 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextStyleBrush: Transfer of Text Aesthetics from a Single Example
Paper and Code
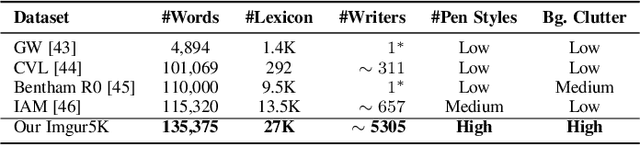

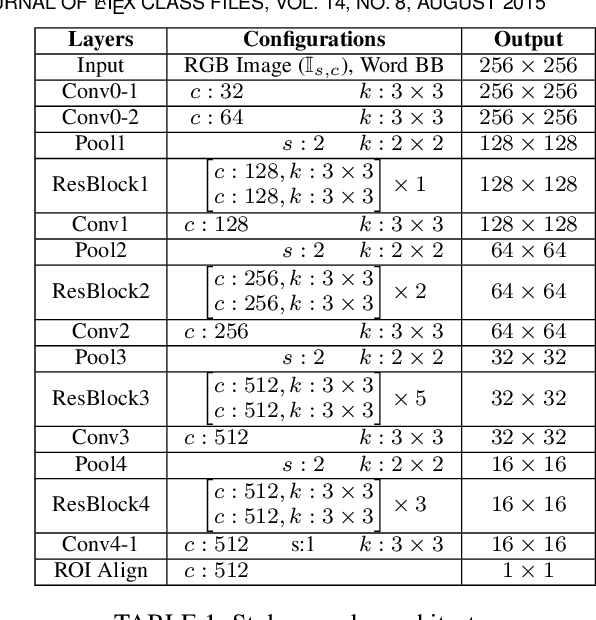
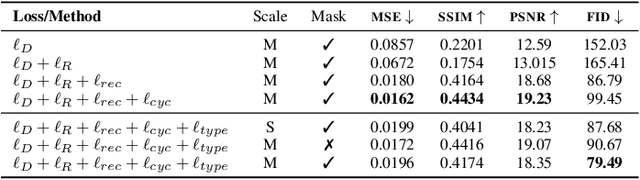
We present a novel approach for disentangling the content of a text image from all aspects of its appearance. The appearance representation we derive can then be applied to new content, for one-shot transfer of the source style to new content. We learn this disentanglement in a self-supervised manner. Our method processes entire word boxes, without requiring segmentation of text from background, per-character processing, or making assumptions on string lengths. We show results in different text domains which were previously handled by specialized methods, e.g., scene text, handwritten text. To these ends, we make a number of technical contributions: (1) We disentangle the style and content of a textual image into a non-parametric, fixed-dimensional vector. (2) We propose a novel approach inspired by StyleGAN but conditioned over the example style at different resolution and content. (3) We present novel self-supervised training criteria which preserve both source style and target content using a pre-trained font classifier and text recognizer. Finally, (4) we also introduce Imgur5K, a new challenging dataset for handwritten word images. We offer numerous qualitative photo-realistic results of our method. We further show that our method surpasses previous work in quantitative tests on scene text and handwriting datasets, as well as in a user study.