 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Biasing of Named-Entities with Large Language Models
Sep 22, 2023



This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.
DISGO: Automatic End-to-End Evaluation for Scene Text OCR
Aug 25, 2023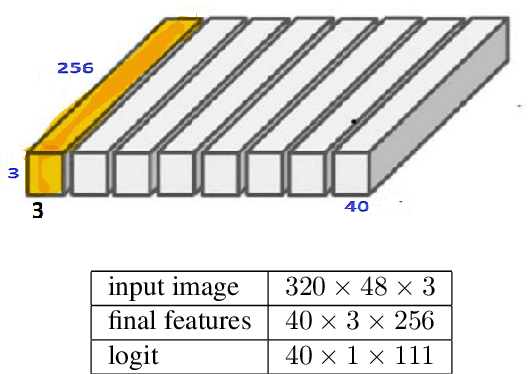

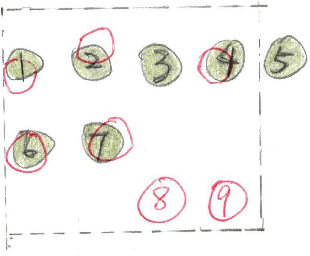

This paper discusses the challenges of optical character recognition (OCR) on natural scenes, which is harder than OCR on documents due to the wild content and various image backgrounds. We propose to uniformly use word error rates (WER) as a new measurement for evaluating scene-text OCR, both end-to-end (e2e) performance and individual system component performances. Particularly for the e2e metric, we name it DISGO WER as it considers Deletion, Insertion, Substitution, and Grouping/Ordering errors. Finally we propose to utilize the concept of super blocks to automatically compute BLEU scores for e2e OCR machine translation. The small SCUT public test set is used to demonstrate WER performance by a modularized OCR system.
Joint Audio/Text Training for Transformer Rescorer of Streaming Speech Recognition
Oct 31, 2022



Recently, there has been an increasing interest in two-pass streaming end-to-end speech recognition (ASR) that incorporates a 2nd-pass rescoring model on top of the conventional 1st-pass streaming ASR model to improve recognition accuracy while keeping latency low. One of the latest 2nd-pass rescoring model, Transformer Rescorer, takes the n-best initial outputs and audio embeddings from the 1st-pass model, and then choose the best output by re-scoring the n-best initial outputs. However, training this Transformer Rescorer requires expensive paired audio-text training data because the model uses audio embeddings as input. In this work, we present our Joint Audio/Text training method for Transformer Rescorer, to leverage unpaired text-only data which is relatively cheaper than paired audio-text data. We evaluate Transformer Rescorer with our Joint Audio/Text training on Librispeech dataset as well as our large-scale in-house dataset and show that our training method can improve word error rate (WER) significantly compared to standard Transformer Rescorer without requiring any extra model parameters or latency.