introduce reinforcement learning techniques to further leverage semantic context information. We propose a novel Query-guided Regression network with Context policy (QRC Net) which jointly learns a Proposal Generation Network (PGN), a Query-guided Regression Network (QRN) and a Context Policy Network (CPN). Experiments show QRC Net provides a significant improvement in accuracy on two popular datasets: Flickr30K Entities and Referit Game, with 14.25% and 17.14% increase over the state-of-the-arts respectively.