 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical in-Context Reinforcement Learning with Hindsight Modular Reflections for Planning
Aug 12, 2024Large Language Models (LLMs) have demonstrated remarkable abilities in various language tasks, making them promising candidates for decision-making in robotics. Inspired by Hierarchical Reinforcement Learning (HRL), we propose Hierarchical in-Context Reinforcement Learning (HCRL), a novel framework that decomposes complex tasks into sub-tasks using an LLM-based high-level policy, in which a complex task is decomposed into sub-tasks by a high-level policy on-the-fly. The sub-tasks, defined by goals, are assigned to the low-level policy to complete. Once the LLM agent determines that the goal is finished, a new goal will be proposed. To improve the agent's performance in multi-episode execution, we propose Hindsight Modular Reflection (HMR), where, instead of reflecting on the full trajectory, we replace the task objective with intermediate goals and let the agent reflect on shorter trajectories to improve reflection efficiency. We evaluate the decision-making ability of the proposed HCRL in three benchmark environments--ALFWorld, Webshop, and HotpotQA. Results show that HCRL can achieve 9%, 42%, and 10% performance improvement in 5 episodes of execution over strong in-context learning baselines.
LLM-based Multi-Agent Reinforcement Learning: Current and Future Directions
May 17, 2024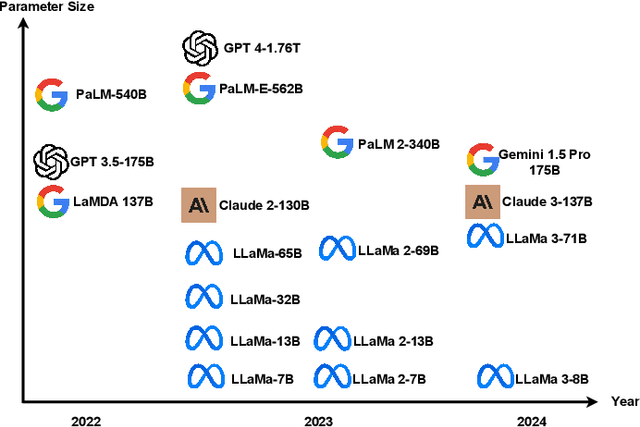
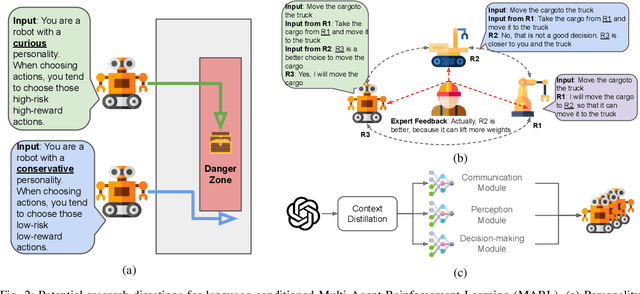
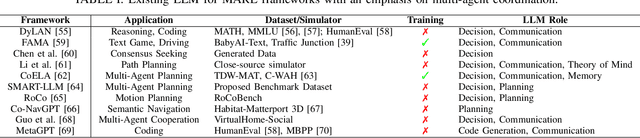
In recent years, Large Language Models (LLMs) have shown great abilities in various tasks, including question answering, arithmetic problem solving, and poem writing, among others. Although research on LLM-as-an-agent has shown that LLM can be applied to Reinforcement Learning (RL) and achieve decent results, the extension of LLM-based RL to Multi-Agent System (MAS) is not trivial, as many aspects, such as coordination and communication between agents, are not considered in the RL frameworks of a single agent. To inspire more research on LLM-based MARL, in this letter, we survey the existing LLM-based single-agent and multi-agent RL frameworks and provide potential research directions for future research. In particular, we focus on the cooperative tasks of multiple agents with a common goal and communication among them. We also consider human-in/on-the-loop scenarios enabled by the language component in the framework.
Contextual Biasing of Named-Entities with Large Language Models
Sep 22, 2023



This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.