 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
SceneTextGen: Layout-Agnostic Scene Text Image Synthesis with Diffusion Models
Jun 03, 2024



While diffusion models have significantly advanced the quality of image generation, their capability to accurately and coherently render text within these images remains a substantial challenge. Conventional diffusion-based methods for scene text generation are typically limited by their reliance on an intermediate layout output. This dependency often results in a constrained diversity of text styles and fonts, an inherent limitation stemming from the deterministic nature of the layout generation phase. To address these challenges, this paper introduces SceneTextGen, a novel diffusion-based model specifically designed to circumvent the need for a predefined layout stage. By doing so, SceneTextGen facilitates a more natural and varied representation of text. The novelty of SceneTextGen lies in its integration of three key components: a character-level encoder for capturing detailed typographic properties, coupled with a character-level instance segmentation model and a word-level spotting model to address the issues of unwanted text generation and minor character inaccuracies. We validate the performance of our method by demonstrating improved character recognition rates on generated images across different public visual text datasets in comparison to both standard diffusion based methods and text specific methods.
DISGO: Automatic End-to-End Evaluation for Scene Text OCR
Aug 25, 2023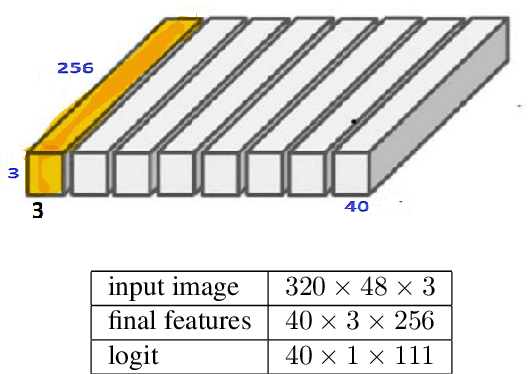


This paper discusses the challenges of optical character recognition (OCR) on natural scenes, which is harder than OCR on documents due to the wild content and various image backgrounds. We propose to uniformly use word error rates (WER) as a new measurement for evaluating scene-text OCR, both end-to-end (e2e) performance and individual system component performances. Particularly for the e2e metric, we name it DISGO WER as it considers Deletion, Insertion, Substitution, and Grouping/Ordering errors. Finally we propose to utilize the concept of super blocks to automatically compute BLEU scores for e2e OCR machine translation. The small SCUT public test set is used to demonstrate WER performance by a modularized OCR system.
TextStyleBrush: Transfer of Text Aesthetics from a Single Example
Jun 15, 2021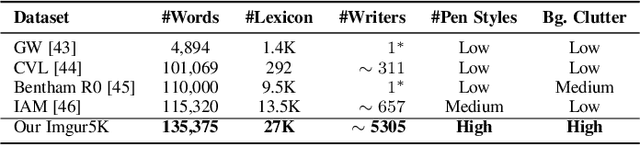

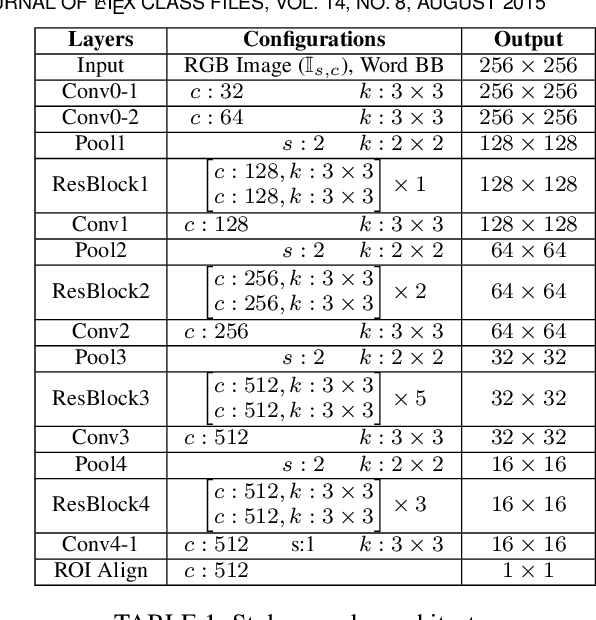
We present a novel approach for disentangling the content of a text image from all aspects of its appearance. The appearance representation we derive can then be applied to new content, for one-shot transfer of the source style to new content. We learn this disentanglement in a self-supervised manner. Our method processes entire word boxes, without requiring segmentation of text from background, per-character processing, or making assumptions on string lengths. We show results in different text domains which were previously handled by specialized methods, e.g., scene text, handwritten text. To these ends, we make a number of technical contributions: (1) We disentangle the style and content of a textual image into a non-parametric, fixed-dimensional vector. (2) We propose a novel approach inspired by StyleGAN but conditioned over the example style at different resolution and content. (3) We present novel self-supervised training criteria which preserve both source style and target content using a pre-trained font classifier and text recognizer. Finally, (4) we also introduce Imgur5K, a new challenging dataset for handwritten word images. We offer numerous qualitative photo-realistic results of our method. We further show that our method surpasses previous work in quantitative tests on scene text and handwriting datasets, as well as in a user study.
A Multiplexed Network for End-to-End, Multilingual OCR
Mar 29, 2021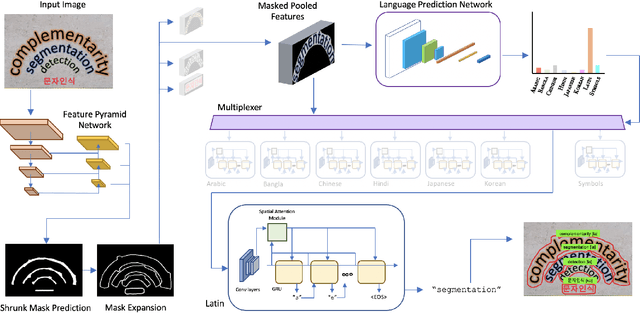
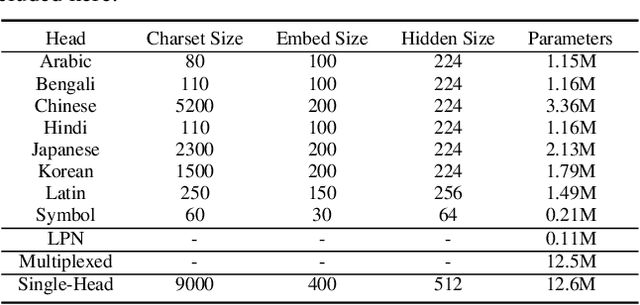
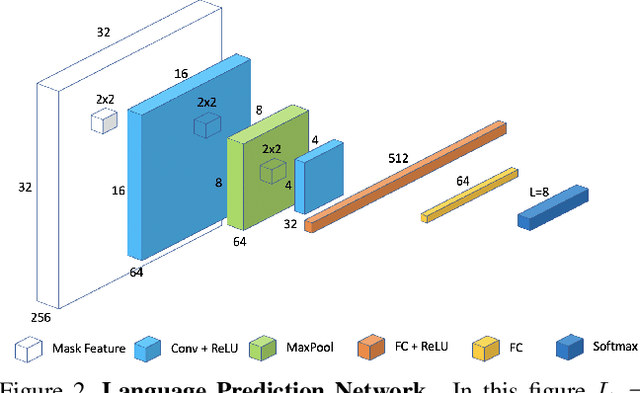
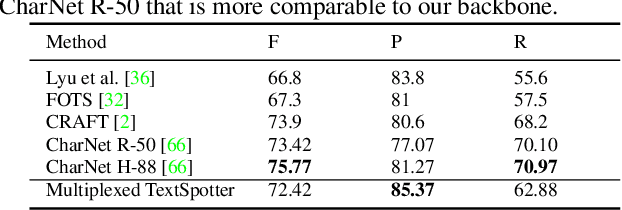
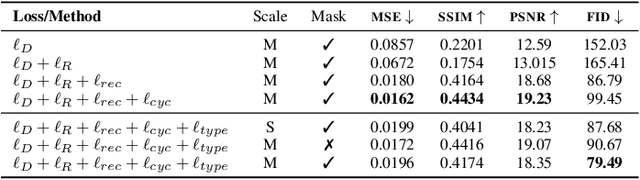
Recent advances in OCR have shown that an end-to-end (E2E) training pipeline that includes both detection and recognition leads to the best results. However, many existing methods focus primarily on Latin-alphabet languages, often even only case-insensitive English characters. In this paper, we propose an E2E approach, Multiplexed Multilingual Mask TextSpotter, that performs script identification at the word level and handles different scripts with different recognition heads, all while maintaining a unified loss that simultaneously optimizes script identification and multiple recognition heads. Experiments show that our method outperforms the single-head model with similar number of parameters in end-to-end recognition tasks, and achieves state-of-the-art results on MLT17 and MLT19 joint text detection and script identification benchmarks. We believe that our work is a step towards the end-to-end trainable and scalable multilingual multi-purpose OCR system. Our code and model will be released.
Improving Word Recognition using Multiple Hypotheses and Deep Embeddings
Oct 27, 2020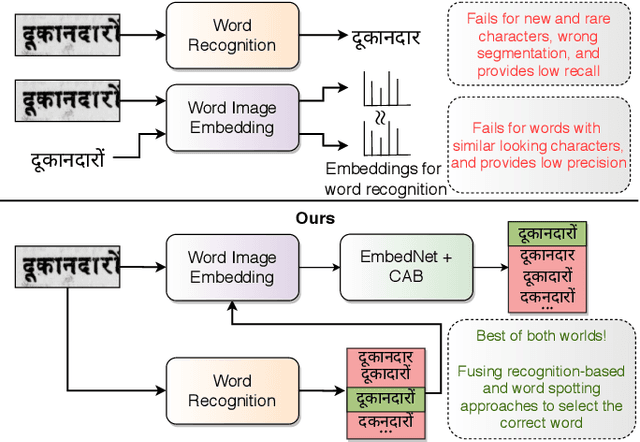
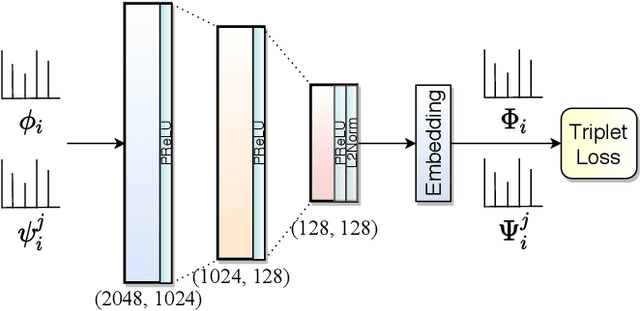
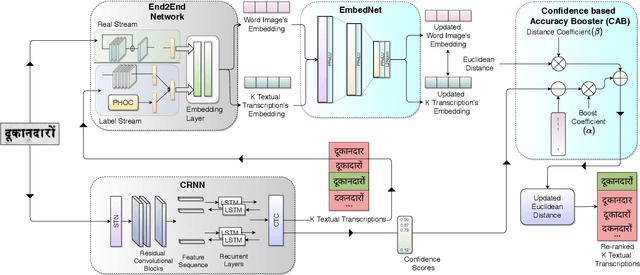
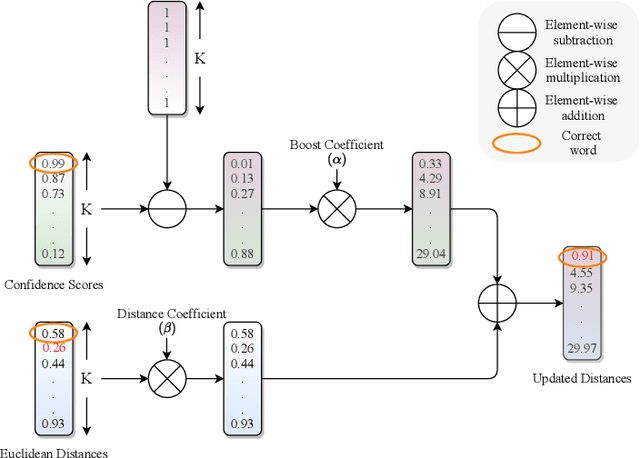
We propose a novel scheme for improving the word recognition accuracy using word image embeddings. We use a trained text recognizer, which can predict multiple text hypothesis for a given word image. Our fusion scheme improves the recognition process by utilizing the word image and text embeddings obtained from a trained word image embedding network. We propose EmbedNet, which is trained using a triplet loss for learning a suitable embedding space where the embedding of the word image lies closer to the embedding of the corresponding text transcription. The updated embedding space thus helps in choosing the correct prediction with higher confidence. To further improve the accuracy, we propose a plug-and-play module called Confidence based Accuracy Booster (CAB). The CAB module takes in the confidence scores obtained from the text recognizer and Euclidean distances between the embeddings to generate an updated distance vector. The updated distance vector has lower distance values for the correct words and higher distance values for the incorrect words. We rigorously evaluate our proposed method systematically on a collection of books in the Hindi language. Our method achieves an absolute improvement of around 10 percent in terms of word recognition accuracy.
Fused Text Recogniser and Deep Embeddings Improve Word Recognition and Retrieval
Jul 01, 2020
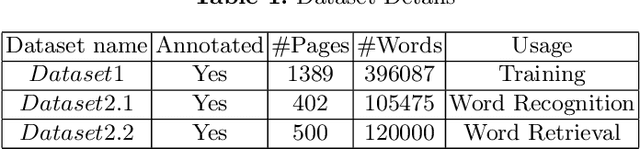
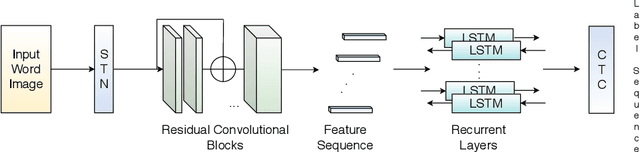

Recognition and retrieval of textual content from the large document collections have been a powerful use case for the document image analysis community. Often the word is the basic unit for recognition as well as retrieval. Systems that rely only on the text recogniser (OCR) output are not robust enough in many situations, especially when the word recognition rates are poor, as in the case of historic documents or digital libraries. An alternative has been word spotting based methods that retrieve/match words based on a holistic representation of the word. In this paper, we fuse the noisy output of text recogniser with a deep embeddings representation derived out of the entire word. We use average and max fusion for improving the ranked results in the case of retrieval. We validate our methods on a collection of Hindi documents. We improve word recognition rate by 1.4 and retrieval by 11.13 in the mAP.
HWNet v2: An Efficient Word Image Representation for Handwritten Documents
Feb 17, 2018
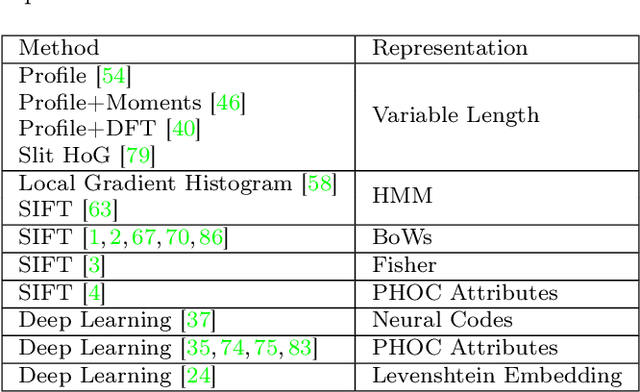
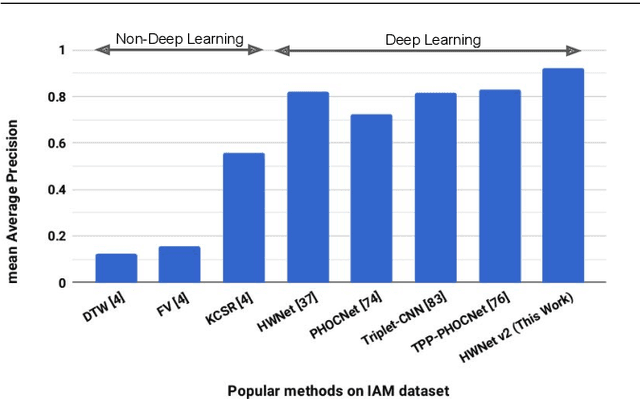

We present a framework for learning efficient holistic representation for handwritten word images. The proposed method uses a deep convolutional neural network with traditional classification loss. The major strengths of our work lie in: (i) the efficient usage of synthetic data to pre-train a deep network, (ii) an adapted version of ResNet-34 architecture with region of interest pooling (referred as HWNet v2) which learns discriminative features with variable sized word images, and (iii) realistic augmentation of training data with multiple scales and elastic distortion which mimics the natural process of handwriting. We further investigate the process of fine-tuning at various layers to reduce the domain gap between synthetic and real domain and also analyze the in-variances learned at different layers using recent visualization techniques proposed in literature. Our representation leads to state of the art word spotting performance on standard handwritten datasets and historical manuscripts in different languages with minimal representation size. On the challenging IAM dataset, our method is first to report an mAP above 0.90 for word spotting with a representation size of just 32 dimensions. Further more, we also present results on printed document datasets in English and Indic scripts which validates the generic nature of the proposed framework for learning word image representation.
Generating Synthetic Data for Text Recognition
Aug 15, 2016

Generating synthetic images is an art which emulates the natural process of image generation in a closest possible manner. In this work, we exploit such a framework for data generation in handwritten domain. We render synthetic data using open source fonts and incorporate data augmentation schemes. As part of this work, we release 9M synthetic handwritten word image corpus which could be useful for training deep network architectures and advancing the performance in handwritten word spotting and recognition tasks.