 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHWNet v2: An Efficient Word Image Representation for Handwritten Documents
Paper and Code
Feb 17, 2018
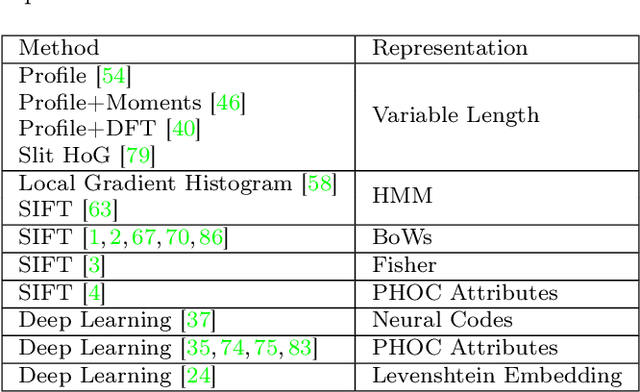
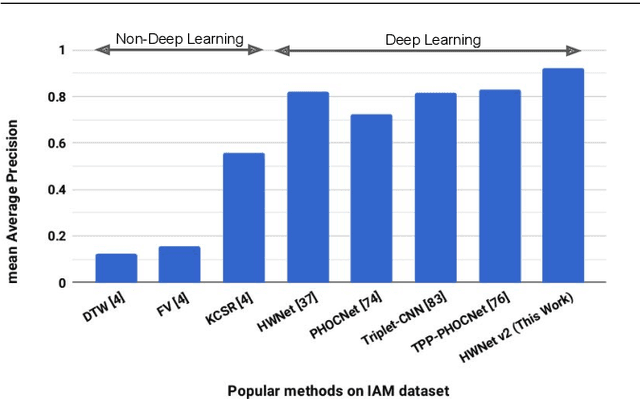

We present a framework for learning efficient holistic representation for handwritten word images. The proposed method uses a deep convolutional neural network with traditional classification loss. The major strengths of our work lie in: (i) the efficient usage of synthetic data to pre-train a deep network, (ii) an adapted version of ResNet-34 architecture with region of interest pooling (referred as HWNet v2) which learns discriminative features with variable sized word images, and (iii) realistic augmentation of training data with multiple scales and elastic distortion which mimics the natural process of handwriting. We further investigate the process of fine-tuning at various layers to reduce the domain gap between synthetic and real domain and also analyze the in-variances learned at different layers using recent visualization techniques proposed in literature. Our representation leads to state of the art word spotting performance on standard handwritten datasets and historical manuscripts in different languages with minimal representation size. On the challenging IAM dataset, our method is first to report an mAP above 0.90 for word spotting with a representation size of just 32 dimensions. Further more, we also present results on printed document datasets in English and Indic scripts which validates the generic nature of the proposed framework for learning word image representation.